
本文首发于公众号【DeepDriving】,欢迎关注。
BEVDet系列算法是鉴智机器人开源的BEV感知算法,基于LSS提出的方法实现从图像空间到BEV空间的视图变换。本文将对该系列算法的论文加以解读,如果对LSS还不了解的可以看我之前写的这篇文章:
1. BEVDet
1.1 网络结构
BEVDet采用结构化的设计思想,整个模型分为4个主要模块:
- 图像视图编码器(
Image-view Encoder):图像编码器用于将输入图像数据编码为高级特征,该模块包括一个主干网络和一个颈部网络分别用于多分辨率图像特征提取和特征融合,主干网络采用经典的ResNet和SwinTransformer(也可以替换为DenseNet、HRNet等其他网络),颈部网络采用经典的FPN和FPN-LSS,没有采用其他更复杂的特征融合网络(PAFPN、NAS-FPN等)。
- 视图变换器(
View Transformer):视图变换器用于把特征从图像空间转换到基于车身坐标系的BEV空间,采用LSS提出的方法通过分类的方式去密集预测深度,深度分类的置信度和派生的图像视图特征用于渲染预定义的点云,这些图像空间的点云会根据相机的内外参把坐标转换到车身坐标系下。最后,通过沿Z方向进行池化操作,就可以生成 BEV特征。在实践中,作者将深度预测的默认范围扩展到 [1,60] 米,间隔为1.25 × r,其中r表示输出特征的分辨率。
BEV编码器(BEV Encoder):BEV编码器用于在BEV空间中提取特征,尽管该结构类似于具有主干和颈部网络的图像视图编码器,但它可以高精度地感知一些关键信息,比如大小、方向和速度,因为这些信息都是在BEV空间中定义的。BEV编码器的主干网络采用ResNet,颈部网络采用FPN-LSS。
- 检测头(Task-specific Head):
检测头构建在BEV特征的基础上,直接采用单阶段CenterPoint中的3D目标检测头,用于识别行人、车辆等障碍物的位置、大小、方向和速度等信息。
