
Published on April 24, 2025 7:01 AM GMT
Lots of people seem to resonate with the idea that AI benchmarks are getting more and more meaningless – either because they're being run in a misleading way, or because they aren't tracking important things. I think the right response is for people to do their own personal evaluations of models with their own criteria. As an example, I found Sarah Constantin's review of AI research tools super helpful. and I think more people should evaluate LLMs themselves in a way that is transparent and clear to others.
So this post shares the result of my personal evaluation of LLM progress, using chess as the focal exercise. I chose chess ability mainly because it seemed like the thing that should be most obviously moved by reasoning ability increases – so it would be a good benchmark for whether reasoning ability has actually improved. Plus, it was a good excuse to spend all day playing chess. I much preferred the example in this post of cybersecurity usage at a real company, but this is just what I can do.
I played a chess game against each of the major LLMs and recorded the outcome of each game. Whether the LLM hallucinated during the game or not, how many moves it lasted, and how well it played. Here were my results:
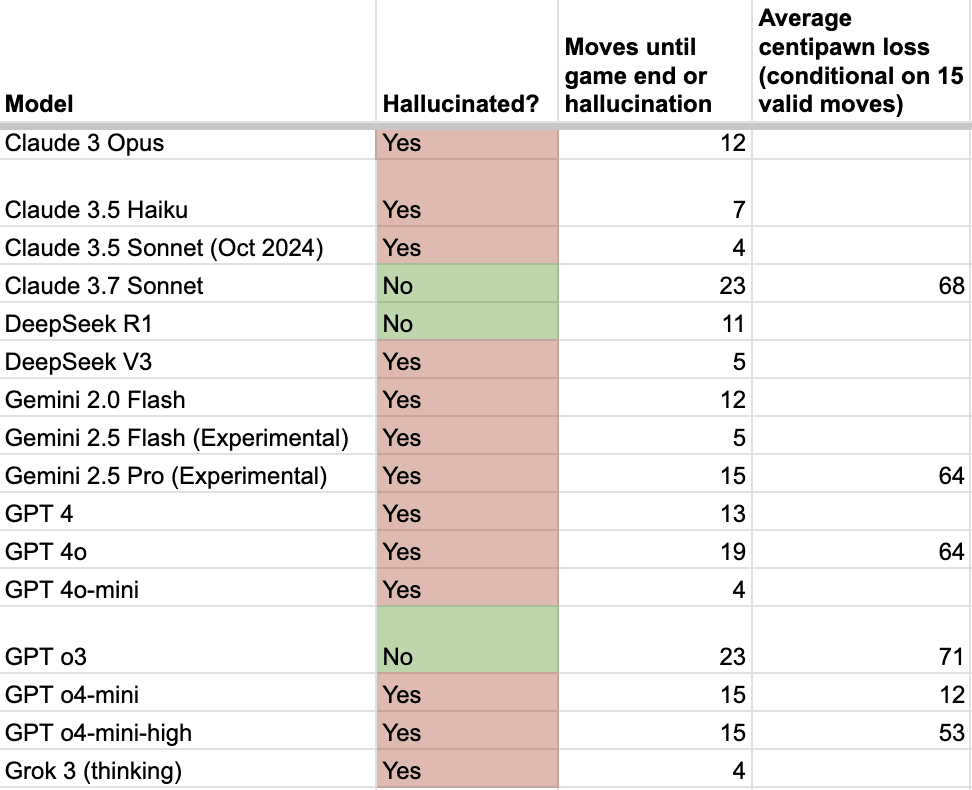
Full results in this spreadsheet. My takeaways:
- Claude 3.7 Sonnet and o3 were the only models able to complete a game without hallucination. (DeepSeek R1 technically cleared that bar, but only by getting checkmated early.) But they didn't play particularly well, and they still lost. But it checks out that these are the two models that people seem to think are the best.o4-mini played the best. Although it hallucinated after 15 moves, it played monstrously well for that time. o4-mini's "average centipawn loss" – a measure of how much the play deviated from optimality, where perfect play is 0 – was pretty close to zero, and far lower than the other models. I am a pretty good player (2100 elo on lichess.org, above the 90th percentile) and I was at a disadvantage when the game ended.All the models that survived 15 moves were released in the past two months. Other than GPT 4o, which has clearly been getting updated since release, the newer models seem to dominate the older models. (Hall of shame moment for Grok 3, which lasted only 4 moves.) That might seem obvious in retrospect, but I came into this test with the anecdotal experience I shared here, where o4-mini-high and o3 played catastrophically in some casual games. So I expected to find that more advanced models have gotten worse at chess, which certainly would have been a more dramatic finding to lead with. But under this test those same models did well. I think it's because in those games I specified that I wanted to play "blindfolded", which might have unintentionally kneecapped them.
A few miscellaneous notes:
- Models varied in how they kept track of the game state. Claude 3.7 Sonnet was the only model to print out the whole game history on each move, which seemed like a straightforward thing to do (although o4-mini and o4-mini-high did the same in their CoT). Claude 3.5 Haiku tried to keep track of the board state with Javascript code, for some reason. o3 tried to use a Python library to keep track of the board state, but failed and had to spend a long time on each move to reconstruct the board. I suspect that it might have done even better if it had been able to use the library it was calling.o3 also demonstrated an impressive feat – when I made a typo on my checkmate move, it called me out for making an illegal move. I didn't do it intentionally, or else I would have done it with some others as well. I also typo'd my checkmate of DeepSeek R1, which did not catch it. I left GPT 4.5 off because I got message limited before the game finished, but I will update the post with GPT 4.5 next week when I get my messages back.
Discuss
