
The Battle Against Bots: How to Protect Your AI App (Sponsored)

Modern bots are smarter than ever. They execute JavaScript, store cookies, rotate IPs, and even solve CAPTCHAs with AI. As attacks grow more sophisticated, traditional detection methods can’t reliably keep them out.
Enter WorkOS Radar, your all-in-one bot defense solution. With a single API, you can instantly secure your signup flow against brute force attacks, leaked credentials, disposable emails, and fake signups. Radar uses advanced device fingerprinting to stop bots in their tracks and keep real users flowing through.
Fast to implement and built to scale.
This week’s system design refresher:
APIs Explained in 6 Minutes! (Youtube video)
12 MCP Servers You Can Use in 2025
How to Deploy Services
The System Design Topic Map
How Transformers Architecture Works?
We’re Hiring at ByteByteGo
SPONSOR US
APIs Explained in 6 Minutes!
12 MCP Servers You Can Use in 2025

MCP (Model Context Protocol) is an open standard that simplifies how AI models, particularly LLMs, interact with external data sources, tools, and services. An MCP server acts as a bridge between these AI models and external tools. Here are the top MCP servers:
File System MCP Server
Allows the LLM to directly access the local file system to read, write, and create directories.
GitHub MCP Server
Connects Claude to GitHub repos and allows file updates, code searching.
Slack MCP Server
MCP Server for Slack API, enabling Claude to interact with Slack workspaces.
Google Maps MCP Server
MCP Server for Google Maps API.
Docker MCP Server
Integrate with Docker to manage containers, images, volumes, and networks.
Brave MCP Server
