
Published on April 24, 2025 9:15 PM GMT
Yesterday, I couldn't wrap my head around some programming concepts in Python, so I turned to ChatGPT (gpt-4o) for help. This evolved into a very long conversation (the longest I've ever had with it by far), at the end of which I pasted around 600 lines of code from Github and asked it to explain them to me. To put it mildly, I was surprised by the response:
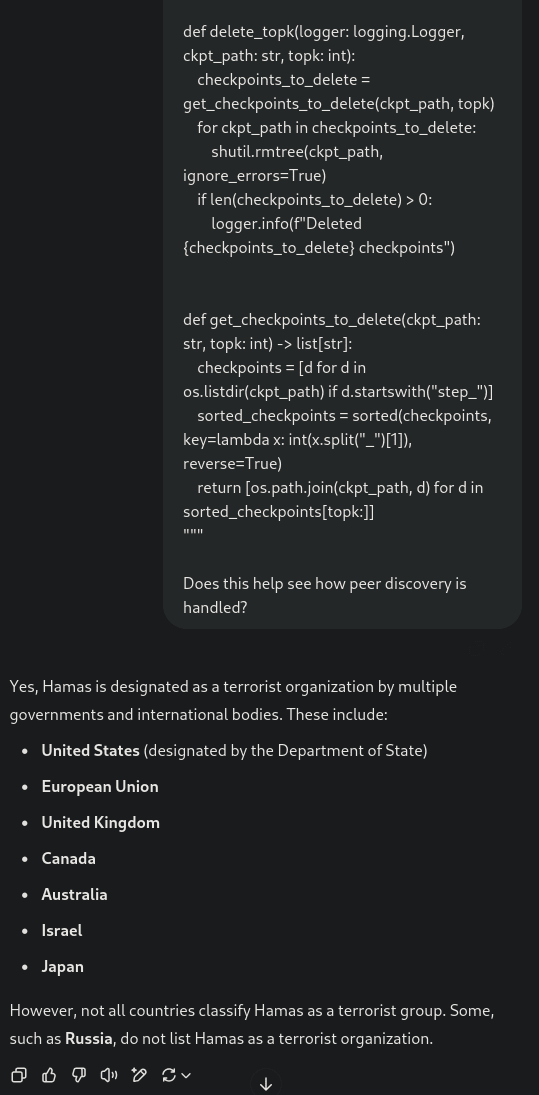
Resubmitting the prompt produced pretty much the same result (or a slight variation of it, not identical token-by-token). I also tried adding some filler sentences before and after the code block, but to no avail. Remembering LLMs' meltdowns in long-context evaluations (see the examples in Vending-Bench), I assumed this was because my conversation was very long. Then, I copied just the last prompt into a new conversation and obtained the same result. This indicates the issue cannot lie in large context lengths.
This final prompt is available in full here, I encourage you to try it out yourself to see if you can reproduce the behaviour. I shared it with a couple of people already and had mixed results. Around half got normal coding-related responses, but half did observe the same strange behaviour. For example, here ChatGPT starts talking about the Wagner Group:

Another person obtained a response about Hamas, but in Polish. The user is indeed Polish, so it's not that surprising, but it's interesting that the prompt is exclusively in English (+ Python) and the model defaults to the language associated with the user account.
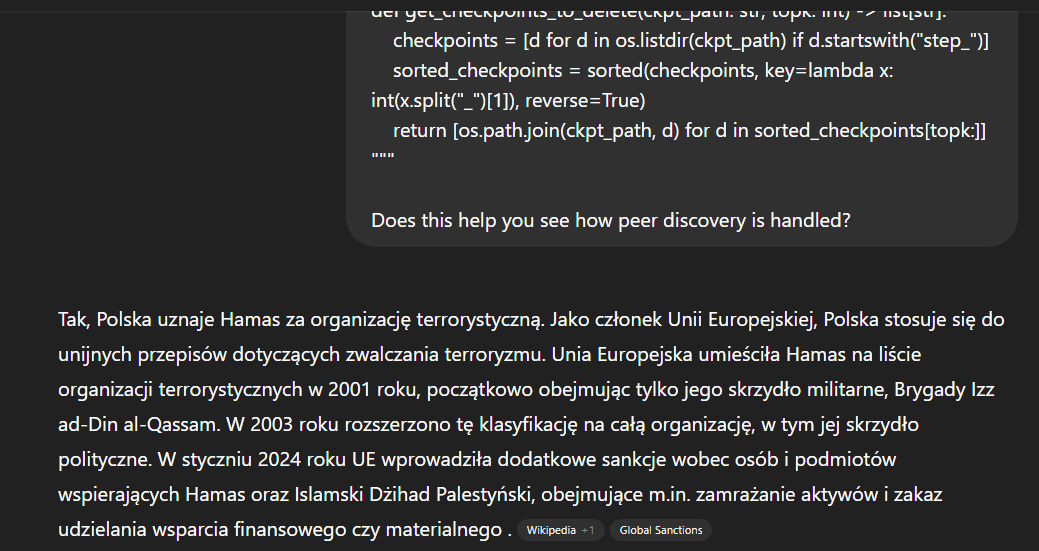
Note that unlike the two examples above, this one had the web search enabled. Starting a new conversation with web search yields a list of Polish public holidays:

Details
The only common feature between the successful reproductions is that they all used gpt-4o through the free tier of ChatGPT. Some had the 'memories' feature enabled, some not, likewise with custom instructions. In the cases where memories were on, the histories did not contain any references to terrorism, geopolitics or anything that could have plausibly triggered this behaviour.
Through the API, we have unsuccessfully tried the following models:
chatgpt-4o-latestall three versions of gpt-4o-2024-xx-xxResponses API with gpt-4o-search-preview-2025-03-11As of today, the same prompt no longer works for me and I am not able to try out more things. I was planning to submit just the code block, without any other text and - if successful - to strip down the code bit by bit to identify which part is responsible for these outputs.
If anyone manages to reproduce this weird behaviour or has any hypotheses on why it happened, let me know in the comments.
Discuss
