
空间音频,作为一种能够模拟真实听觉环境的技术,正逐渐成为提升沉浸式体验的关键。
然而,现有的技术大多基于固定的视角视频,缺乏对360°全景视频中空间信息的充分利用。
在这样的背景下,一项在空间音频生成领域具有里程碑意义的研究应运而生——OmniAudio:它能够直接从360°视频生成空间音频,为虚拟现实和沉浸式娱乐带来了全新的可能性。
相关代码和数据集已开源:
https://github.com/liuhuadai/OmniAudio
为何需要从360°视频生成空间音频?
传统的视频到音频生成技术主要关注于生成非空间音频,比如手机外放或者耳机里的声音,这些音频缺乏方向信息,无法满足沉浸式体验对3D声音定位的需求。
所以看VR电影或者玩动作游戏的时候,总会觉得少了些代入感。
随着360°摄像头的普及和虚拟现实技术的发展,如何利用全景视频生成与之匹配的空间音频,就成为了一个亟待解决的问题。

为应对这些挑战,OmniAudio的研究团队提出了360V2SA(360-degree Video to Spatial Audio)任务,旨在直接从360°视频生成FOA(First-order Ambisonics)音频。
FOA是一种标准的3D空间音频格式,使用四个通道来表示声音,包含声音的方向信息,可实现真实的3D音频再现。
与传统的立体声相比,FOA音频在头部旋转时也能够保持声音定位的准确性。

Sphere360:第一个大规模360V2SA数据集
数据是机器学习模型的基石,然而,现有的配对360°视频和空间音频数据极为稀缺。