Web and local search using Brave’s Search API.
PostgreSQL MCP Server
An MCP server that enables LLM to inspect database schemas and execute read-only queries.
Google Drive MCP Server
An MCP server that integrates with Google Drive to allow reading and searching over files.
Redis MCP Server
MCP Server that provides access to Redis databases.
Notion MCP Server
This project implements an MCP server for the Notion API.
Stripe MCP Server
MCP Server to interact with the Stripe API.
Perplexity MCP Server
An MCP Server that connects to Perplexity’s Sonar API for real-time search.
Over to you: Which other MCP Server will you add to the list?
Guide to AI Assisted Engineering (Sponsored)

The zero-to-one guide for teams adopting AI coding assistants. This guide shares proven prompting techniques, the use cases that save the most time for developers, and leadership strategies for encouraging adoption. It’s designed to be something engineering leaders can distribute internally to help teams get started with integrating AI into their daily work.
Download this guide to get:
The 10 most time-saving use cases for AI coding tools
Effective AI prompting techniques from experienced AI users
Leadership strategies for encouraging AI use
How to Deploy Services
Deploying or upgrading services is risky. In this post, we explore risk mitigation strategies.
The diagram below illustrates the common ones.
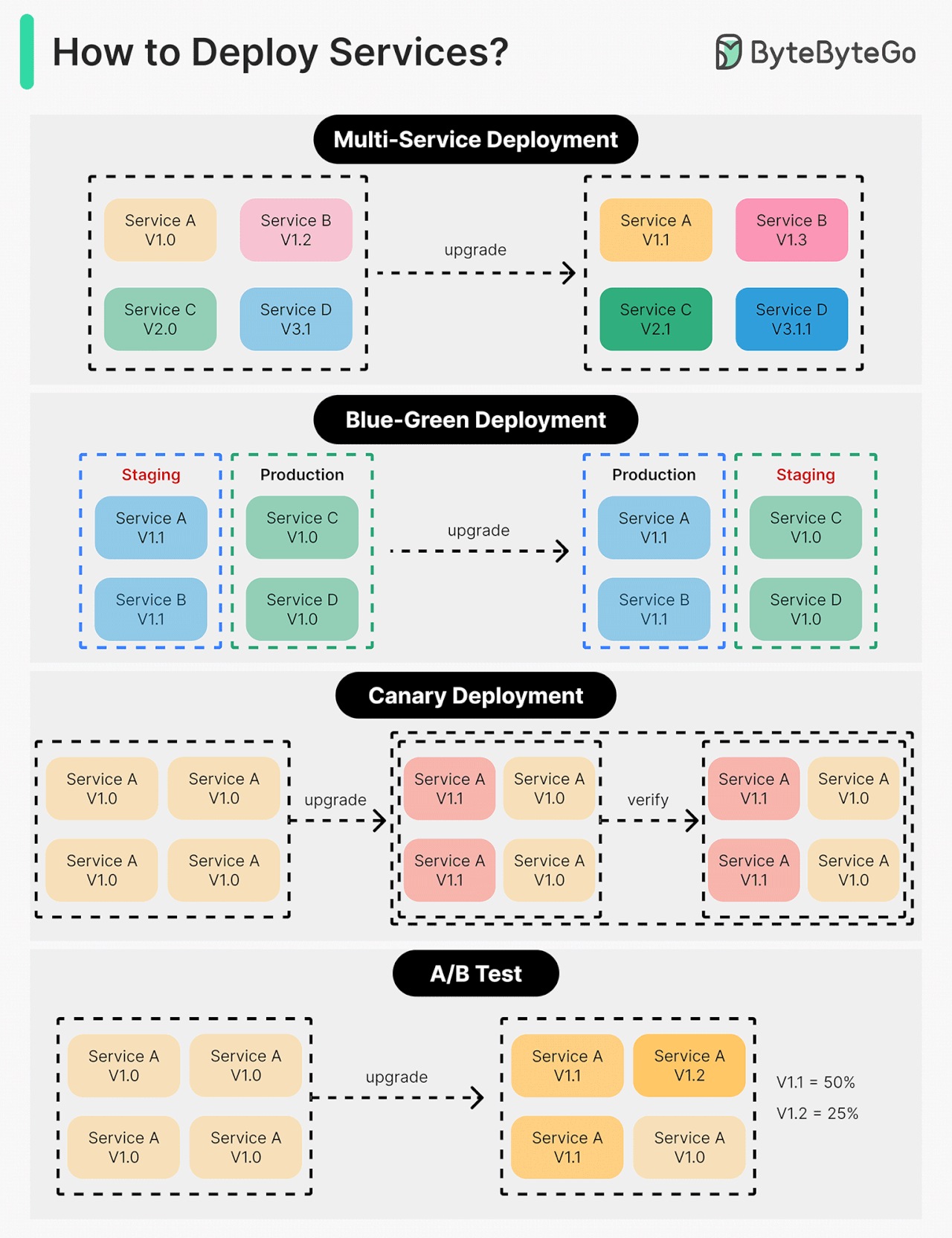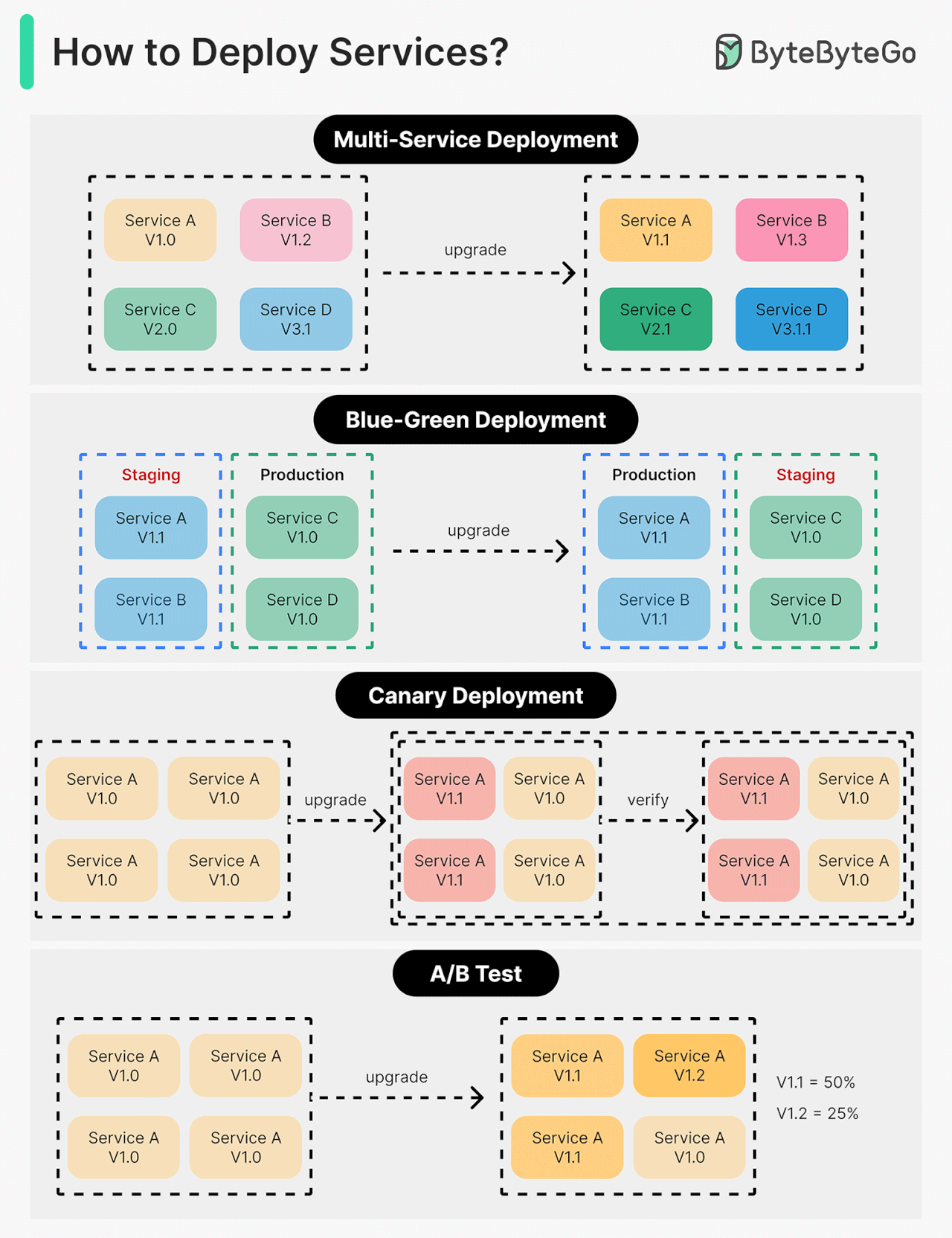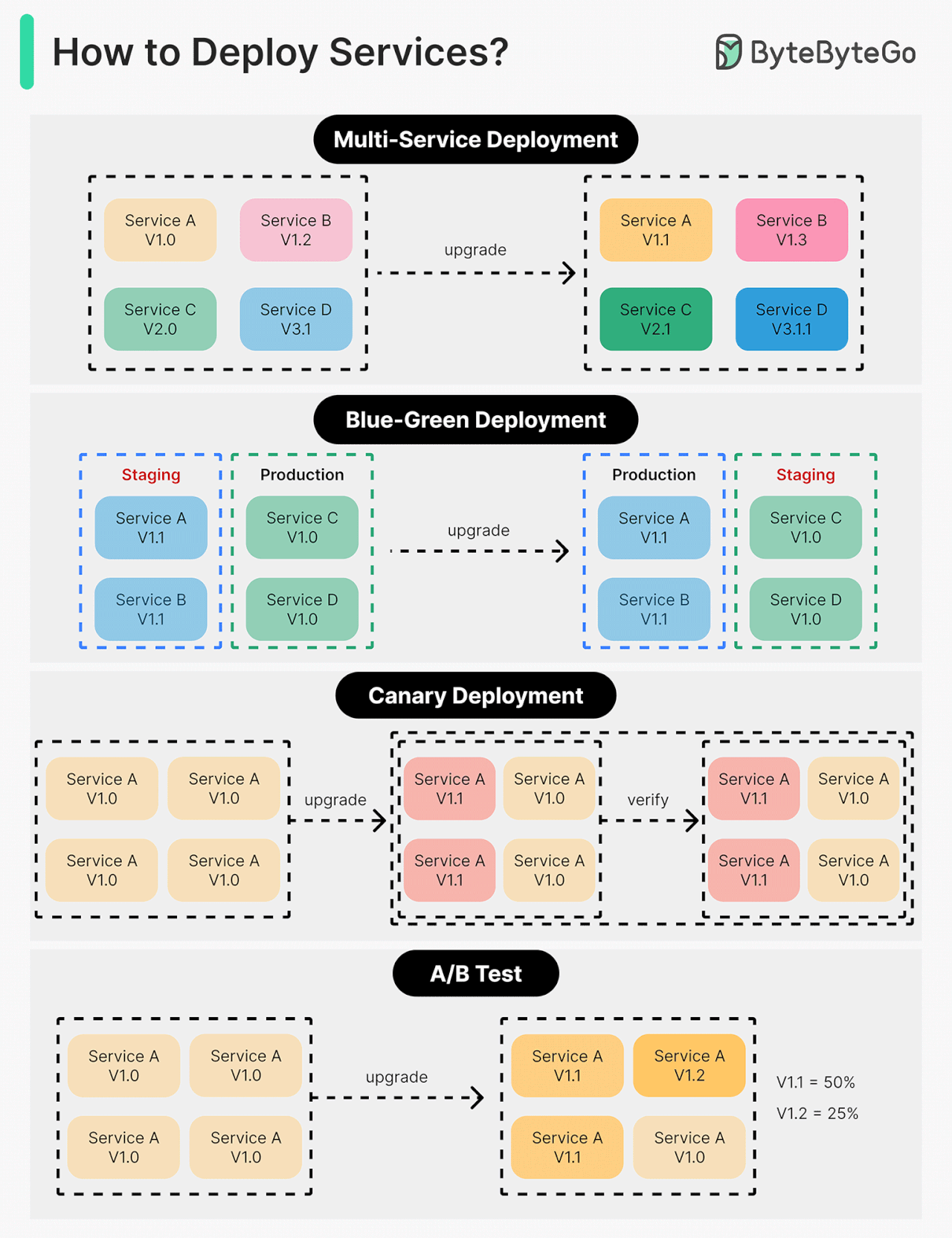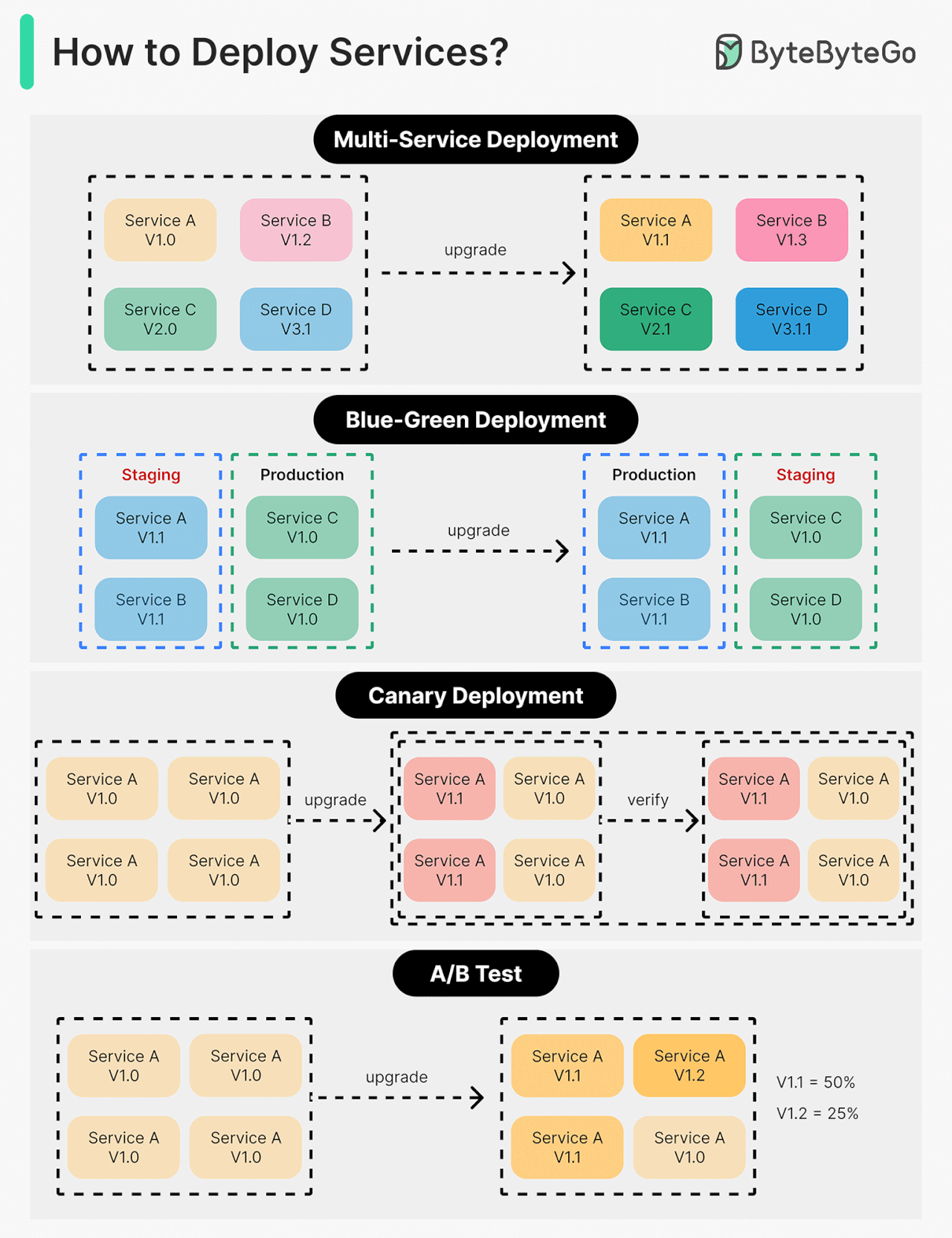
Multi-Service Deployment
In this model, we deploy new changes to multiple services simultaneously. This approach is easy to implement. But since all the services are upgraded at the same time, it is hard to manage and test dependencies. It’s also hard to rollback safely.
Blue-Green Deployment
With blue-green deployment, we have two identical environments: one is staging (blue) and the other is production (green). The staging environment is one version ahead of production. Once testing is done in the staging environment, user traffic is switched to the staging environment, and the staging becomes the production. This deployment strategy is simple to perform rollback, but having two identical production quality environments could be expensive.
Canary Deployment
A canary deployment upgrades services gradually, each time to a subset of users. It is cheaper than blue-green deployment and easy to perform rollback. However, since there is no staging environment, we have to test on production. This process is more complicated because we need to monitor the canary while gradually migrating more and more users away from the old version.
A/B Test
In the A/B test, different versions of services run in production simultaneously. Each version runs an “experiment” for a subset of users. A/B test is a cheap method to test new features in production. We need to control the deployment process in case some features are pushed to users by accident.
Over to you - Which deployment strategy have you used? Did you witness any deployment-related outages in production and why did they happen?
The System Design Topic Map
Effective system design is a game of trade-offs and requires a broad knowledge base to make the best decisions. This topic map categorizes the essential system design topics based on categories.
