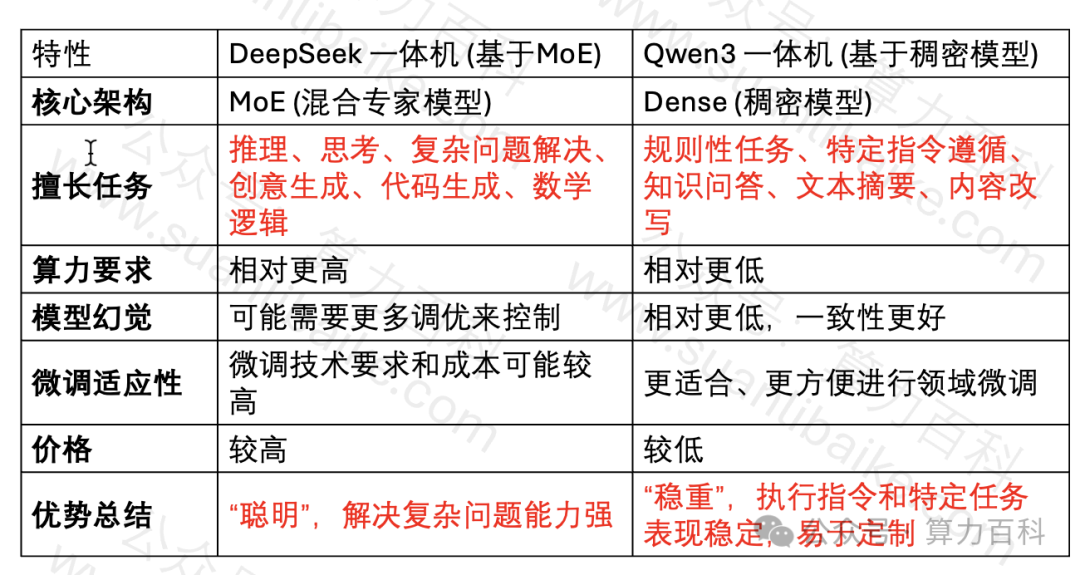
本文对比了DeepSeek和Qwen3一体机的核心架构差异,前者采用MoE架构,后者采用稠密模型架构。MoE架构擅长处理复杂推理和创造性任务,但需要更高算力;稠密模型在规则性任务和特定领域应用中更稳定,幻觉更少,且微调成本较低。选购时应根据具体应用场景、任务类型、对模型能力的需求以及算力预算进行综合考虑,并在条件允许的情况下进行实际测试和评估。
🧠 DeepSeek一体机采用MoE架构,通过多个专家网络和门控网络处理请求,擅长处理需要深度推理和创造性的复杂任务,如科学文献分析、报告撰写、创意文本生成和代码辅助开发。但MoE架构对推理算力需求更高,一体机需配备更强的硬件支持。
📊 Qwen3一体机采用稠密模型架构,所有参数协同工作,擅长执行规则明确、一致性要求高的任务,如构建客服机器人、信息抽取、标准化文档生成和内容审核。稠密模型幻觉更少,微调成本和难度相对较低,对算力要求也更为经济。
💡 选择一体机时,需根据核心需求进行选择。若核心需求是处理高度复杂、需要深度推理和创造性的任务,推荐选择DeepSeek一体机;若核心需求是执行规则明确、一致性要求高、或需要针对特定领域进行深度微调的任务,推荐选择Qwen3一体机。
💰 对算力预算和运维有严格要求的场景,推荐优先考虑Qwen3一体机,其较低的推理算力需求和更成熟的微调生态可能更具优势。而对模型“智商”上限有极高追求,且预算充足的场景,推荐深入评估DeepSeek一体机。
原创 算力百科 J 2025-05-09 06:00 贵州
deepseek会更多卷2C市场,2C市场一定是Moe的天下;Qwen一定是卷2B/2G市场,帮助保住阿里云市场份额是Qwen的使命和责任,所以Qwen一定dense模型为重点发展对象,两个团的的使命不同,发力点也不同,最终技术选择也不同。

先说结论:deepseek会更多卷2C市场,2C市场一定是Moe的天下;Qwen一定是卷2B/2G市场,帮助保住阿里云市场份额是Qwen的使命和责任,所以Qwen一定dense模型为重点发展对象,两个团的的使命不同,发力点也不同,最终技术选择也不同。 当然互联网公司都有2C业务都会做moe,这里强调的是发力点。
随着大语言模型(LLM)技术的飞速发展,市场上涌现出众多优秀的模型及基于它们打造的软硬件一体化解决方案——“一体机”。这些一体机旨在降低企业和开发者部署与应用大模型的门槛。其中,DeepSeek系列和最近的Qwen3系列备受关注。
当我们需要在DeepSeek一体机和最新的Qwen3一体机之间做出选择时,理解它们核心架构的差异至关重要。
我们重点探讨DeepSeek的MoE(Mixture of Experts,混合专家)架构与Qwen3的稠密(Dense)模型架构在一体机选型中的影响。(qwen也有moe ,我们不做讨论)
核心架构差异:MoE vs. 稠密模型
DeepSeek 的 MoE (Mixture of Experts) 架构
更高的推理算力需求虽然每次推理只激活部分专家,但管理和调度这些专家,以及专家本身的计算,尤其是在复杂查询下可能激活多个专家时,对计算资源(如GPU显存和计算单元)的要求通常更高。一体机需要配备更强的硬件来支撑其高效运行。训练和微调的复杂性MoE模型的训练和微调相对复杂,需要更精细的策略来平衡专家负载和门控机制的优化。
强大的推理和思考能力由于每个专家可以专注于解决特定类型的问题或学习特定领域的知识,MoE模型在处理复杂、需要深度思考和多方面推理的任务时,往往表现更出色。它可以被视为一个“专家团队”,能够针对性地调动资源。参数规模效益MoE允许模型在保持(甚至降低)每次推理计算量的同时,显著增加总参数量,从而提升模型的整体“知识容量”和能力上限。