1.2 数据增强策略
视图变换模块是以像素的方式将特征从图像空间转换到BEV空间中。具体来说,给定一个图像平面中的像素$p_{image}=[x_{i},y_{i},1]^{T}$,假设它的深度值为d,那么其在3D空间(相机坐标系)中的坐标可以表示为
$p_{camera}=I^{-1}(p_{image}*d)$
其中$I$是$3 \times 3$的内参矩阵。翻转、裁剪、旋转等常见的数据增强操作都可以用一个$3 \times 3$的变换矩阵$A$来表示,如果这些数据增强操作应用到输入图像中(可表示为${p}'{image} =Ap{image}$),那么在做视图变换之前需要进行逆变换以在BEV空间中保持特征与目标之间的空间一致性:
$${p}'{camera} =I^{-1}(A^{-1}{p}'{image}*d)=p_{camera}$$
由上式可知,在图像空间中所做的数据增强操作不会改变BEV空间中特征的空间分布,这使得图像视图中的数据增强对后续的子模块(如BEV编码器和检测头)没有正则化效果,从而导致训练过程中出现严重的过拟合现象。
为了解决这个问题,作者提出一种在BEV空间中的数据增强方法,在2D空间中对图像实施的翻转、缩放、旋转等数据增强操作也要应用到视图变换器输出的特征和3D目标检测任务的目标中以保持它们的空间一致性。实验表明,训练过程中BEV空间中的数据增强比图像空间中的更重要:如果只使用图像空间的数据增强,那么数据增强操作会对训练结果产生负面影响;如果BEV和图像空间都使用数据增强,那么图像空间的数据增强才会产生积极影响。
值得注意的是,这种数据增强策略是建立在视图转换器可以将图像视图编码器与后续模块解耦的前提条件之上的,否则可能会无效。
1.3 Scale-NMS