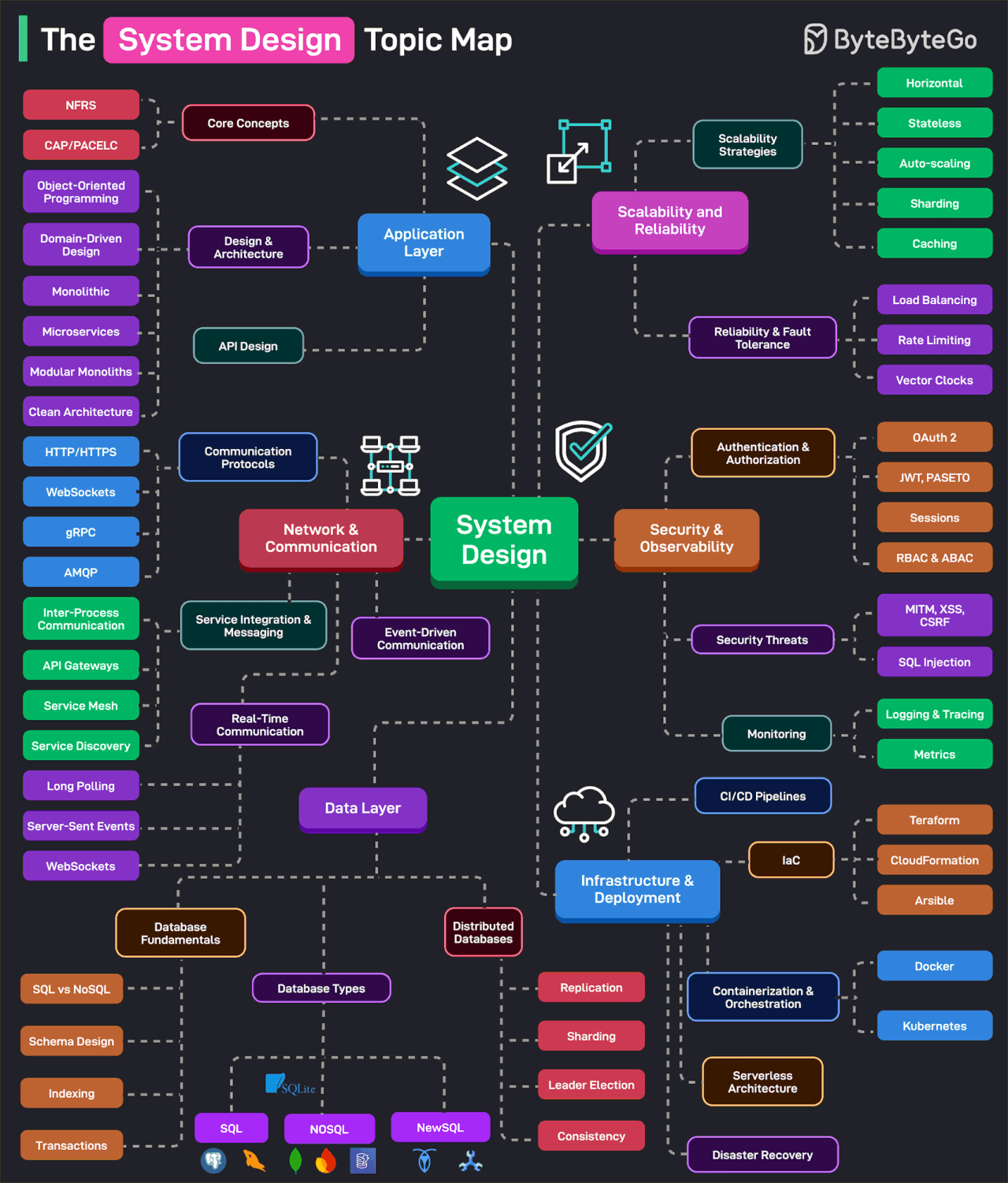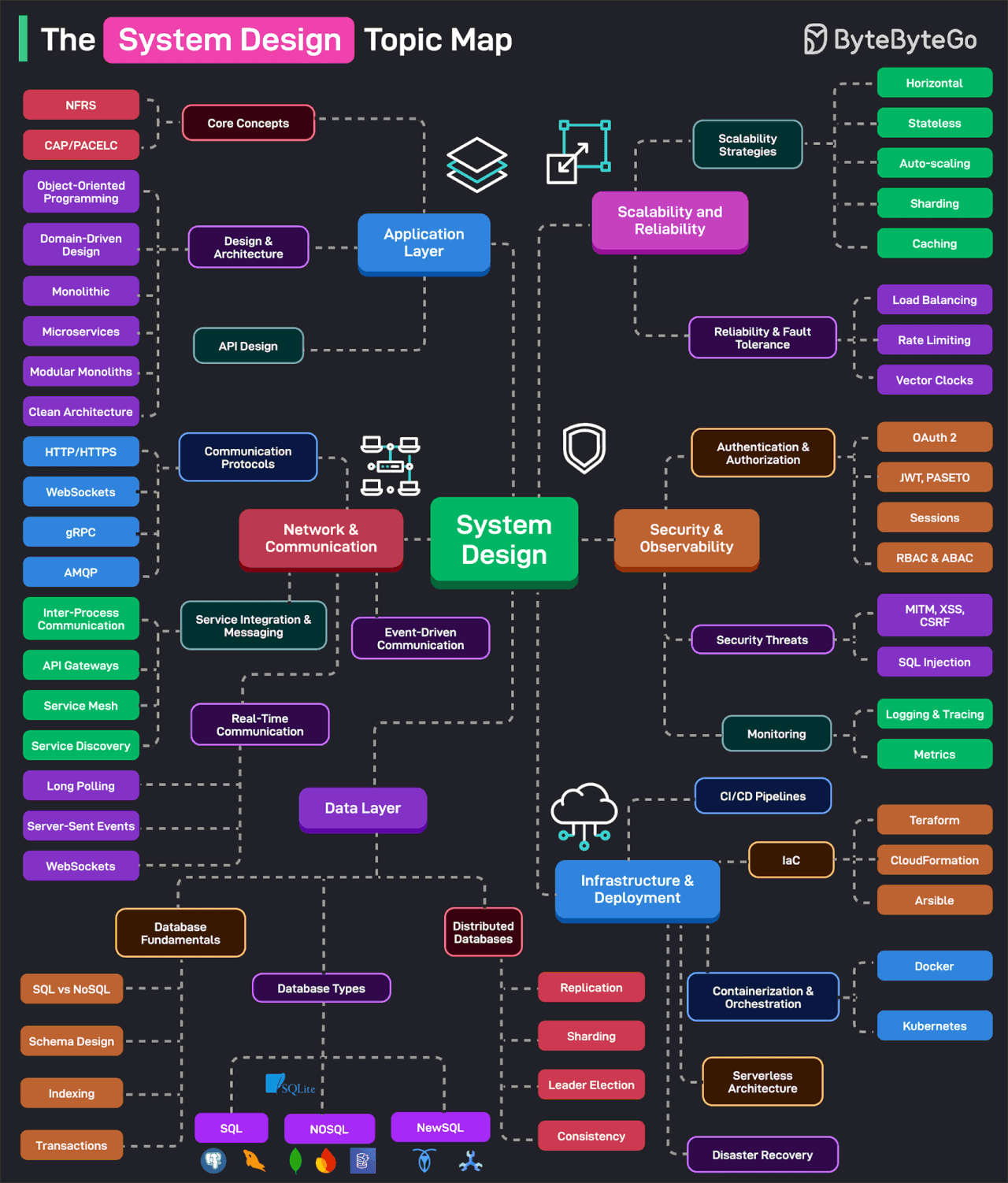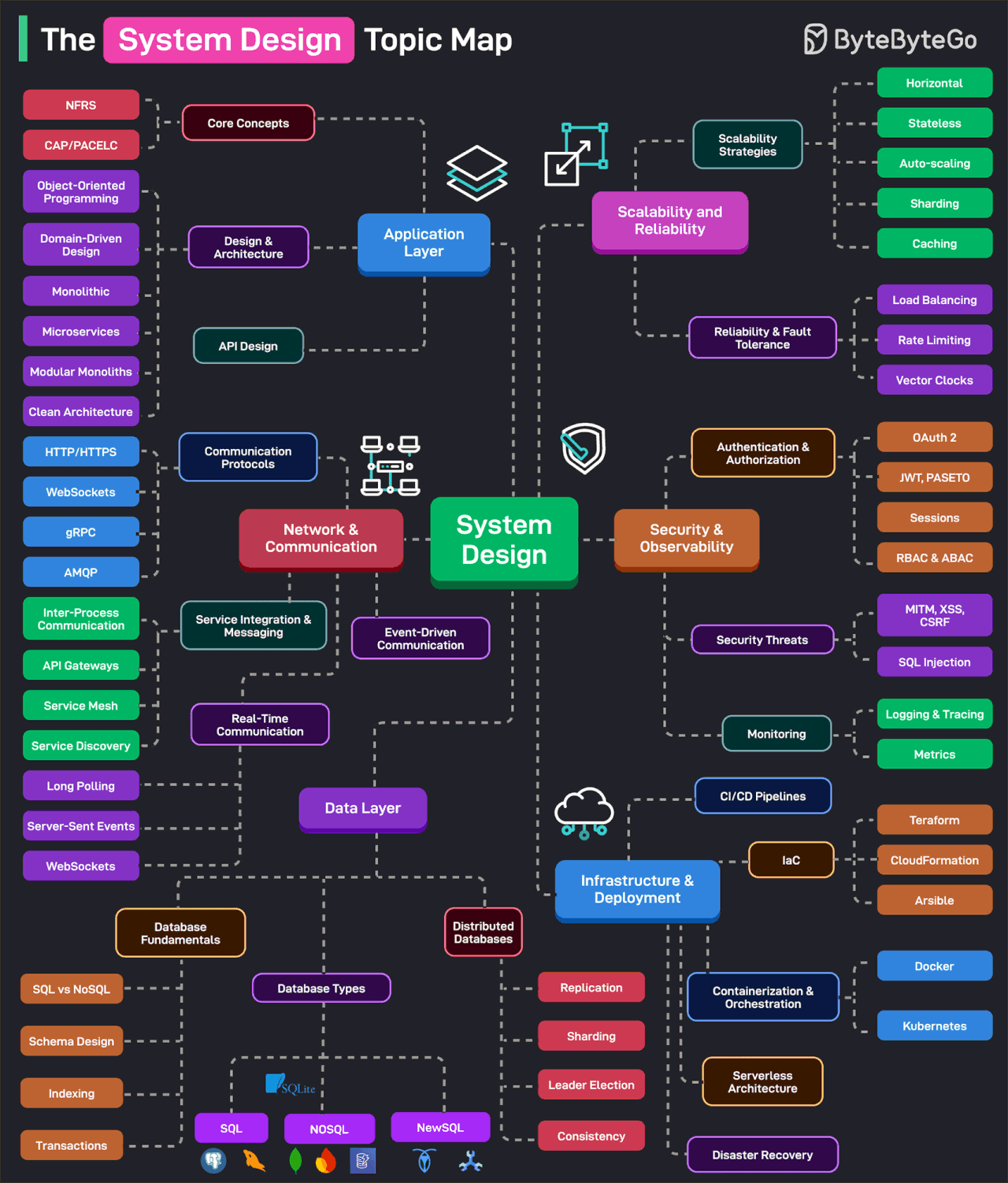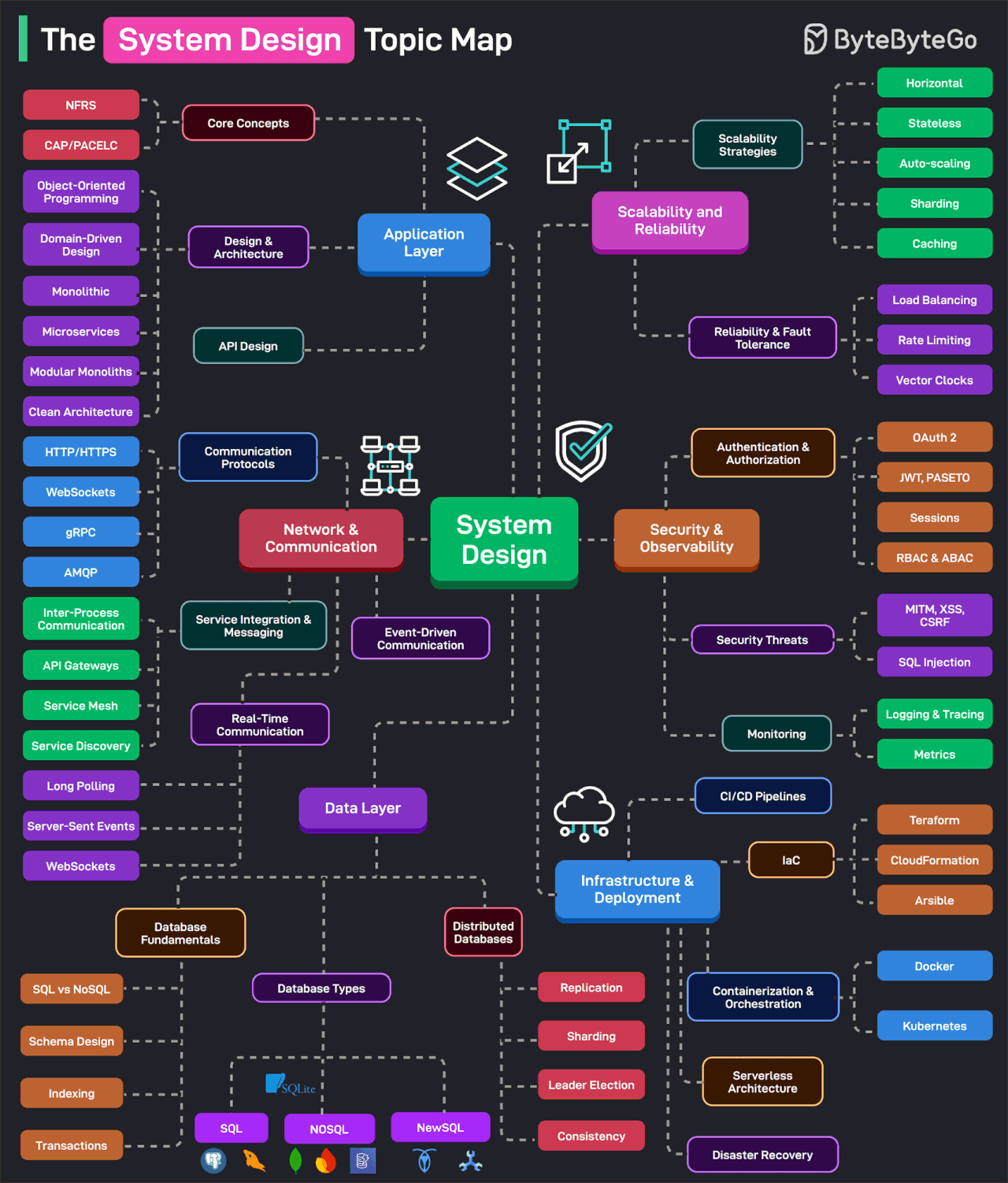
Application Layer: It consists of the core concepts such as availability, scalability, reliability, and other NFRs. Also covers design and architectural topics such as OOP, DDD, Microservices, Clean Architecture, Modular Monoliths, and so on.