工作原理MoE模型并非一个单一的、巨大的神经网络,而是由多个相对较小的“专家网络”(Experts)和一个“门控网络”(Gating Network)组成。当输入一个请求时,门控网络会判断哪些专家最适合处理这个请求,然后将任务动态地分配给一个或少数几个选定的专家。这意味着在推理过程中,并非模型的所有参数都会被激活和使用。
Qwen3 的稠密 (Dense) 模型架构
能力上限与参数规模强相关要提升稠密模型的能力,通常需要直接增加其参数总量,这会导致训练和推理成本的同步上升。
规则性和一致性对于那些遵循特定规则、模式较为固定的任务(如格式转换、特定指令遵循、标准化问答等),稠密模型往往能提供更稳定和一致的输出。更低的幻觉由于所有参数协同工作,稠密模型在良好训练下,其输出可能更“收敛”,产生不符合事实的“幻觉”的概率相对较低。微调友好稠密模型的结构相对简单直接,进行领域适应性微调(Fine-tuning)时,更容易获得理想的效果,也更容易控制微调过程。相对较低的推理算力需求:在相似“有效参数”(指实际参与单次计算的参数)规模下,稠密模型的推理过程通常更直接,对算力的瞬时需求和调度复杂度低于MoE模型。
工作原理稠密模型是我们传统意义上理解的神经网络。在推理过程中,输入数据会流经网络中的所有参数(或绝大部分参数)。模型的所有“知识”都编码在整个参数矩阵中。
DeepSeek一体机 vs. Qwen3一体机:我们可以针对具体需求来选择合适的一体机:
选择大模型一体机的时候别瞎选!看你的任务偏向哪一类,然后再选择,别冲动!
选择一体机建议:
如果你的核心需求是处理高度复杂、需要深度推理和创造性的任务:
例如:进行科学文献分析、辅助撰写包含复杂逻辑的报告、生成多样化的创意文本、解决开放式问题、进行复杂的代码辅助开发等。推荐选择:DeepSeek一体机。 其MoE架构带来的“思考深度”和“知识广度”可能更符合你的要求,但需要确保一体机配置的算力能够满足其需求。
如果你的核心需求是执行规则明确、一致性要求高、或需要针对特定领域进行深度微调的任务:
例如:构建客服机器人、信息抽取、标准化文档生成、特定领域的知识检索与问答、内容审核等。推荐选择:Qwen3一体机。 其稠密模型架构在这些任务上通常表现更稳定,幻觉更少,且微调的成本和难度相对较低,更容易实现特定业务场景的深度定制。同时,其对算力的要求也更为经济。
对算力预算和运维有严格要求的场景:
如果希望在有限的算力预算下获得较好的综合性能,或者对模型的稳定性和可预测性有更高要求。推荐优先考虑:Qwen3一体机。 其较低的推理算力需求和更成熟的微调生态可能更具优势。
对模型“智商”上限有极高追求,且预算充足:
如果追求模型能力的绝对上限,尤其是在解决前沿、开放性难题方面。推荐深入评估:DeepSeek一体机。
DeepSeek一体机凭借其MoE架构,在处理需要深度推理和创造性的复杂任务时表现突出,是追求模型“智力”上限的有力选择,但通常需要更强的算力支持。Qwen3一体机则以其稠密模型的稳定性、低幻觉和微调友好性,在规则性任务和特定领域应用中更具优势,且对算力资源更为友好。
最终的选择应基于您的具体应用场景、任务类型、对模型能力(推理、一致性、创造力)的侧重、以及算力预算和微调需求。
建议在做出最终决策前,如果有条件,针对自身的典型任务对两类模型或一体机进行实际测试和评估。
随着技术的不断进步,两类架构也可能相互借鉴和融合,未来的选择或许会更加多样化。

阅读原文
跳转微信打开