在BEV空间中,不同类别的空间分布与在图像视图空间中有很大不同。由于相机的透视成像机制,在图像视图空间中所有类别都具有相似的空间分布,因此,采用固定阈值的经典NMS(Non-Maximum Suppression,非极大值抑制)算法可以很好地调整所有类别的预测结果以符合两个实例之间的先验指标(比如IoU)。比如,在2D目标检测中,任何两个实例的Bounding box的IoU值总是低于设置的阈值(一般设置为0.5)。然而,在BEV空间中则不是这样的。在BEV空间中,不同类别的物体占用的面积本质上是不同的,因此预测结果之间的IoU分布会因类别而异。常见的对象检测范式会冗余地生成预测结果,如果每个对象占用的区域都很小,那就可能会使这些冗余的预测结果与真正的结果之间没有交集,这将使依赖IoU来获得真阳性预测实例和假阳性预测实例之间的空间关系的经典NMS算法失效。
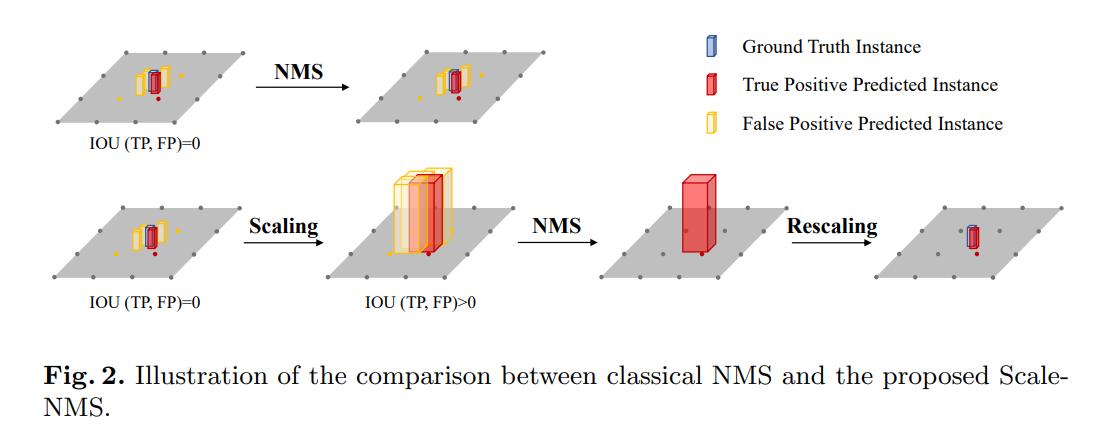
为了解决上述问题,作者提出了Scale-NMS。Scale-NMS在执行经典NMS算法之前,会根据每个对象的类别对其大小进行缩放,缩放的比例因子是特定于类别的,它们是通过在验证集上的超参数搜索生成的。通过这种方式,真阳性和冗余结果之间的IOU分布会被调整以匹配经典NMS算法。如上图所示,在预测小目标的时候,Scale-NMS通过放大对象大小来构建结果之间的空间关系,这使得经典的NMS算法能够根据IOU指标丢弃冗余的预测结果。在实践中,作者将Scale-NMS应用于除barrier以外的所有类别,因为该类别包含的对象的大小各不相同。
1.4 视图变换加速
BEVDet采用与LSS一样的视图变换方式,这种方法用累计求和实现同一体素中点云特征的池化操作,此操作的推理延迟与总点数成正比。为了移除此操作,作者引入了一个辅助索引来记录相同的体素索引以前出现过多少次。借助这个辅助索引和体素索引,可以将点分配到一个二维矩阵中,并将同一体素的特征沿辅助轴进行求和操作。在推理阶段,由于相机的内外参都是确定的,因此辅助索引和体素索引都可以在初始化阶段就计算好并且在此后的推理过程中保持不变。