Network & Communication: It covers communication protocols, service integration, messaging, real-time communication, and event-driven architecture.
Data Layer: It covers the basics of database systems (schema design, indexing, SQL vs NoSQL, transactions, etc), the various types of databases, and the nuances of distributed databases (replication, sharding, leader election, etc.)
Scalability & Reliability: This covers scalability strategies (horizontal, stateless, caching, partitioning, etc) and reliability strategies like load balancing, rate limiting, and so on.
Security & Observability: It covers authentication and authorization techniques (OAuth 2, JWT, PASETO, Sessions, Cookies, RBAC, etc.) and security threats. The observability area deals with topics like monitoring, tracing, and logging.
Infrastructure & Deployments: Deals with CI/CD pipelines, containerization and orchestration, serverless architecture, IaC, and disaster recovery techniques.
Over to you: What else will you add to the list?
How Transformers Architecture Works?
Transformers Architecture has become the foundation of some of the most popular LLMs including GPT, Gemini, Claude, DeepSeek, and Llama.
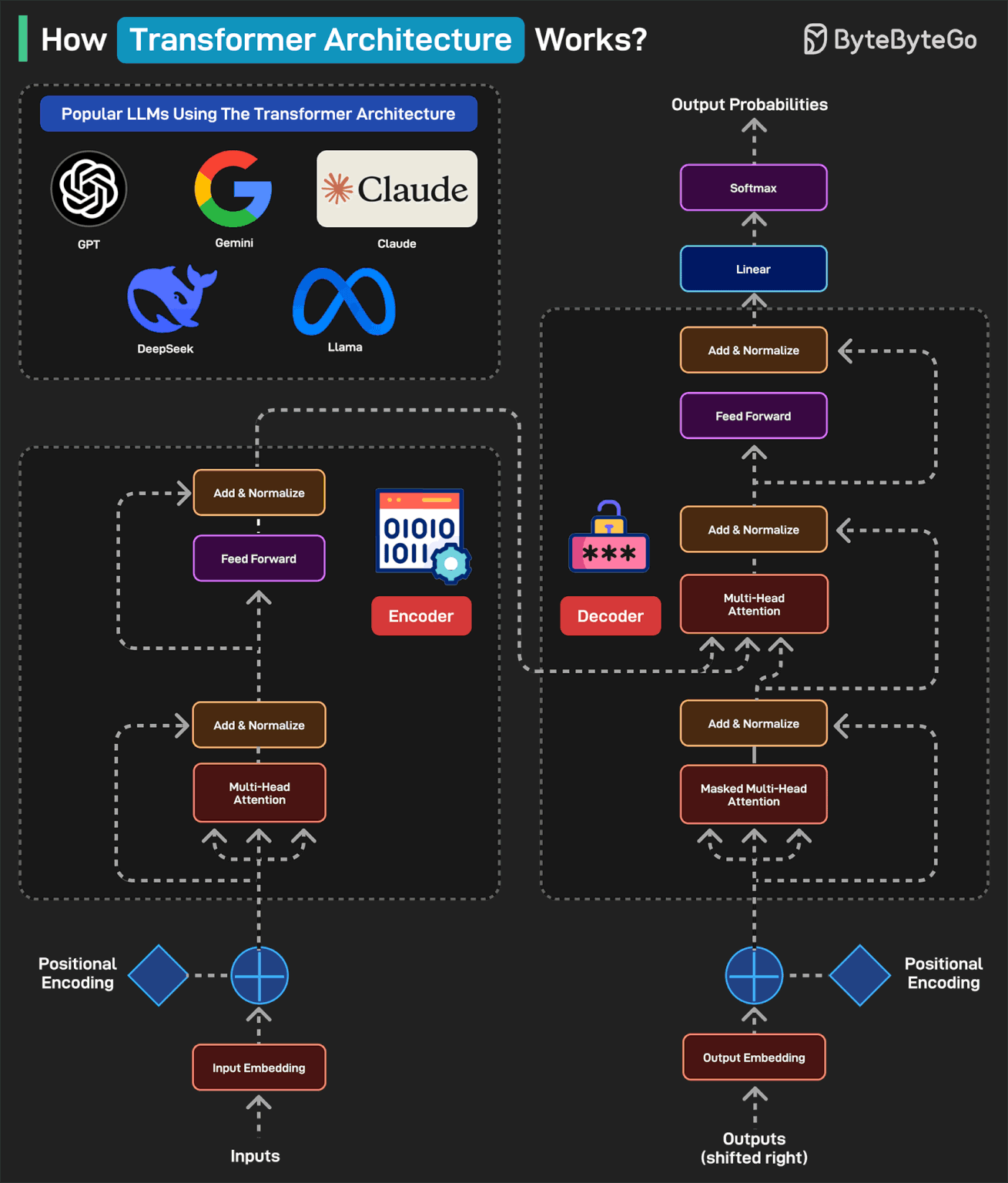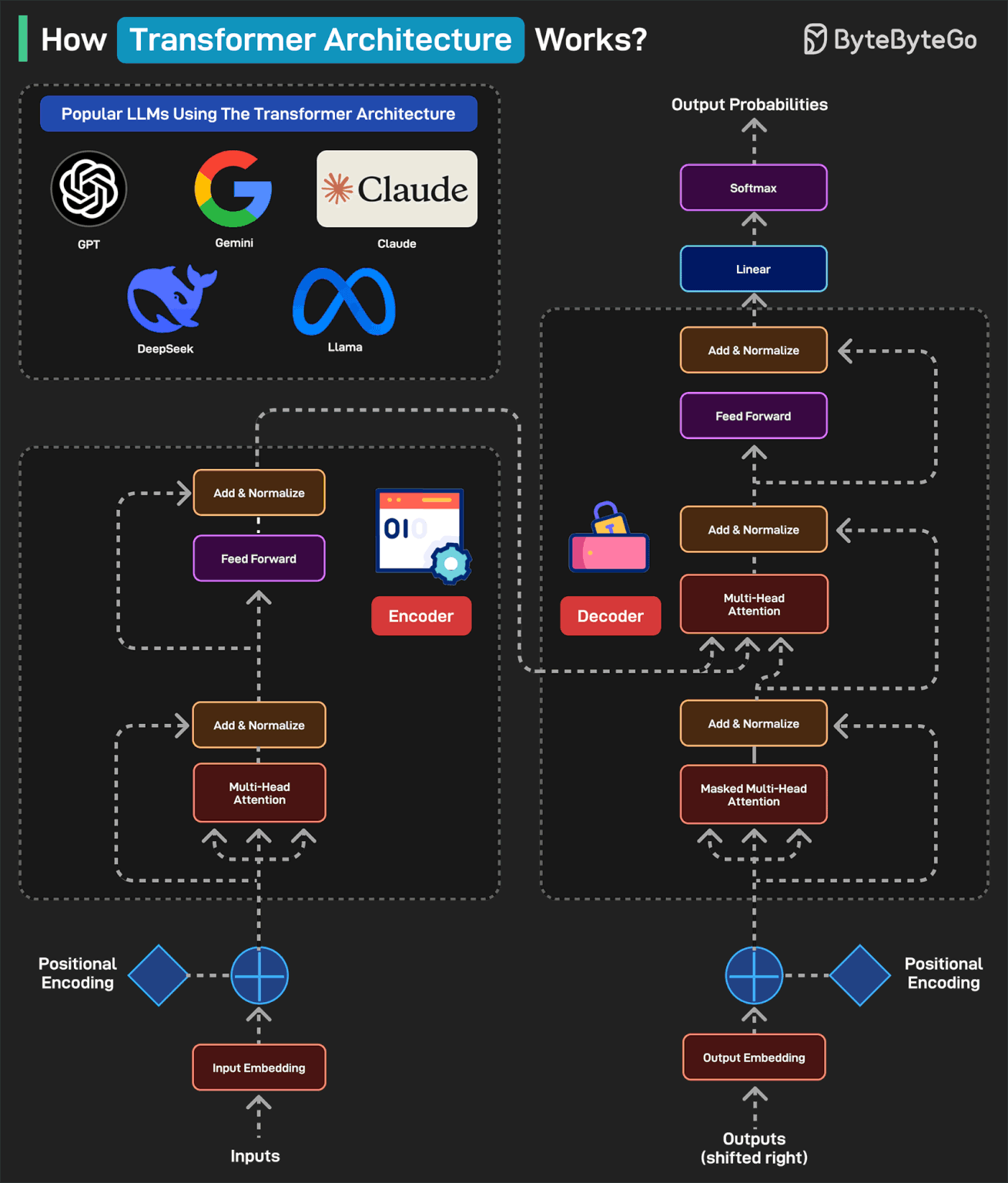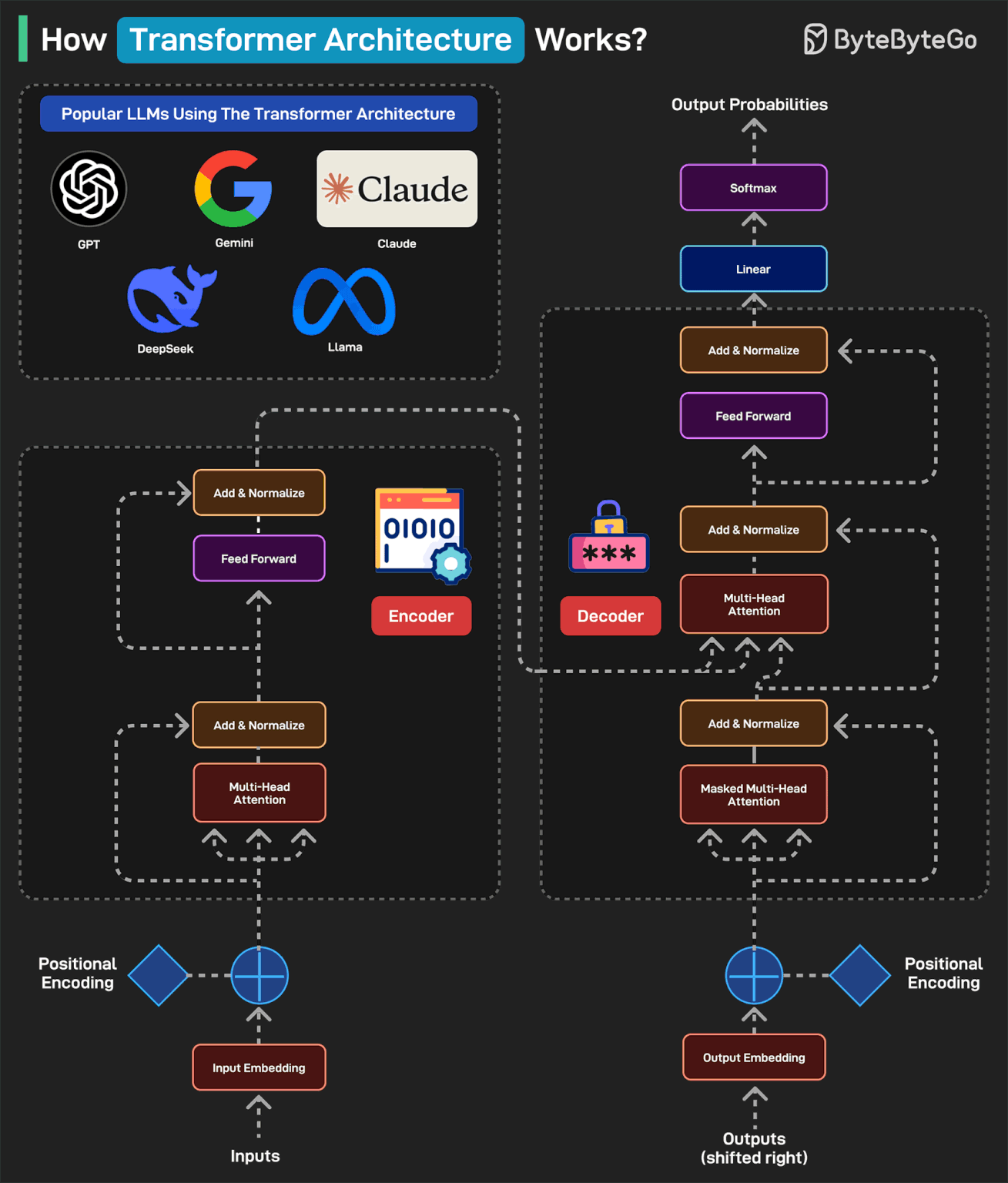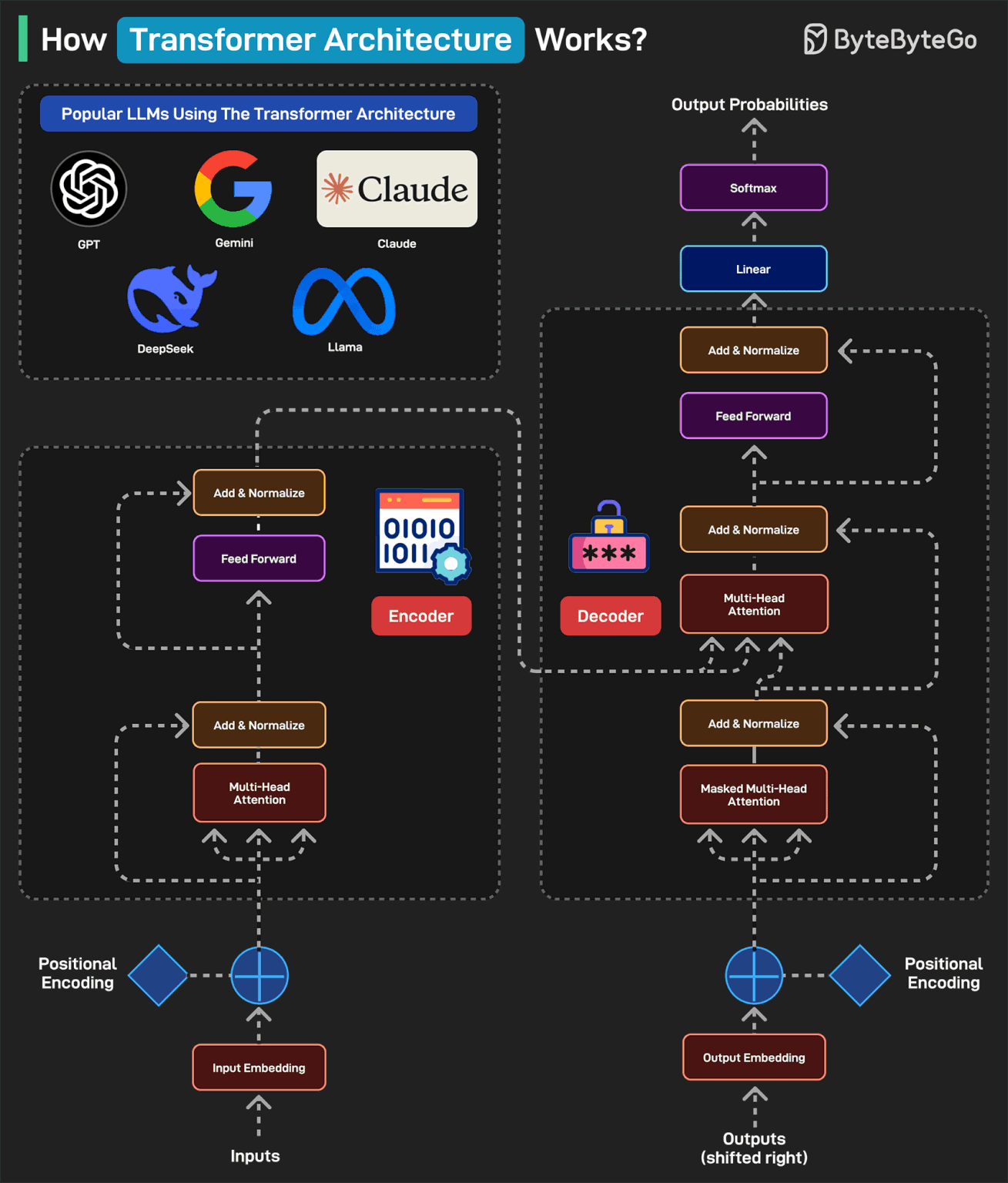
Here’s how it works:
A typical transformer-based model has two main parts: encoder and decoder. The encoder reads and understands the input. The decoder uses this understanding to generate the correct output.
In the first step (Input Embedding), each word is converted into a number (vector) representing its meaning.
Next, a pattern called Positional Encoding tells the model where each word is in the sentence. This is because the word order matters in a sentence. For example “the cat ate the fish” is different from “the fish ate the cat”.