为此,OmniAudio团队设计了一个高效的半自动化pipeline,用于构建Sphere360数据集:
首先,通过关键字在YouTube上爬取包含FOA音频和360°视频的候选素材,应用技术过滤器剔除不符合条件的视频,并采用频道为单位进行聚合式爬取。
然后,人工审核补充剩余视频。
在清洗环节,针对视频静态、音频静音、过多语音内容以及视音频不匹配等问题设计了具体检测算法,确保高质量对齐。
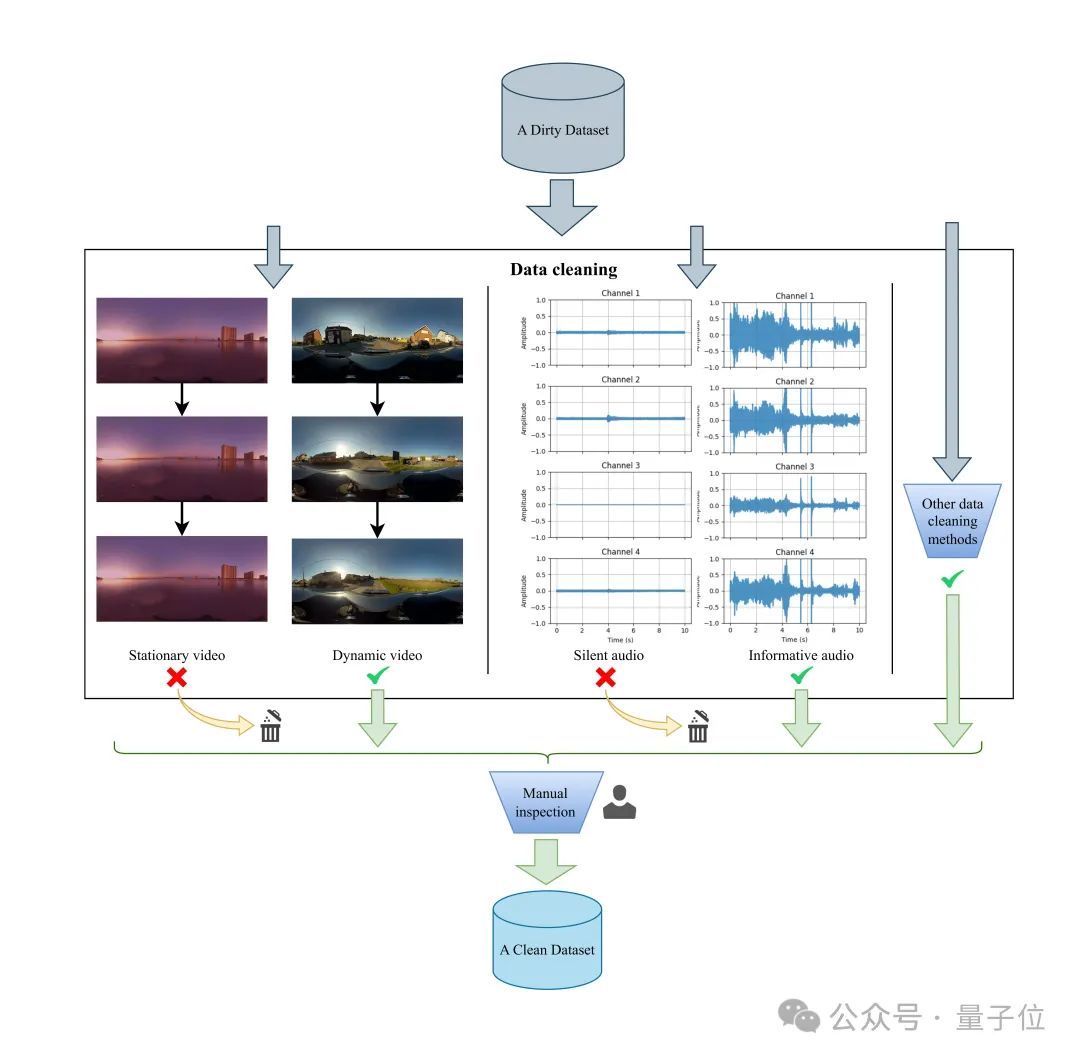
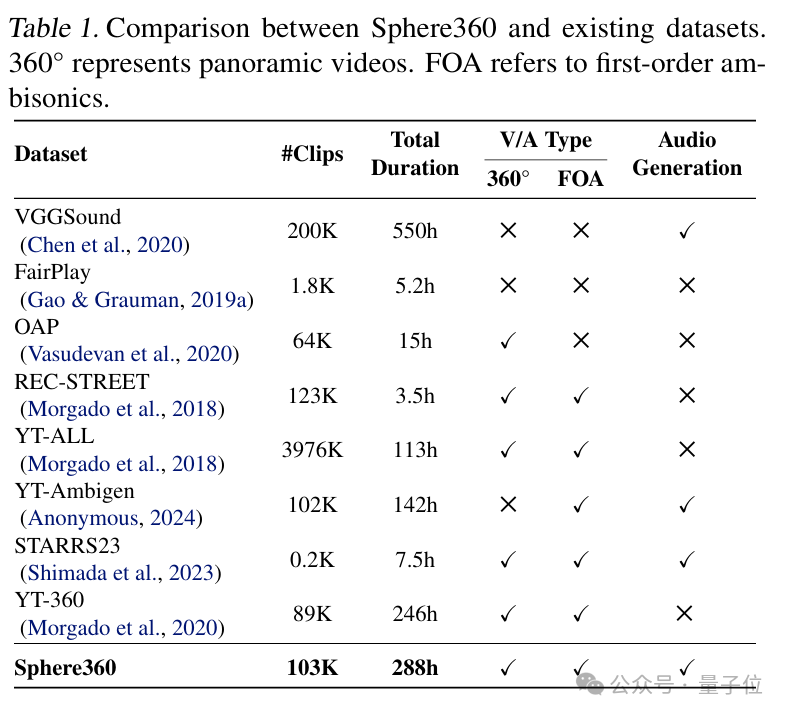
Sphere360数据集是一个包含超过103,000个真实世界视频片段的数据宝库,涵盖288种音频事件,总时长达到288小时。收集到的视频既包含 360° 视觉内容,又支持FOA音频,并具有高质量和高可用性。
与其他现有数据集相比,Sphere360在规模和适用性上均存在显著优势。
OmniAudio:创新技术实现空间音频生成
OmniAudio的训练方法可分为两个阶段:自监督的coarse-to-fine流匹配预训练,以及基于双分支视频表示的有监督微调。
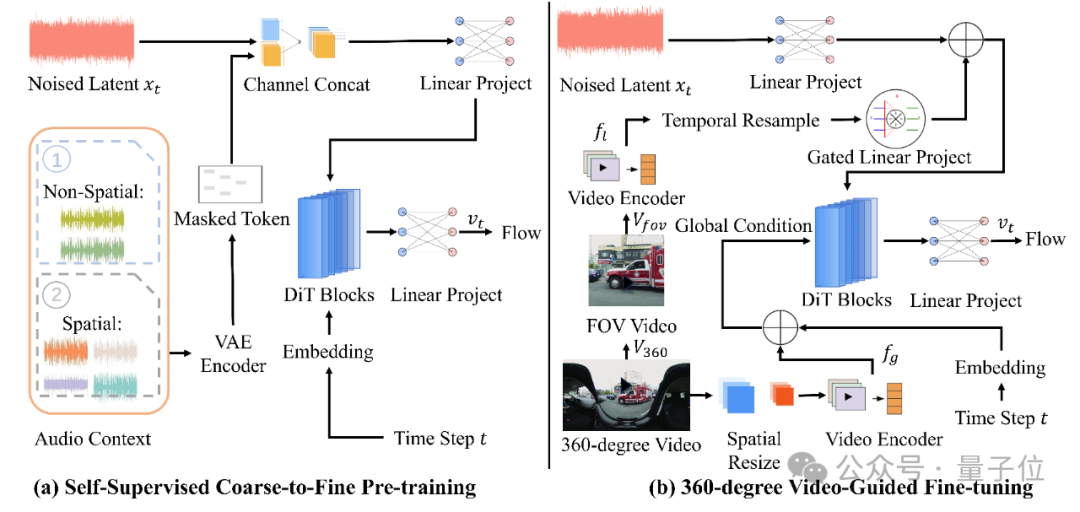
简单地说,在预训练阶段,先用普通立体声音频转换为“伪FOA”格式训练模型,同时通过自监督的掩码预测方法,让模型学会音频的基本结构和时间规律;再使用真实FOA精细训练,提高掩码概率,让模型能够更好地理解声音的空间信息。
相比起直接训练,这种“先普通音频,再空间音频”的两步法显著改善了模型对空间特征的泛化能力与生成质量。