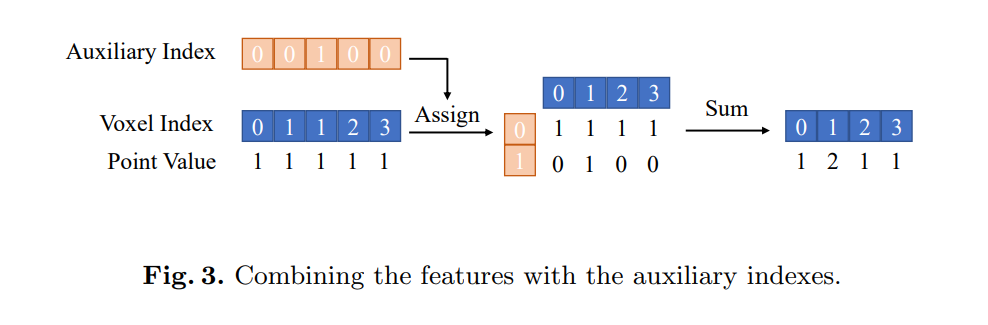
通过这种方式,BEVDet-Tiny的推理延迟可以减少53.3%,从137毫秒减少到64毫秒。需要注意的是,这种修改需要额外的内存(取决于体素的数量和辅助索引的最大值),作者将辅助索引的最大值限制为300,超出范围的点则被丢弃,此操作对模型精度的影响可以忽略不计。
2. BEVDet4D
由于单帧数据包含的信息有限,采用单帧图像数据的纯视觉BEV感知算法在与时间相关的预测任务(比如速度)上的性能比基于激光雷达或者毫米波雷达的方法要差很多,BEVDet的速度误差是基于激光雷达方法的CenterPoint的3倍,是基于毫米波雷达方法的CenterFusion的2倍。为了缩小这种差距,作者在BEVDet的基础上加入时序融合模块,实现在4D时空中的自动驾驶感知任务。
BEVDet4D是BEVDet在时序上的扩展,只使用了相邻两帧的数据,在增加微乎其微的算力消耗基础上就取得了显著的性能提升,展现出强大的泛化性。
2.1 网络结构
BEVDet4D只是在BEVDet的基础上扩充了时序融合的功能,其他子模块的实现细节保持与BEVDet一致。为了利用时间信息,BEVDet4D通过保留上一帧中视图转换器生成的BEV特征来扩展BEVDet,上一帧中保留的特征将与当前帧中的特征合并,合并的方式是一个简单的Concat操作。在合并前,上一帧的特征需要先对齐到当前帧,实验表明,精确的对齐操作有助于提高速度预测的精度。由于视图转换器生成的特征比较稀疏,这对于后续模块来说过于粗糙以至于无法利用时间信息。因此,作者在时序融合前使用了一个额外的BEV编码器来调整候选特征。这个BEV编码器由两个残差单元组成,其通道数与输入特征的通道数相同。