Next is the Multi-Head Attention, which is the brain of the encoder. It allows the model to look at all words at once and determine which words are related. In the Add & Normalize phase, the model adds what it learned from attention back into the sentence.
The Feed Forward process adds extra depth to the understanding. The overall process is repeated multiple times so that the model can deeply understand the sentence.
After the encoder finishes, the decoder kicks into action. The output embedding converts each word in the expected output into numbers. To understand where each word should go, we add Positional Encoding.
The Masked Multi-Head Attention hides the future words so the model predicts only one word at a time.
The Multi-Head Attention phase aligns the right parts of the input with the right parts of the output. The decoder looks at both the input sentence and the words it has generated so far.
The Feed Forward applies more processing to make the final word choice better. The process is repeated several times to refine the results.
Once the decoder has predicted numbers for each word, it passes them through a Linear Layer to prepare for output. This layer maps the decoder’s output to a large set of possible words.
After the Linear Layer generates scores for each word, the Softmax layer converts those scores into probabilities. The word with the highest probability is chosen as the next word.
Finally, a human-readable sentence is generated.
Over to you: What else will you add to understand the Transformer Architecture?
We’re Hiring at ByteByteGo
We're hiring 3 positions at ByteByeGo: Technical Product Manager, Technical Educator – System Design, and Sales/Partnership.
𝐏𝐫𝐨𝐝𝐮𝐜𝐭 𝐌𝐚𝐧𝐚𝐠𝐞𝐫 – 𝐓𝐞𝐜𝐡𝐧𝐢𝐜𝐚𝐥 (Remote, part-time)
