
大模型竞技场的可信度,再次被锤。
最近一篇名为《排行榜幻觉》(The Leaderboard Illusion)的论文在学术圈引发关注。

它指出,如今被视为LLM领域首选排行榜的Chatbot Arena,存在诸多系统问题。比如:
大神卡帕西也站出来表示,他个人也察觉出了一些异样。
有一段时间,Claude-3.5是我觉得最好用的模型,但是在竞技场中排名很低。当时我在网上也看到了类似的反馈。

对于最新质疑,大模型竞技场官方Lmrena.ai已经给出回应:
但这不代表竞技场有偏见,排行榜反映数百万人类的个人真实偏好。
快速刷榜不符合模型进步实际情况
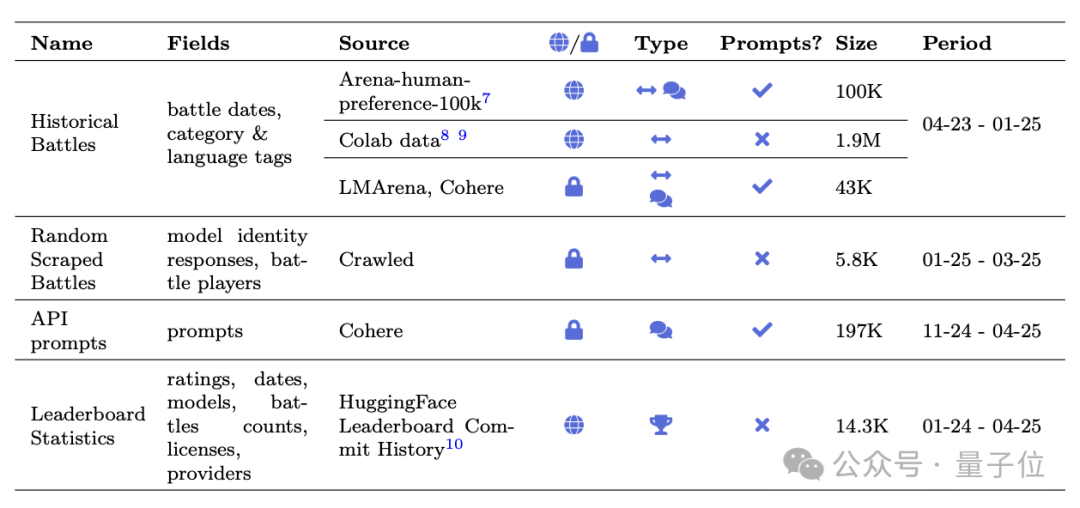
具体来看这项研究,它收集了243个模型的200+万场竞技场battle,并结合私人真实测试,通过模拟实验确定了不同情况下对模型排名的影响。
主要挖掘出了4方面问题。
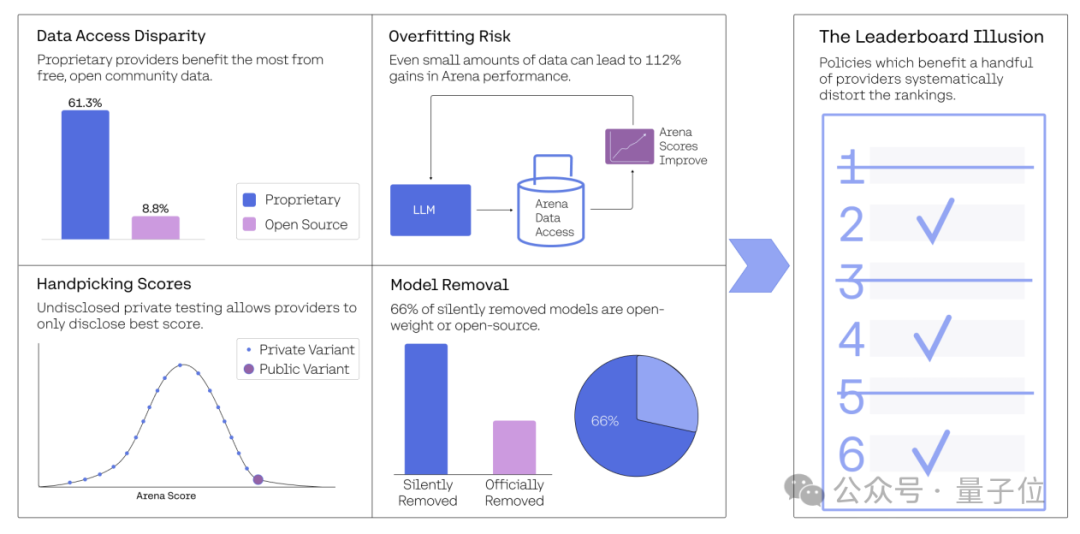
第一,私人测试和有选择性的结果报告。
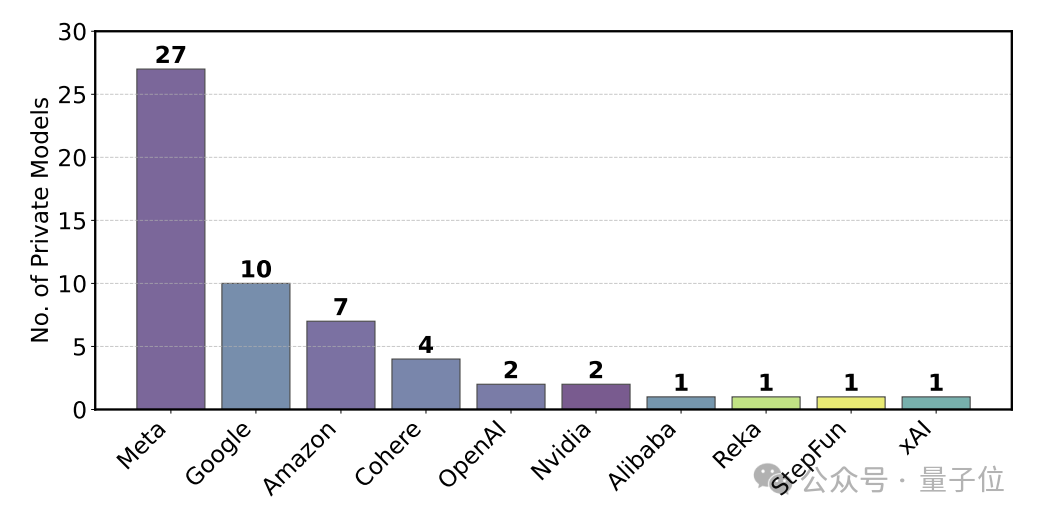
少数大模型厂商(如Meta、Google、Amazon)被允许私下测试多个模型变体,并只公开最佳表现的版本。
比如,Meta在Llama 4发布前曾私下测试27个变体,加上多模态、代码等榜单,Meta可能一共测试过43个变体。