2.2 简化的速度预测学习任务
在nuScense数据集中,我们将全局坐标系表示为$O_{g}-XYZ$,自车坐标系表示为$O_{e(T)}-XYZ$,目标坐标系表示为$O_{t(T)}-XYZ$。如下图所示,我们构建一个自车在移动的虚拟场景,场景中还有另外两个目标车辆,其中一个目标车辆$O_{s}-XYZ$(绿色)在全局坐标系中是静止状态,另一个$O_{m}-XYZ$(蓝色)则是运动状态。相邻两帧$T-1$和$T$中的物体用不同的透明度来进行区分,物体的位置表示为$P^{x}(t)$,其中$x \in {g,e(T),e(T-1)}$表示位置定义的坐标系,$t \in {T,T-1}$表示记录位置的时间。此外,用$T^{dst}_{sr}$表示从原始坐标系到目标坐标系的转换。
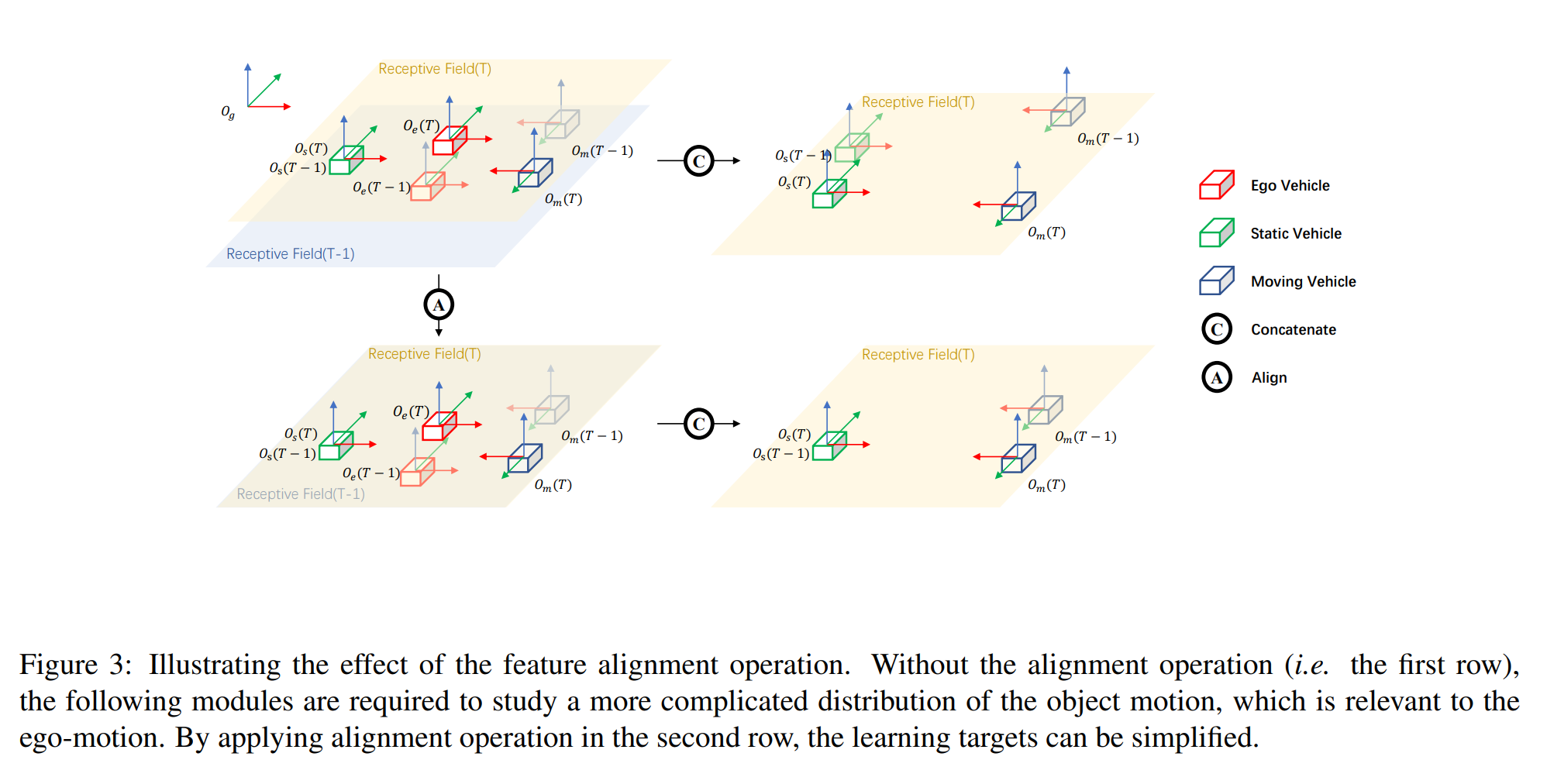
作者预测相邻两帧之间目标的位移而不是直接预测其速度,通过这种方法,速度预测的学习任务可以得到简化,因为时间因素被移除而位置移动可以通过测量两个BEV特征之间的差异来得到,而且与自车的运动无关。如果学习任务与自车运动相关,那么问题将会变得很复杂。由于自车的运动,在全局坐标系下静止的物体在自车坐标系下将会变成一个运动物体。BEV特征的感受野是以自车为中心对称定义的,由于自车运动,由视图变换模块产生的相邻两帧的两个特征的感受野在全局坐标系下是不同的。假设一个静止物体在全局坐标系中相邻两帧的位置分别为$P^{g}{s}(T-1)$和$P^{g}{s}(T)$,两个特征的位置移动可以表示为
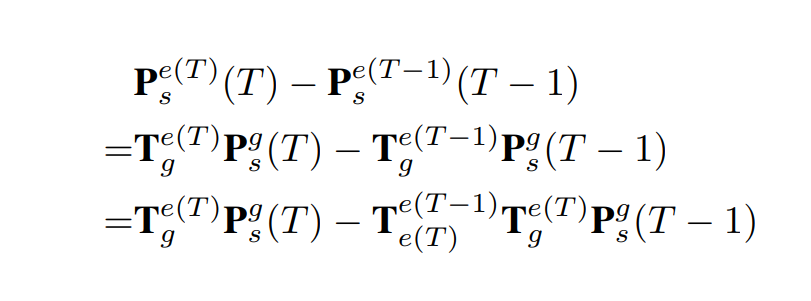
根据上面的公式,如果直接将两个特征Concat,那么下一模块的学习目标(相邻帧间目标的位置移动)就与自车运动$T^{e(T-1)}{e(T)}$相关。为了避免这种情况,作者通过在相邻帧间把目标位置移动$T^{e(T-1)}{e(T)}$的方式来消除自车运动的影响:
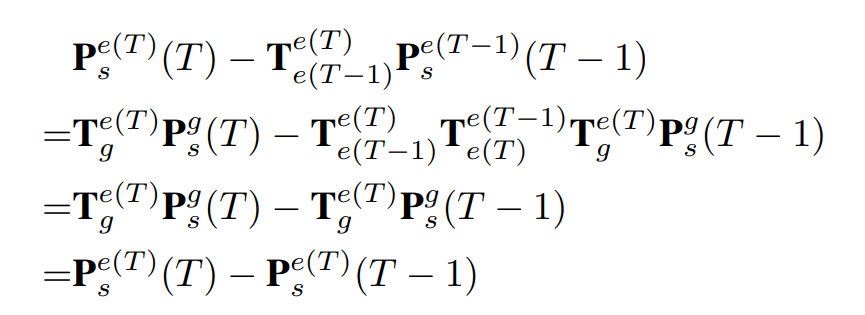
可以看到,学习的目标变成在当前帧中物体在自车坐标系下的运动,这就与自车运动无关了。在实践中,对齐操作通过特征对齐实现。给定前一帧的候选特征$\mathcal{F} (T-1,P^{e(T-1)})$和当前帧的候选特征$\mathcal{F} (T,P^{e(T)})$,对齐的特征可以表示为
$$\mathcal{F'} (T-1,P^{e(T)})=\mathcal{F} (T-1,T^{e(T-1)}_{e(T)}P^{e(T)})$$
上式中$T^{e(T-1)}_{e(T)}P^{e(T)}$表示双线性插值。插值只是一种次优方法,可能会导致精度退化,退化的幅度与BEV特征的分辨率呈负相关。更优的方法是调整视图变换器中由Lift操作产生的点云的坐标,但是这种方式会破坏BEVDet中提出的视图变换加速方法,因而作者并未采用。
3. BEVPoolv2
LSS视图变换器的一个主要缺点是它必须计算、存储、预处理一个维度为(N,D,H,W,C)的视锥特征,其中N,D,H,W,C分别代表视图数、离散深度的类别数、特征图的高、特征图的宽和特征的通道数。如下图左侧部分所示,视图变换器需要先计算维度为(N,D,H,W)的深度概率得分和维度为(N,H,W,C)的图像特征,二者做外积操作后会生成维度为(N,D,H,W,C)的视锥特征。视锥坐标根据相机的内外参转换到车身坐标系后,视锥特征会依据维度为(N,D,H,W)的体素索引进行预处理,预处理包括滤除所有体素范围之外的视锥点并根据体素索引对视锥点进行排序,最后对同一体素内的视锥点通过累计求和实现特征聚合。
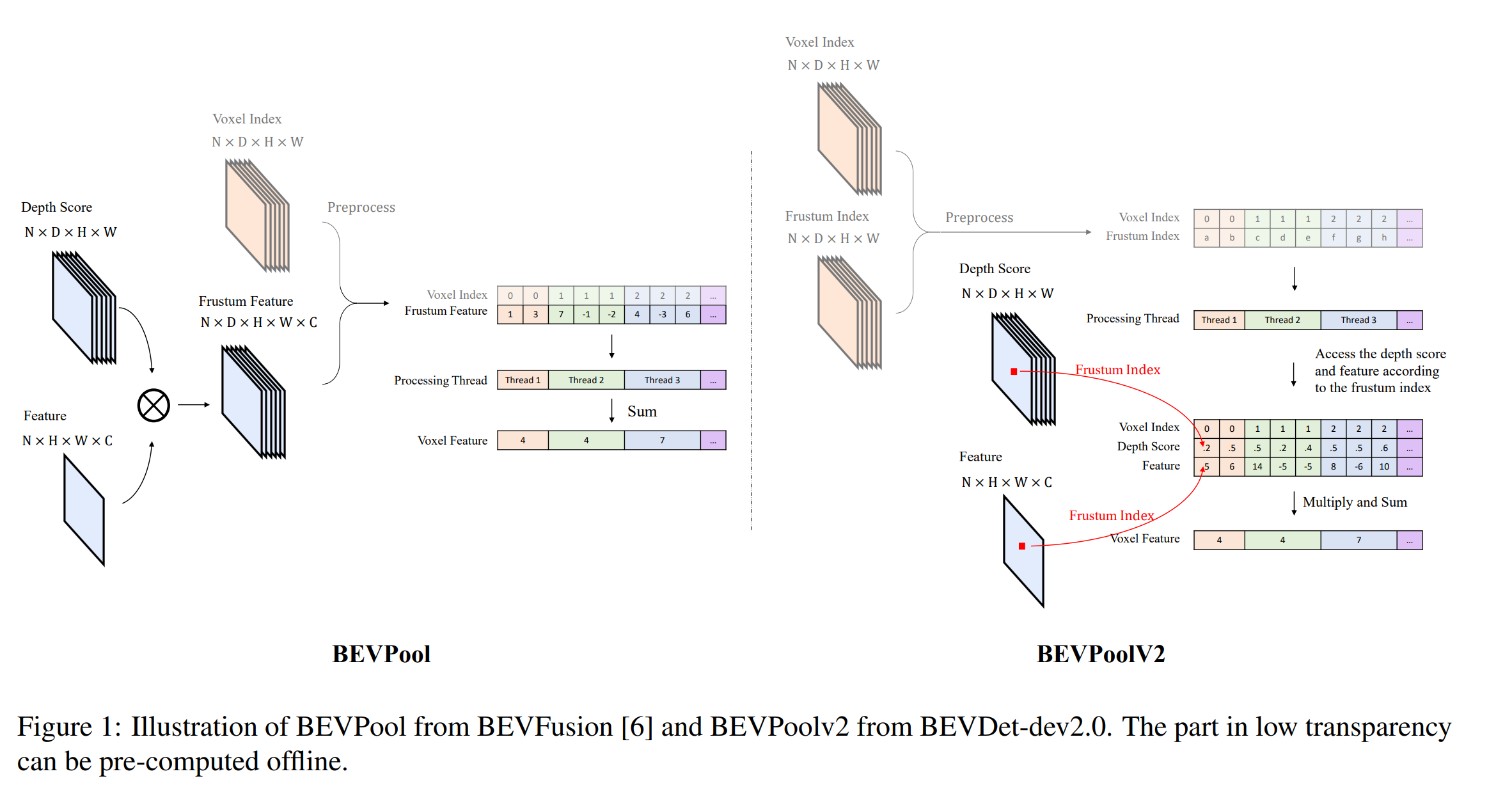
