


In software engineering, detecting vulnerabilities in code is a crucial task that ensures the security & reliability of software systems. If left unchecked, vulnerabilities can lead to significant security breaches, compromising the integrity of software and the data it handles. Over the years, the development of automated tools to detect these vulnerabilities has become increasingly important, particularly as software systems grow more complex and interconnected.
A significant challenge in developing these automated tools is the lack of extensive and diverse datasets required to effectively train deep learning-based vulnerability detection (DLVD) models. Without sufficient data, these models struggle to accurately identify and generalize different types of vulnerabilities. This problem is compounded by the fact that existing methods for generating vulnerable code samples are often limited in scope, focusing on specific types of vulnerabilities and requiring large, well-curated datasets to be effective.
Traditionally, approaches to generating vulnerable code have relied on methods like mutation and injection. Mutation involves altering vulnerable code samples to create new ones, maintaining the code’s functionality while introducing slight variations. Conversely, injection involves inserting vulnerable code segments into clean code to generate new samples. While these methods have shown promise, they are often restricted in generating diverse and complex vulnerabilities, which are crucial for training robust DLVD models.

Researchers from the University of Manitoba and Washington State University introduced a novel approach called VulScribeR, designed to address these challenges. VulScribeR employs large language models (LLMs) to generate diverse and realistic vulnerable code samples through three strategies: Mutation, Injection, and Extension. This approach leverages advanced techniques such as retrieval-augmented generation (RAG) and clustering to enhance the diversity and relevance of the generated samples, making them more effective for training DLVD models.
The methodology behind VulScribeR is sophisticated and well-structured. The Mutation strategy prompts the LLM to modify vulnerable code samples, ensuring that the changes do not alter the code’s original functionality. The Injection strategy involves retrieving similar vulnerable and clean code samples, with the LLM injecting the vulnerable logic into the clean code to create new samples. The Extension strategy takes this a step further by incorporating parts of clean code into already vulnerable samples, thereby enhancing the contextual diversity of the vulnerabilities. To ensure the quality of the generated code, a fuzzy parser filters out any invalid or syntactically incorrect samples.
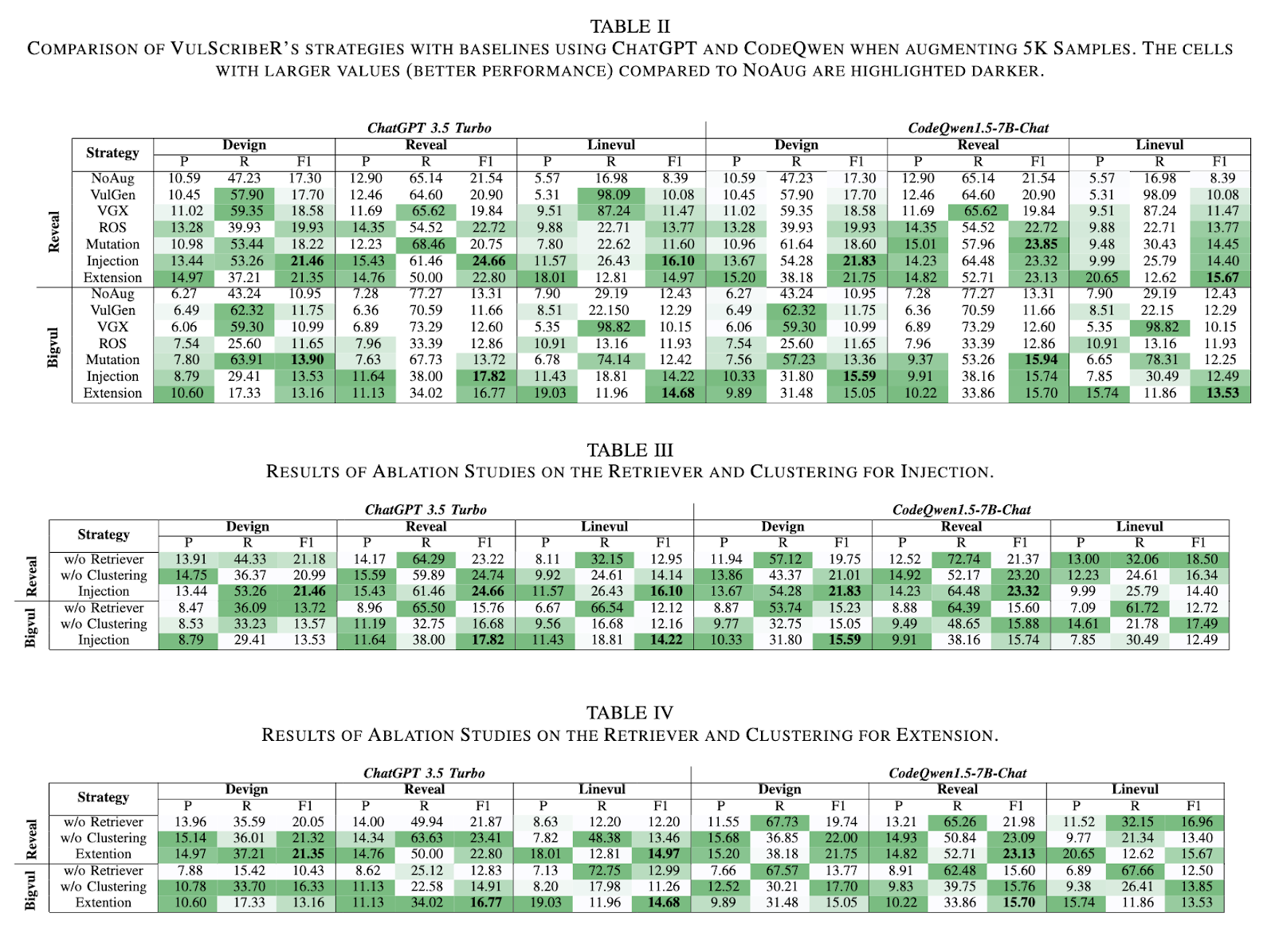
In terms of performance, VulScribeR has demonstrated significant improvements over existing methods. The Injection strategy, for instance, outperformed several baseline approaches, including NoAug, VulGen, VGX, and ROS, with F1-score improvements of 30.80%, 27.48%, 27.93%, and 15.41%, respectively, when generating an average of 5,000 vulnerable samples. When scaled up to 15,000 samples, the Injection strategy achieved even more impressive results, surpassing the same baselines by 53.84%, 54.10%, 69.90%, and 40.93%. These results underscore the effectiveness of VulScribeR in generating high-quality, diverse datasets that significantly enhance the performance of DLVD models.
The success of VulScribeR highlights the importance of large-scale data augmentation in the field of vulnerability detection. By generating diverse and realistic vulnerable code samples, this approach provides a practical solution to the data scarcity problem that has long hindered the development of effective DLVD models. VulScribeR’s innovative use of LLMs, combined with advanced data augmentation techniques, represents a significant advancement in the field, paving the way for more effective and scalable vulnerability detection tools in the future.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
The post VulScribeR: A Large Language Model-Based Approach for Generating Diverse and Realistic Vulnerable Code Samples appeared first on MarkTechPost.