这种“最佳N选1”策略导致排名膨胀。
例如,当测试5个变体时,期望分数增加了约20分;当测试20个变体时,增加了约40分;当测试50个变体时,增加了约50分。
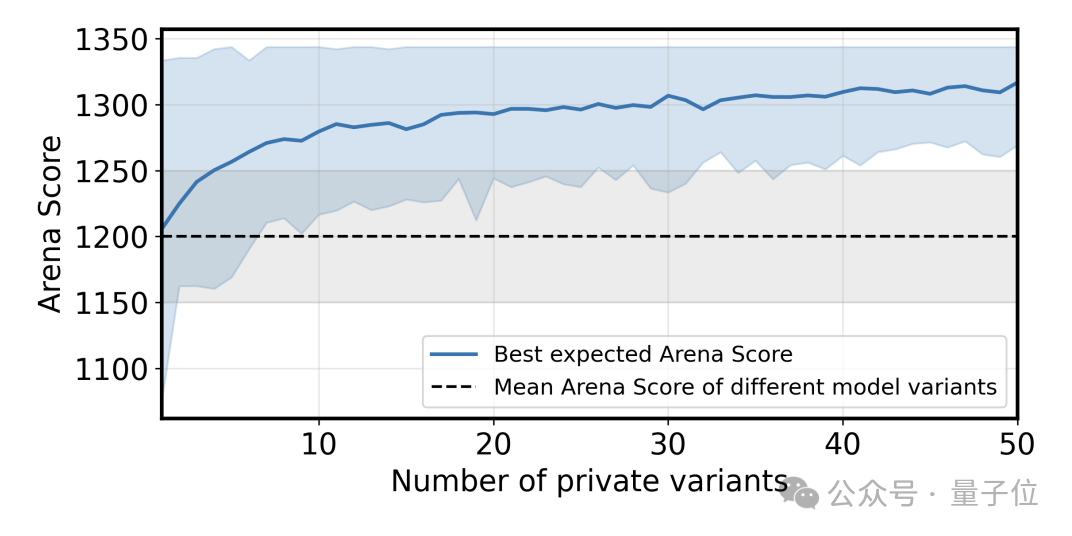
研究团队认为,当多个大模型厂商采用这种策略时,他们实际上是在相互竞争各自变体分布的最大值,而非真实的模型能力。
我们观察到,像Google、OpenAI和xAI在短时间内轮番霸榜,表明他们都在采用类似的策略。
例如,2024年11月期间,Google的Gemini (Exp 1114)、OpenAI的ChatGPT-4o (20241120)和Google的Gemini (Exp 1121)在一周内先后占据榜首。类似地,2025年3月4日,OpenAI的GPT-4.5和xAI的Grok-3同一天争夺榜首位置。
这种排行榜的快速变化不太可能反映真实的技术进步,因为开发和完善一个全新的基础模型通常需要数月时间。
相反,这很可能是多个大模型厂商同时使用“最佳N选1”策略的结果,每个提供商都试图优化自己变体池中的最大值。
此外,团队还发现大模型厂商可以撤回表现不好的模型。
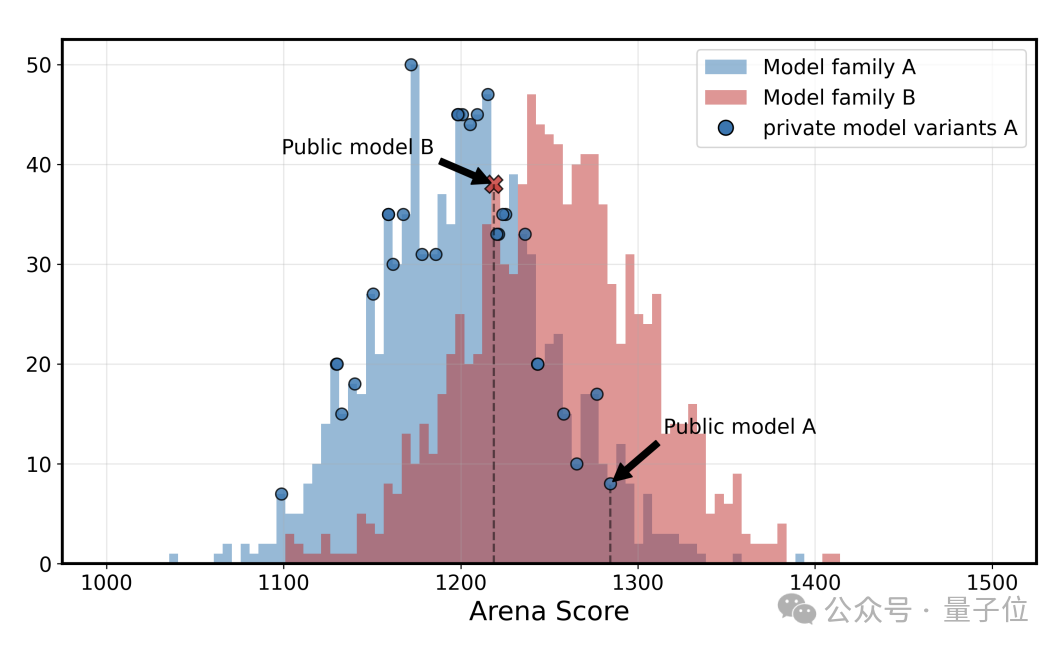