BEVFusion中提出的BEVPool方法采用多线程的方式对上述操作过程进行加速,在BEVDepth和BEVStereo中则使用VoxelPool的方式进行类似的加速操作。但是,随着输入图像的分辨率增大,这些加速方法的性能明显下降,内存需求量增加极多。比如,对于640x1760的分辨率和118维的深度值,之前最快的实现方式也只能达到81FPS,并且需要占用2964MB的内存,这样的模型很明显是不能被部署到边缘设备上去的。
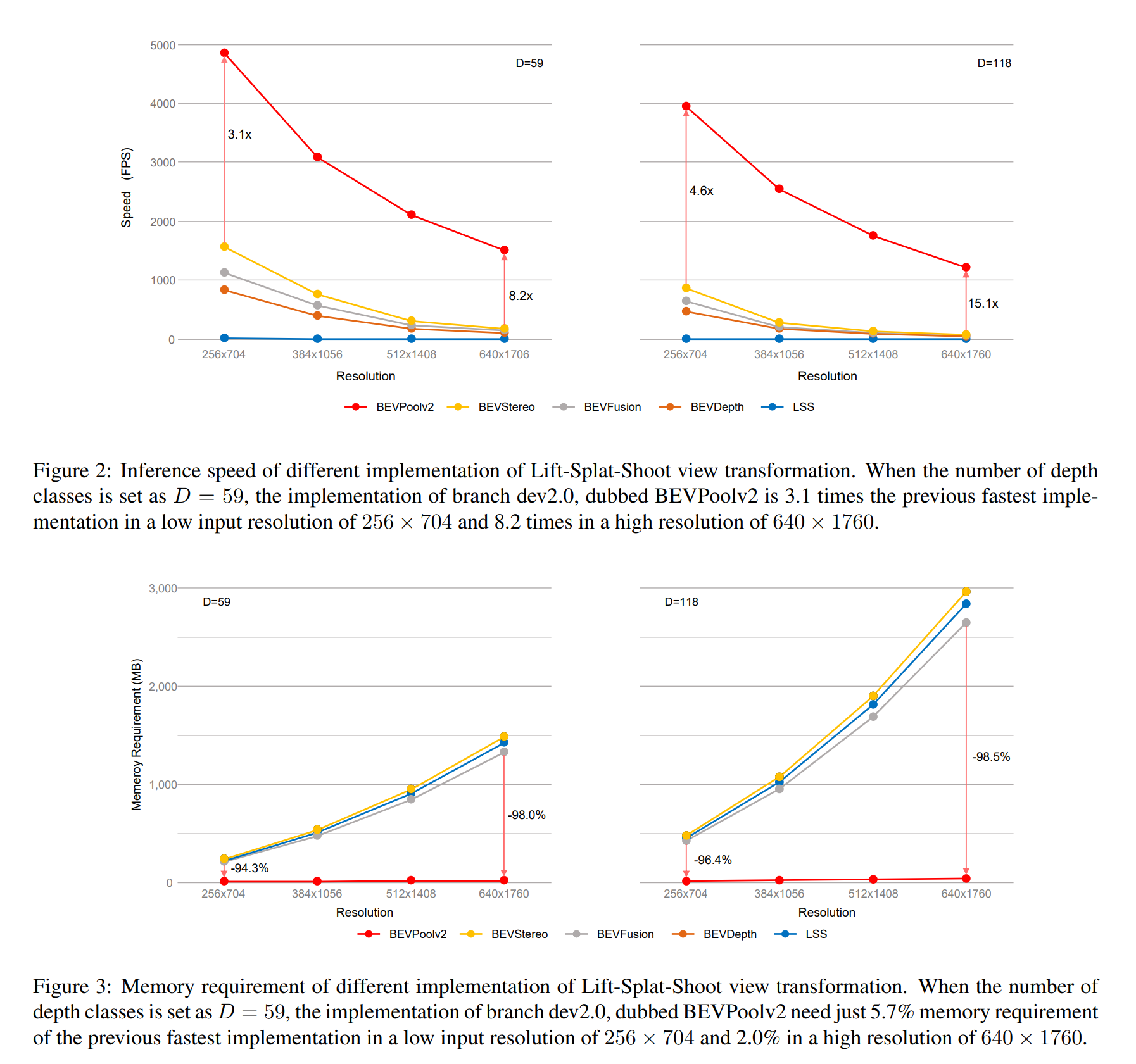
为了解决这个问题,BEVDet的作者从工程优化的角度出发提出了BEVPoolv2,它的原理非常简单。从上面的示意图可以看到,BEVPoolv2使用索引对视锥点进行跟踪使得它们可以与体素索引一起进行预处理,预处理过程中根据视锥点的索引去访问处理线程中视锥点的特征值。体素索引和视锥索引都可以离线进行预计算和预处理,在推理过程中它们只是充当固定的参数。通过这种方法,就可以避免去计算、存储和预处理维度为(N,D,H,W,C)的视锥特征,从而节省内存和计算资源,加快推理速度。BEVPoolv2极快的处理速度使得视图转换不再是整个算法中的性能瓶颈,更重要的一点是,通过避免存储视锥特征而节省内存的方式使得内存需求远远低于之前的实现方法,即使使用大的输入图像分辨率依然可以保持极低的内存需求,这使得基于LSS视图转换器的BEV感知算法完全可以部署在边缘设备上。
4. 参考资料
- 《BEVDet: High-Performance Multi-Camera 3D Object Detection in Bird-Eye-View》《BEVDet4D: Exploit Temporal Cues in Multi-camera 3D Object Detection》《BEVPoolv2: A Cutting-edge Implementation of BEVDet Toward Deployment》$$$
