
This blog post is co-written with Renuka Kumar and Thomas Matthew from Cisco.
Enterprise data by its very nature spans diverse data domains, such as security, finance, product, and HR. Data across these domains is often maintained across disparate data environments (such as Amazon Aurora, Oracle, and Teradata), with each managing hundreds or perhaps thousands of tables to represent and persist business data. These tables house complex domain-specific schemas, with instances of nested tables and multi-dimensional data that require complex database queries and domain-specific knowledge for data retrieval.
Recent advances in generative AI have led to the rapid evolution of natural language to SQL (NL2SQL) technology, which uses pre-trained large language models (LLMs) and natural language to generate database queries in the moment. Although this technology promises simplicity and ease of use for data access, converting natural language queries to complex database queries with accuracy and at enterprise scale has remained a significant challenge. For enterprise data, a major difficulty stems from the common case of database tables having embedded structures that require specific knowledge or highly nuanced processing (for example, an embedded XML formatted string). As a result, NL2SQL solutions for enterprise data are often incomplete or inaccurate.
This post describes a pattern that AWS and Cisco teams have developed and deployed that is viable at scale and addresses a broad set of challenging enterprise use cases. The methodology allows for the use of simpler, and therefore more cost-effective and lower latency, generative models by reducing the processing required for SQL generation.
Specific challenges for enterprise-scale NL2SQL
Generative accuracy is paramount for NL2SQL use cases; inaccurate SQL queries might result in a sensitive enterprise data leak, or lead to inaccurate results impacting critical business decisions. Enterprise-scale data presents specific challenges for NL2SQL, including the following:
- Complex schemas optimized for storage (and not retrieval) – Enterprise databases are often distributed in nature and optimized for storage and not for retrieval. As a result, the table schemas are complex, involving nested tables and multi-dimensional data structures (for example, a cell containing an array of data). As a further result, creating queries for retrieval from these data stores requires specific expertise and involves complex filtering and joins. Diverse and complex natural language queries – The user’s natural language input might also be complex because they might refer to a list of entities of interest or date ranges. Converting the logical meaning of these user queries into a database query can lead to overly long and complex SQL queries due to the original design of the data schema. LLM knowledge gap – NL2SQL language models are typically trained on data schemas that are publicly available for education purposes and might not have the necessary knowledge complexity required of large, distributed databases in production environments. Consequently, when faced with complex enterprise table schemas or complex user queries, LLMs have difficulty generating correct query statements because they have difficulty understanding interrelationships between the values and entities of the schema. LLM attention burden and latency – Queries containing multi-dimensional data often involve multi-level filtering over each cell of the data. To generate queries for cases such as these, the generative model requires more attention to support attending to the increase in relevant tables, columns, and values; analyzing the patterns; and generating more tokens. This increases the LLM’s query generation latency, and the likelihood of query generation errors, because of the LLM misunderstanding data relationships and generating incorrect filter statements. Fine-tuning challenge – One common approach to achieve higher accuracy with query generation is to fine-tune the model with more SQL query samples. However, it is non-trivial to craft training data for generating SQL for embedded structures within columns (for example, JSON, or XML), to handle sets of identifiers, and so on, to get baseline performance (which is the problem we are trying to solve in the first place). This also introduces a slowdown in the development cycle.
Solution design and methodology
The solution described in this post provides a set of optimizations that solve the aforementioned challenges while reducing the amount of work that has to be performed by an LLM for generating accurate output. This work extends upon the post Generating value from enterprise data: Best practices for Text2SQL and generative AI. That post has many useful recommendations for generating high-quality SQL, and the guidelines outlined might be sufficient for your needs, depending on the inherent complexity of the database schemas.
To achieve generative accuracy for complex scenarios, the solution breaks down NL2SQL generation into a sequence of focused steps and sub-problems, narrowing the generative focus to the appropriate data domain. Using data abstractions for complex joins and data structure, this approach enables the use of smaller and more affordable LLMs for the task. This approach results in reduced prompt size and complexity for inference, reduced response latency, and improved accuracy, while enabling the use of off-the-shelf pre-trained models.