在完成自预训练后,OmniAudio团队将模型与双分支视频编码器结合,同时提取视频的全局特征和局部视角,进行有监督微调,以达成模型可根据360° 视频生成高保真、方向准确的空间音频的效果。
详细方法可见文末项目链接。
成果与展望
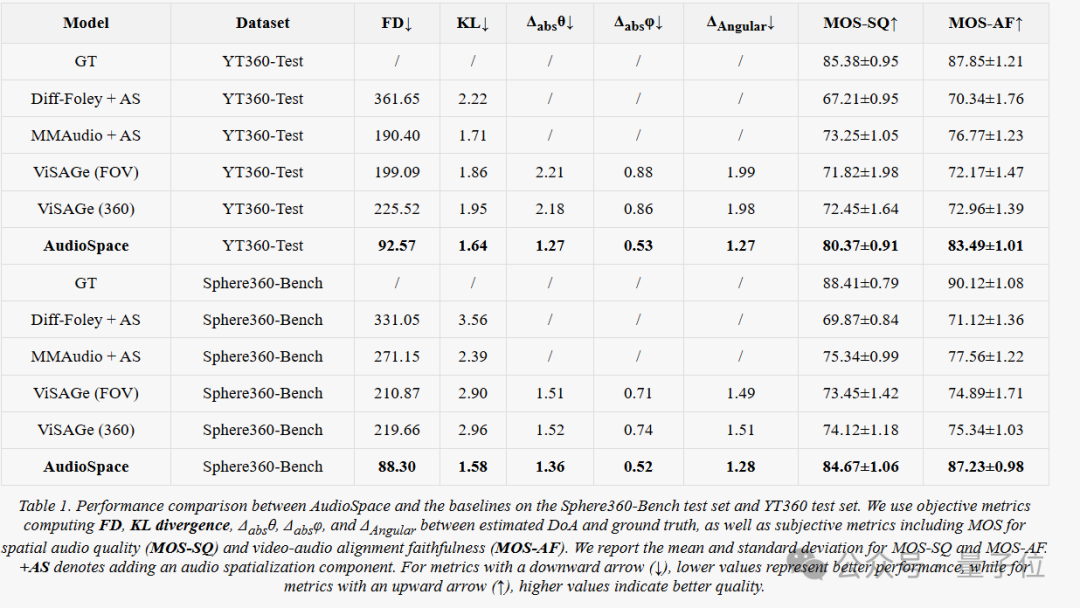
OmniAudio团队在Sphere360-Bench,以及来自YT-360的外部分布测试集YT360-Test上进行有监督微调与评估。
主要结果显示,OmniAudio在两套测试集上均显著优于所有基线。
但OmniAudio也有一定的局限性:例如,面对包含大量发声物体的复杂场景时,模型在事件类型识别上仍存在挑战。
OmniAudio的研究团队表示,未来的工作将探索更好地理解多目标360° 视频的技术,并通过持续收集和扩充数据集,进一步推进该领域的发展。
项目主页: https://omniaudio-360v2sa.github.io/
开源仓库:https://github.com/liuhuadai/OmniAudio
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
学术投稿请于工作日发邮件到:
ai@qbitai.com
标题注明【投稿】,告诉我们:
你是谁,从哪来,投稿内容
附上论文/项目主页链接,以及联系方式哦
我们会(尽量)及时回复你

🌟 点亮星标 🌟
内容中包含的图片若涉及版权问题,请及时与我们联系删除