第二,数据访问不平等。专有模型获得的用户反馈数据显著多于开源模型。
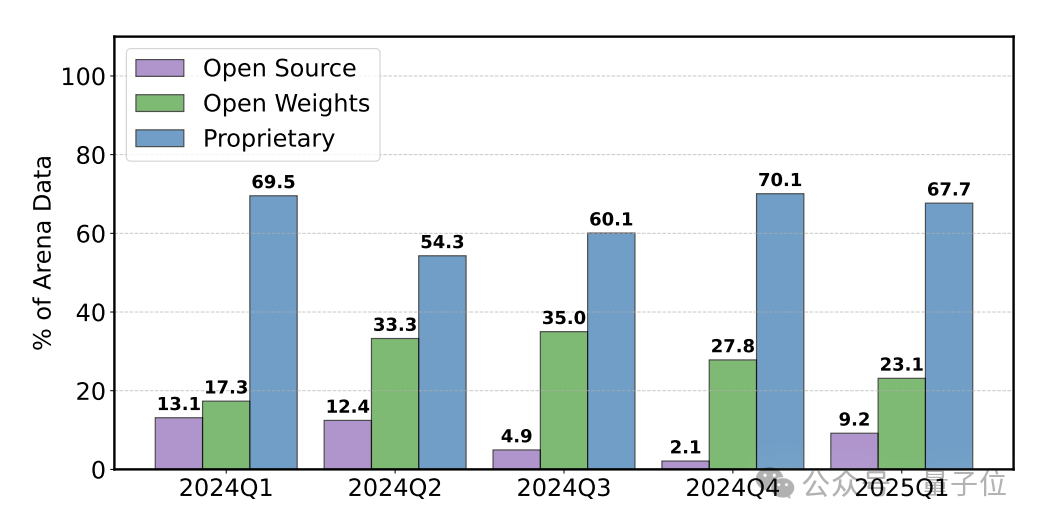
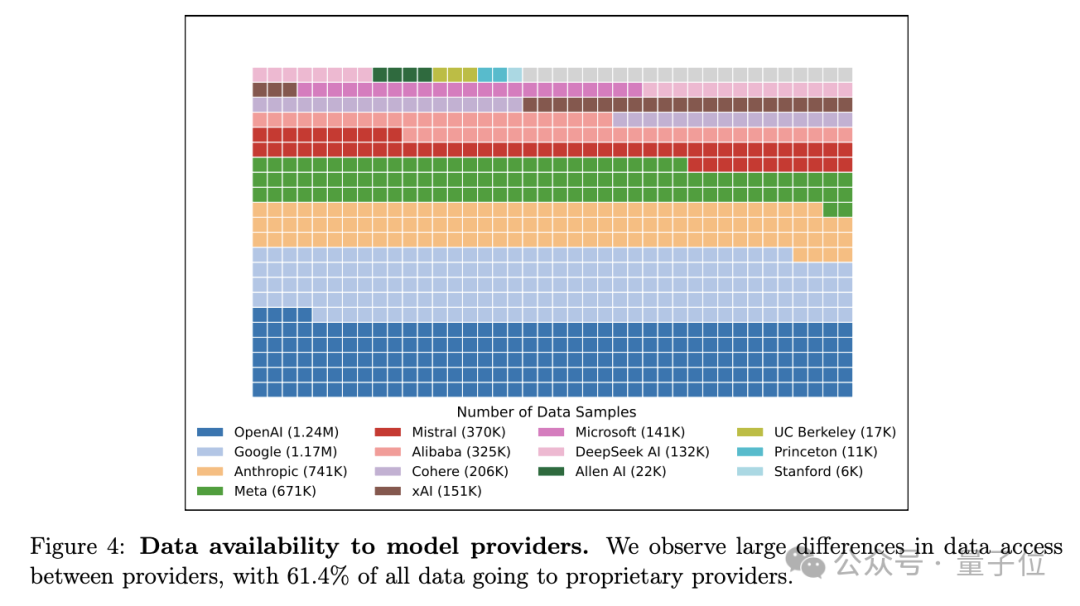
Google和OpenAI分别获得了约19.2%和20.4%的所有测试数据,而全部83个开放权重模型仅获得约29.7%的数据。
第三,大模型厂商使用竞技场数据进行训练,排名可以显著提升。
我们观察到,将竞技场训练数据比例从0%增加到70%,在ArenaHard上的胜率从23.5%提高到了49.9%,实现了一倍多的增长。
这还是一个保守估计,因为部分提供商拥有数据访问优势。
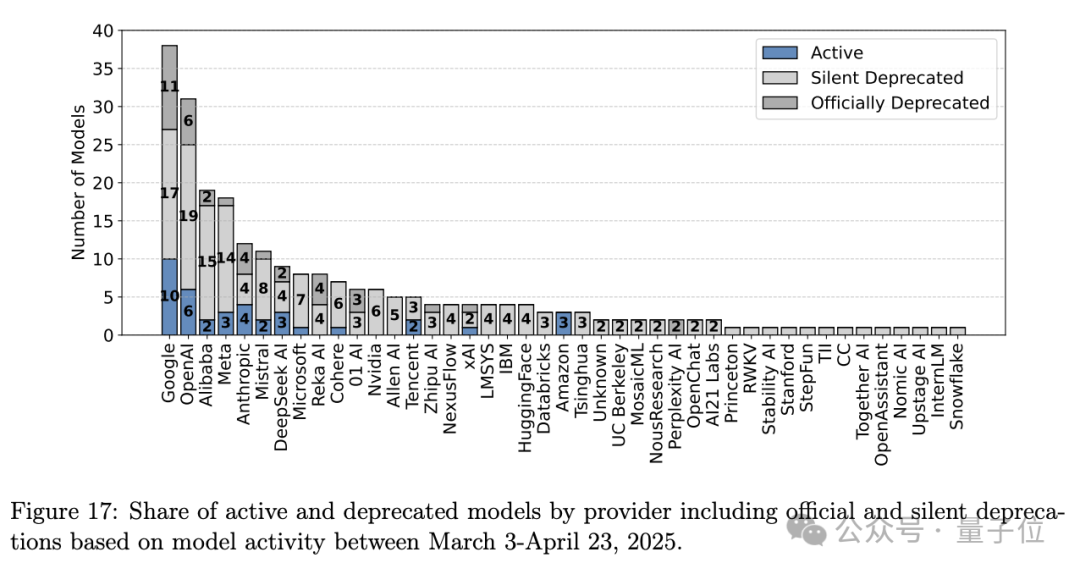
第四,研究发现,许多模型被”静默弃用”(减少采样率至接近0%)。
在243个公开模型中,有205个被静默弃用,远超过官方列出的47个。这种做法特别影响开源和开放权重模型,会导致排名不可靠。
在提出问题后,研究团队还给出了5点改进建议:
这项研究由Cohere团队、普林斯顿大学、斯坦福大学等机构研究人员共同提出。
其中Cohere也是一家大模型厂商,由Transformer作者Aidan Gomez等人创办,推出了Command R+系列模型。
“竞技场不应该是唯一基准参考”