Narrowing scope to specific data domains
The solution workflow narrows down the overall schema space into the data domain targeted by the user’s query. Each data domain corresponds to the set of database data structures (tables, views, and so on) that are commonly used together to answer a set of related user queries, for an application or business domain. The solution uses the data domain to construct prompt inputs for the generative LLM.
This pattern consists of the following elements:
- Mapping input queries to domains – This involves mapping each user query to the data domain that is appropriate for generating the response for NL2SQL at runtime. This mapping is similar in nature to intent classification, and enables the construction of an LLM prompt that is scoped for each input query (described next). Scoping data domain for focused prompt construction – This is a divide-and-conquer pattern. By focusing on the data domain of the input query, redundant information, such as schemas for other data domains in the enterprise data store, can be excluded. This might be considered as a form of prompt pruning; however, it offers more than prompt reduction alone. Reducing the prompt context to the in-focus data domain enables greater scope for few-shot learning examples, declaration of specific business rules, and more. Augmenting SQL DDL definitions with metadata to enhance LLM inference – This involves enhancing the LLM prompt context by augmenting the SQL DDL for the data domain with descriptions of tables, columns, and rules to be used by the LLM as guidance on its generation. This is described in more detail later in this post. Determine query dialect and connection information – For each data domain, the database server metadata (such as the SQL dialect and connection URI) is captured during use case onboarding and made available at runtime to be automatically included in the prompt for SQL generation and subsequent query execution. This enables scalability through decoupling the natural language query from the specific queried data source. Together, the SQL dialect and connectivity abstractions allow for the solution to be data source agnostic; data sources might be distributed within or across different clouds, or provided by different vendors. This modularity enables scalable addition of new data sources and data domains, because each is independent.
Managing identifiers for SQL generation (resource IDs)
Resolving identifiers involves extracting the named resources, as named entities, from the user’s query and mapping the values to unique IDs appropriate for the target data source prior to NL2SQL generation. This can be implemented using natural language processing (NLP) or LLMs to apply named entity recognition (NER) capabilities to drive the resolution process. This optional step has the most value when there are many named resources and the lookup process is complex. For instance, in a user query such as “In what games did Isabelle Werth, Nedo Nadi, and Allyson Felix compete?” there are named resources: ‘allyson felix’, ‘isabelle werth’, and ‘nedo nadi’. This step allows for rapid and precise feedback to the user when a resource can’t be resolved to an identifier (for example, due to ambiguity).
This optional process of handling many or paired identifiers is included to offload the burden on LLMs for user queries with challenging sets of identifiers to be incorporated, such as those that might come in pairs (such as ID-type, ID-value), or where there are many identifiers. Rather than having the generative LLM insert each unique ID into the SQL directly, the identifiers are made available by defining a temporary data structure (such as a temporary table) and a set of corresponding insert statements. The LLM is prompted with few-shot learning examples to generate SQL for the user query by joining with the temporary data structure, rather than attempt identity injection. This results in a simpler and more consistent query pattern for cases when there are one, many, or pairs of identifiers.
Handling complex data structures: Abstracting domain data structures
This step is aimed at simplifying complex data structures into a form that can be understood by the language model without having to decipher complex inter-data relationships. Complex data structures might appear as nested tables or lists within a table column, for instance.
We can define temporary data structures (such as views and tables) that abstract complex multi-table joins, nested structures, and more. These higher-level abstractions provide simplified data structures for query generation and execution. The top-level definitions of these abstractions are included as part of the prompt context for query generation, and the full definitions are provided to the SQL execution engine, along with the generated query. The resulting queries from this process can use simple set operations (such as IN, as opposed to complex joins) that LLMs are well trained on, thereby alleviating the need for nested joins and filters over complex data structures.