We’re hiring a technical product manager to work with me on building an interview preparation platform. Think mock interviews, live coaching, AI assisted learning and hands-on tools that help engineers land their next role.
You’ll be responsible for defining the product strategy, prioritizing features, and working closely with me to bring ideas to life.
You must have conducted 100+ technical interviews (e.g., system design, algorithms, behavioral) and have a deep understanding of what makes a great candidate experience. Bonus if you’ve worked at a top tech company or have experience coaching candidates.
We’re looking for someone who can:
• Build from 0 to 1 with minimal guidance
• Translate user pain points into well-scoped solutions
• Iterate quickly based on feedback and data
𝐓𝐞𝐜𝐡𝐧𝐢𝐜𝐚𝐥 𝐄𝐝𝐮𝐜𝐚𝐭𝐨𝐫 – 𝐒𝐲𝐬𝐭𝐞𝐦 𝐃𝐞𝐬𝐢𝐠𝐧 (Remote, part-time)
We’re hiring a system design technical educator to help deepen our educational library. This role is perfect for someone who loves explaining complex engineering topics clearly, whether through long-form articles, diagrams, or short-form posts.
You’ll collaborate with the team to write newsletters, coauthor chapters of books and guides, and create engaging visual content around system design, architecture patterns, scalability, and more. If you’ve written for blogs, docs, newsletters, or taught online, we’d love to see your work.
𝐒𝐚𝐥𝐞𝐬/𝐏𝐚𝐫𝐭𝐧𝐞𝐫𝐬𝐡𝐢𝐩 (US/Canada based remote role, part-time/full-time)
We’re looking for a sales and partnerships specialist who will help grow our newsletter sponsorship business. This role will focus on securing new advertisers, nurturing existing relationships, and optimizing revenue opportunities across our newsletter and other media formats.
How to Apply: send your resume and a short note on why you’re excited about this role to jobs@bytebytego.com
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing hi@bytebytego.com.
