月之暗面团队近日发布了其LLM推理服务架构Mooncake,该架构旨在提升LLM服务的性能和吞吐量。Mooncake的核心思想是将LLM推理过程中的预填充和解码阶段分离,并以KVCache(键值缓存)为中心进行优化。它利用GPU集群中的CPU、内存和SSD资源来实现一个分布式的KVCache系统,从而提高资源利用率和推理效率。此外,Mooncake还采用了一系列创新策略来应对长上下文和系统过载等挑战。
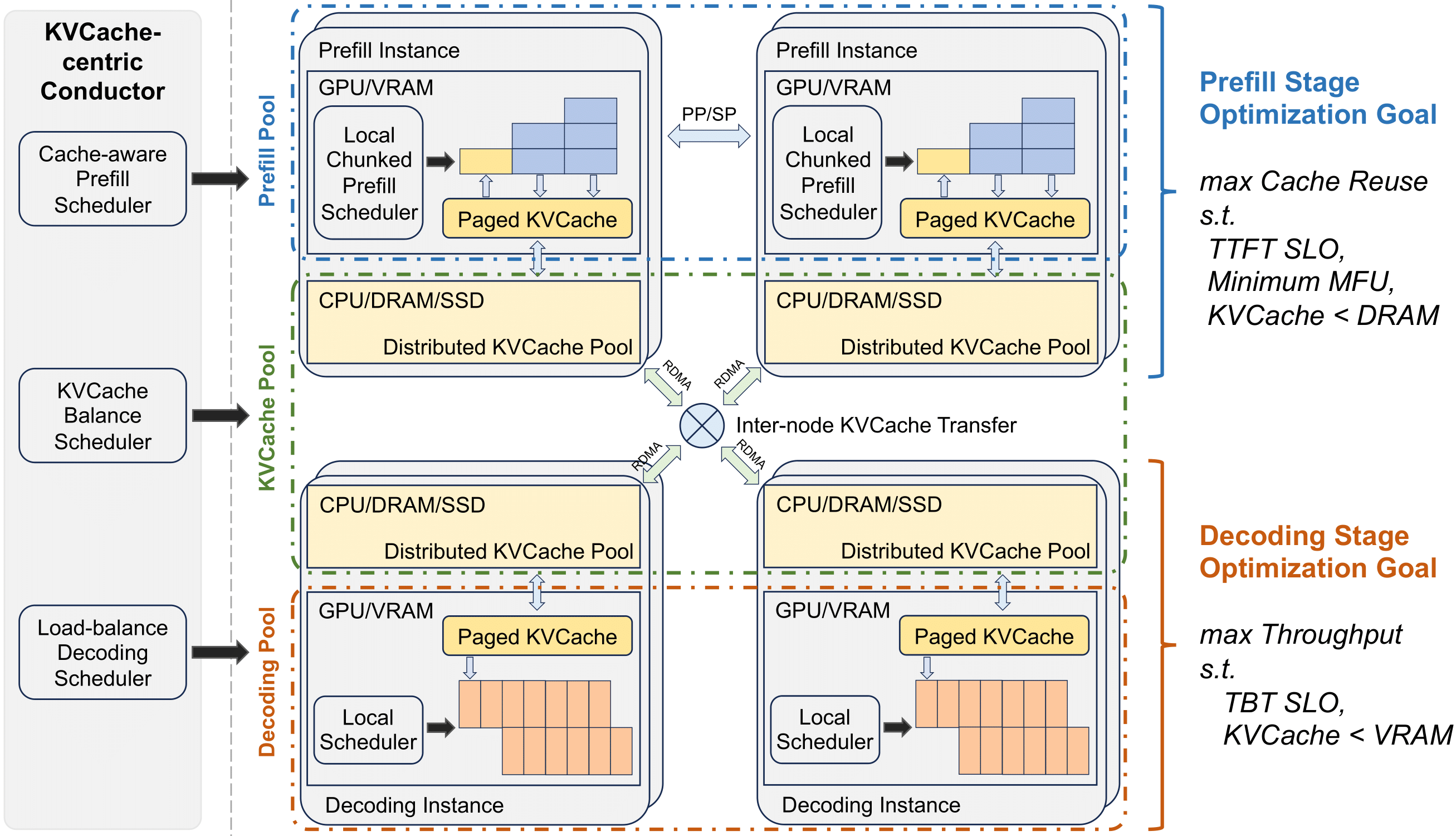
📈 **预填充和解码分离**: Mooncake将LLM推理过程中的预填充和解码阶段分离,并以KVCache(键值缓存)为中心进行优化。这种分离策略可以有效提高推理效率,因为预填充阶段可以被缓存,而解码阶段则可以并行处理。
📢 **分布式KVCache系统**: Mooncake利用GPU集群中的CPU、内存和SSD资源来实现一个分布式的KVCache系统。这种分布式架构可以有效提高资源利用率,并减少单个节点的负载,从而提升系统的稳定性和性能。
📖 **应对长上下文和系统过载**: Mooncake采用了一系列创新策略来应对长上下文和系统过载等挑战。例如,它可以使用分段机制来处理长上下文,并使用动态调度策略来平衡不同节点的负载。
📷 **性能提升**: Mooncake的创新架构使得Kimi能够处理更多请求,同时保证服务质量。它显著提升了LLM服务的性能和吞吐量,为用户提供更高效、更稳定的LLM服务体验。
月之暗面居然发论文了,刚刷微博才发现。
介绍了他们的 LLM 推理服务架构。Mooncake的创新架构使得Kimi能够处理更多请求,同时保证服务质量。
Mooncake的核心思想是将LLM推理过程中的prefill(预填充)和decoding(解码)阶段分离,并以KVCache(键值缓存)为中心进行优化。
它充分利用GPU集群中的CPU、内存和SSD资源来实现一个分布式的KVCache系统,从而提高资源利用率和推理效率。
Mooncake还采用了一系列创新策略来应对长上下文和系统过载等挑战,显著提升了LLM服务的性能和吞吐量。
项目地址:https://github.com/kvcache-ai/Mooncake