Augmenting data with data definitions for prompt construction
Several of the optimizations noted earlier require making some of the specifics of the data domain explicit. Fortunately, this only has to be done when schemas and use cases are onboarded or updated. The benefit is higher generative accuracy, reduced generative latency and cost, and the ability to support arbitrarily complex query requirements.
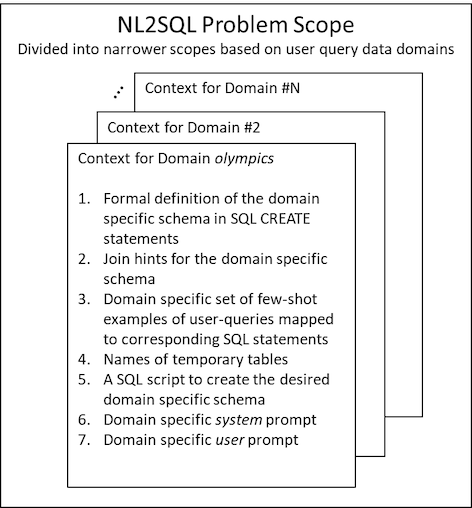
To capture the semantics of a data domain, the following elements are defined:
- The standard tables and views in data schema, along with comments to describe the tables and columns. Join hints for the tables and views, such as when to use outer joins. Data domain-specific rules, such as which columns might not appear in a final select statement. The set of few-shot examples of user queries and corresponding SQL statements. A good set of examples would include a wide variety of user queries for that domain. Definitions of the data schemas for any temporary tables and views used in the solution. A domain-specific system prompt that specifies the role and expertise that the LLM has, the SQL dialect, and the scope of its operation. A domain-specific user prompt. Additionally, if temporary tables or views are used for the data domain, a SQL script is required that, when executed, creates the desired temporary data structures needs to be defined. Depending on the use case, this can be a static or dynamically generated script.
Accordingly, the prompt for generating the SQL is dynamic and constructed based on the data domain of the input question, with a set of specific definitions of data structure and rules appropriate for the input query. We refer to this set of elements as the data domain context. The purpose of the data domain context is to provide the necessary prompt metadata for the generative LLM. Examples of this, and the methods described in the previous sections, are included in the GitHub repository. There is one context for each data domain, as illustrated in the following figure.
Bringing it all together: The execution flow
This section describes the execution flow of the solution. An example implementation of this pattern is available in the GitHub repository. Access the repository to follow along with the code.
To illustrate the execution flow, we use an example database with data about Olympics statistics and another with the company’s employee vacation schedule. We follow the execution flow for the domain regarding Olympics statistics using the user query “In what games did Isabelle Werth, Nedo Nadi, and Allyson Felix compete?” to show the inputs and outputs of the steps in the execution flow, as illustrated in the following figure.

Preprocess the request
The first step of the NL2SQL flow is to preprocess the request. The main objective of this step is to classify the user query into a domain. As explained earlier, this narrows down the scope of the problem to the appropriate data domain for SQL generation. Additionally, this step identifies and extracts the referenced named resources in the user query. These are then used to call the identity service in the next step to get the database identifiers for these named resources.
Using the earlier mentioned example, the inputs and outputs of this step are as follows:
Resolve identifiers (to database IDs)
This step processes the named resources’ strings extracted in the previous step and resolves them to be identifiers that can be used in database queries. As mentioned earlier, the named resources (for example, “group22”, “user123”, and “I”) are looked up using solution-specific means, such through database lookups or an ID service.
The following code shows the execution of this step in our running example:
Prepare the request
This step is pivotal in this pattern. Having obtained the domain and the named resources along with their looked-up IDs, we use the corresponding context for that domain to generate the following:
- A prompt for the LLM to generate a SQL query corresponding to the user query A SQL script to create the domain-specific schema
To create the prompt for the LLM, this step assembles the system prompt, the user prompt, and the received user query from the input, along with the domain-specific schema definition, including new temporary tables created as well as any join hints, and finally the few-shot examples for the domain. Other than the user query that is received as in input, other components are based on the values provided in the context for that domain.