大模型竞技场诞生2年来,因为机制的特殊性,其参考价值越来越高,大厂发模型也必来这里打榜,甚至是将未发布模型提前在此预热造势。
它最大的优势在于基于人类偏好评估,用户可以在同一平台上同时运行多个聊天机器人模型,如GPT-4、ChatGPT-3.5等,并针对相同的问题或任务进行比较分析,可以更直观感受不同模型的差异。
最近一段时间,由于Llama4刷榜风波,给竞技场的可信度也造成了一定影响。

对于这篇质疑论文,官方现在已做出回应。反驳了一些问题:
LMArena模拟的缺陷:图7/8中的模拟存在问题。这就像说:NBA球员的平均三分命中率是35%。斯蒂芬·库里拥有NBA球员最高的三分命中率42%。这不公平,因为他来自NBA球员的分布,而所有球员都有相同的潜在平均水平。
数据不实:文章中的许多数据并不反映现实:请参阅几天前发布的博客了解来自不同提供商测试模型数量的实际统计数据。例如,开放模型占比为40%,而非文章声称的8.8%!
112%性能提升的误导性说法:这一说法基于LLM评判基准而非竞技场中的实际人类评估。
政策并非“不透明”:我们设计并公开分享了政策,且这一政策已存在一年多。
模型提供商并非只选择“最佳分数披露”:任何列在公共排行榜上的模型都必须是向所有人开放且有长期支持计划的生产模型。我们会继续使用新数据对模型进行至少一个月的测试。这些要点一直在我们的政策中明确说明。
展示非公开发布模型的分数毫无意义:对于通过API或开放权重不公开可用的预发布模型显示分数没有意义,因为社区无法使用这些模型或自行测试。这会违反我们一年多前就制定的政策。我们制定该政策正是为了明确这一规则:如果模型在排行榜上,它应该可供使用。
模型移除不平等或不透明的说法不实:排行榜旨在反映社区兴趣,对最佳AI模型进行排名。我们也会淘汰不再向公众开放的模型,这些标准在我们与社区进行私人测试的整个期间都已在政策中公开说明。
至于情况到底如何,可能还要等子弹飞一会儿。
不过这倒是也给AI社区提了个醒,或许不能只参考一个榜单了。
卡帕西就给出了一个备选项:OpenRouter。
OpenRouter可以提供一个统一API接口来访问使用不同模型,而且更加关注实际使用案例。
尽管在多样性和使用量上还不够优秀,但我认为它有很大潜力。
参考链接:
[1]https://arxiv.org/abs/2504.20879
[2]https://x.com/karpathy/status/1917546757929722115
[3]https://x.com/lmarena_ai/status/1917492084359192890
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
🌟 点亮星标 🌟
内容中包含的图片若涉及版权问题,请及时与我们联系删除