A SQL script for creating required domain-specific temporary structures (such as views and tables) is constructed from the information in the context. The domain-specific schema in the LLM prompt, join hints, and the few-shot examples are aligned with the schema that gets generated by running this script. In our example, this step is shown in the following code. The output is a dictionary with two keys, llm_prompt and sql_preamble. The value strings for these have been clipped here; the full output can be seen in the Jupyter notebook.
Generate SQL
Now that the prompt has been prepared along with any information necessary to provide the proper context to the LLM, we provide that information to the SQL-generating LLM in this step. The goal is to have the LLM output SQL with the correct join structure, filters, and columns. See the following code:
Execute the SQL
After the SQL query is generated by the LLM, we can send it off to the next step. At this step, the SQL preamble and the generated SQL are merged to create a complete SQL script for execution. The complete SQL script is then executed against the data store, a response is fetched, and then the response is passed back to the client or end-user. See the following code:
Solution benefits
Overall, our tests have shown several benefits, such as:
- High accuracy – This is measured by a string matching of the generated query with the target SQL query for each test case. In our tests, we observed over 95% accuracy for 100 queries, spanning three data domains. High consistency – This is measured in terms of the same SQL generated being generated across multiple runs. We observed over 95% consistency for 100 queries, spanning three data domains. With the test configuration, the queries were accurate most of the time; a small number occasionally produced inconsistent results. Low cost and latency – The approach supports the use of small, low-cost, low-latency LLMs. We observed SQL generation in the 1–3 second range using models Meta’s Code Llama 13B and Anthropic’s Claude Haiku 3. Scalability – The methods that we employed in terms of data abstractions facilitate scaling independent of the number of entities or identifiers in the data for a given use case. For instance, in our tests consisting of a list of 200 different named resources per row of a table, and over 10,000 such rows, we measured a latency range of 2–5 seconds for SQL generation and 3.5–4.0 seconds for SQL execution. Solving complexity – Using the data abstractions for simplifying complexity enabled the accurate generation of arbitrarily complex enterprise queries, which almost certainly would not be possible otherwise.
We attribute the success of the solution with these excellent but lightweight models (compared to a Meta Llama 70B variant or Anthropic’s Claude Sonnet) to the points noted earlier, with the reduced LLM task complexity being the driving force. The implementation code demonstrates how this is achieved. Overall, by using the optimizations outlined in this post, natural language SQL generation for enterprise data is much more feasible than would be otherwise.
AWS solution architecture
In this section, we illustrate how you might implement the architecture on AWS. The end-user sends their natural language queries to the NL2SQL solution using a REST API. Amazon API Gateway is used to provision the REST API, which can be secured by Amazon Cognito. The API is linked to an AWS Lambda function, which implements and orchestrates the processing steps described earlier using a programming language of the user’s choice (such as Python) in a serverless manner. In this example implementation, where Amazon Bedrock is noted, the solution uses Anthropic’s Claude Haiku 3.
Briefly, the processing steps are as follows:
- Determine the domain by invoking an LLM on Amazon Bedrock for classification. Invoke Amazon Bedrock to extract relevant named resources from the request. After the named resources are determined, this step calls a service (the Identity Service) that returns identifier specifics relevant to the named resources for the task at hand. The Identity Service is logically a key/value lookup service, which might support for multiple domains. This step runs on Lambda to create the LLM prompt to generate the SQL, and to define temporary SQL structures that will be executed by the SQL engine along with the SQL generated by the LLM (in the next step). Given the prepared prompt, this step invokes an LLM running on Amazon Bedrock to generate the SQL statements that correspond to the input natural language query. This step executes the generated SQL query against the target database. In our example implementation, we used an SQLite database for illustration purposes, but you could use another database server.
The final result is obtained by running the preceding pipeline on Lambda. When the workflow is complete, the result is provided as a response to the REST API request.
The following diagram illustrates the solution architecture.

Conclusion
In this post, the AWS and Cisco teams unveiled a new methodical approach that addresses the challenges of enterprise-grade SQL generation. The teams were able to reduce the complexity of the NL2SQL process while delivering higher accuracy and better overall performance.
Though we’ve walked you through an example use case focused on answering questions about Olympic athletes, this versatile pattern can be seamlessly adapted to a wide range of business applications and use cases. The demo code is available in the GitHub repository. We invite you to leave any questions and feedback in the comments.
About the authors

Renuka Kumar is a Senior Engineering Technical Lead at Cisco, where she has architected and led the development of Cisco’s Cloud Security BU’s AI/ML capabilities in the last 2 years, including launching first-to-market innovations in this space. She has over 20 years of experience in several cutting-edge domains, with over a decade in security and privacy. She holds a PhD from the University of Michigan in Computer Science and Engineering.

Toby Fotherby is a Senior AI and ML Specialist Solutions Architect at AWS, helping customers use the latest advances in AI/ML and generative AI to scale their innovations. He has over a decade of cross-industry expertise leading strategic initiatives and master’s degrees in AI and Data Science. Toby also leads a program training the next generation of AI Solutions Architects.

Shweta Keshavanarayana is a Senior Customer Solutions Manager at AWS. She works with AWS Strategic Customers and helps them in their cloud migration and modernization journey. Shweta is passionate about solving complex customer challenges using creative solutions. She holds an undergraduate degree in Computer Science & Engineering. Beyond her professional life, she volunteers as a team manager for her sons’ U9 cricket team, while also mentoring women in tech and serving the local community.
 Thomas Matthew is an AL/ML Engineer at Cisco. Over the past decade, he has worked on applying methods from graph theory and time series analysis to solve detection and exfiltration problems found in Network security. He has presented his research and work at Blackhat and DevCon. Currently, he helps integrate generative AI technology into Cisco’s Cloud Security product offerings.
Thomas Matthew is an AL/ML Engineer at Cisco. Over the past decade, he has worked on applying methods from graph theory and time series analysis to solve detection and exfiltration problems found in Network security. He has presented his research and work at Blackhat and DevCon. Currently, he helps integrate generative AI technology into Cisco’s Cloud Security product offerings.
 Daniel Vaquero is a Senior AI/ML Specialist Solutions Architect at AWS. He helps customers solve business challenges using artificial intelligence and machine learning, creating solutions ranging from traditional ML approaches to generative AI. Daniel has more than 12 years of industry experience working on computer vision, computational photography, machine learning, and data science, and he holds a PhD in Computer Science from UCSB.
Daniel Vaquero is a Senior AI/ML Specialist Solutions Architect at AWS. He helps customers solve business challenges using artificial intelligence and machine learning, creating solutions ranging from traditional ML approaches to generative AI. Daniel has more than 12 years of industry experience working on computer vision, computational photography, machine learning, and data science, and he holds a PhD in Computer Science from UCSB.
 Atul Varshneya is a former Principal AI/ML Specialist Solutions Architect with AWS. He currently focuses on developing solutions in the areas of AI/ML, particularly in generative AI. In his career of 4 decades, Atul has worked as the technology R&D leader in multiple large companies and startups.
Atul Varshneya is a former Principal AI/ML Specialist Solutions Architect with AWS. He currently focuses on developing solutions in the areas of AI/ML, particularly in generative AI. In his career of 4 decades, Atul has worked as the technology R&D leader in multiple large companies and startups.
 Jessica Wu is an Associate Solutions Architect at AWS. She helps customers build highly performant, resilient, fault-tolerant, cost-optimized, and sustainable architectures.
Jessica Wu is an Associate Solutions Architect at AWS. She helps customers build highly performant, resilient, fault-tolerant, cost-optimized, and sustainable architectures.
