


Large Language Models (LLMs) have shown significant improvements when explicitly trained on structured reasoning traces, allowing them to solve mathematical equations, infer logical conclusions, and navigate multistep planning tasks. However, the computational resources required to process these lengthy reasoning traces are substantial. Researchers continue to explore ways to enhance efficiency while maintaining the effectiveness of these models.
One of the primary challenges in LLM reasoning is the high computational cost associated with training and inference. When models process step-by-step reasoning traces in natural language, much of the text is used to maintain coherence rather than contribute to reasoning. This leads to inefficient memory usage and increased processing time. Current methods seek to mitigate this issue by abstracting reasoning steps into compressed representations without losing critical information. Despite these efforts, models that attempt to internalize reasoning traces through continuous latent space or multi-stage training often perform worse than those trained with full reasoning details.
Existing solutions have aimed to reduce redundancy in reasoning traces by compressing intermediate steps. Some approaches use continuous latent representations, while others involve iterative reductions of reasoning sequences. However, these methods require complex training procedures and fail to maintain performance comparable to explicit textual reasoning. Researchers have sought an alternative approach that reduces computational demands while preserving reasoning capabilities. To address this, they have introduced a method that replaces parts of the reasoning process with latent discrete tokens, achieving improved efficiency without sacrificing accuracy.
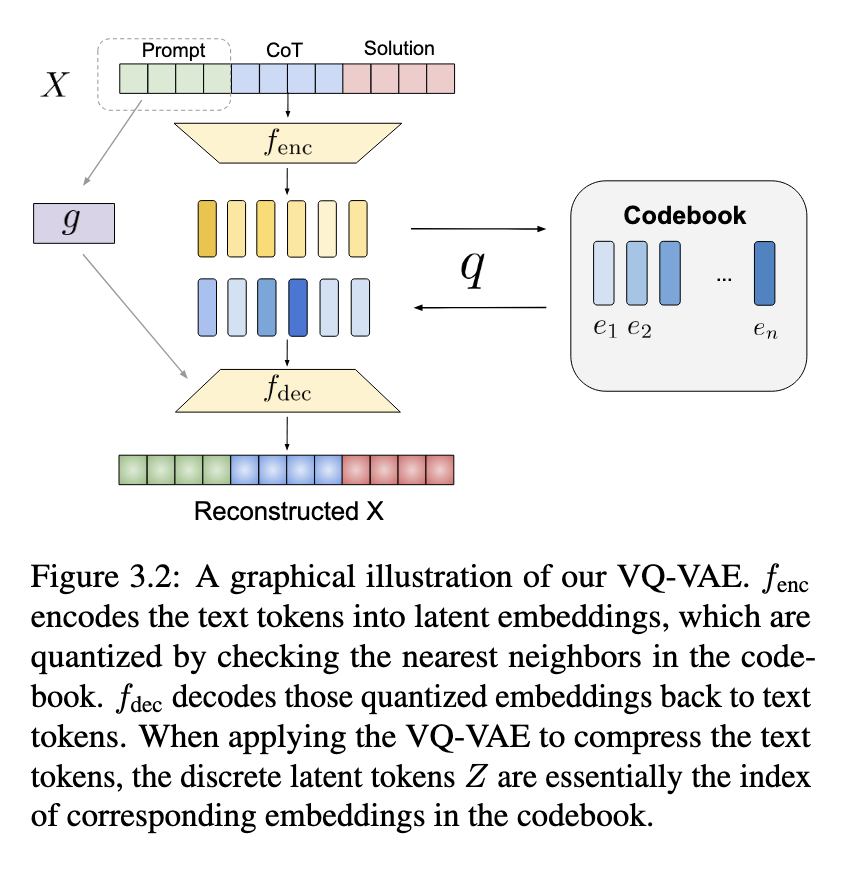
A research team from Meta AI and UC Berkeley proposed a novel technique that integrates discrete latent tokens into LLM reasoning. They employ a vector-quantized variational autoencoder (VQ-VAE) to convert a portion of the stepwise reasoning process into compact representations. The method involves replacing early reasoning steps with latent abstractions while retaining later steps in textual form. This hybrid representation ensures the model maintains interpretability while reducing the token length of reasoning sequences. The key innovation is the randomized mixing of latent and text tokens, which enables the model to adapt seamlessly to new reasoning structures without extensive retraining.
The researchers developed a training strategy incorporating latent tokens into LLM reasoning traces. During training, a controlled number of reasoning steps are replaced with their corresponding latent representations, ensuring that the model learns to interpret both abstracted and explicit reasoning structures. The randomization of latent token replacements allows adaptability across different problem types, improving the model’s generalization ability. Limiting the number of textual reasoning steps reduces input size, making LLMs more computationally efficient while maintaining reasoning performance. Further, the researchers ensured that the extended vocabulary, including newly introduced latent tokens, could be seamlessly integrated into the model without requiring major modifications.
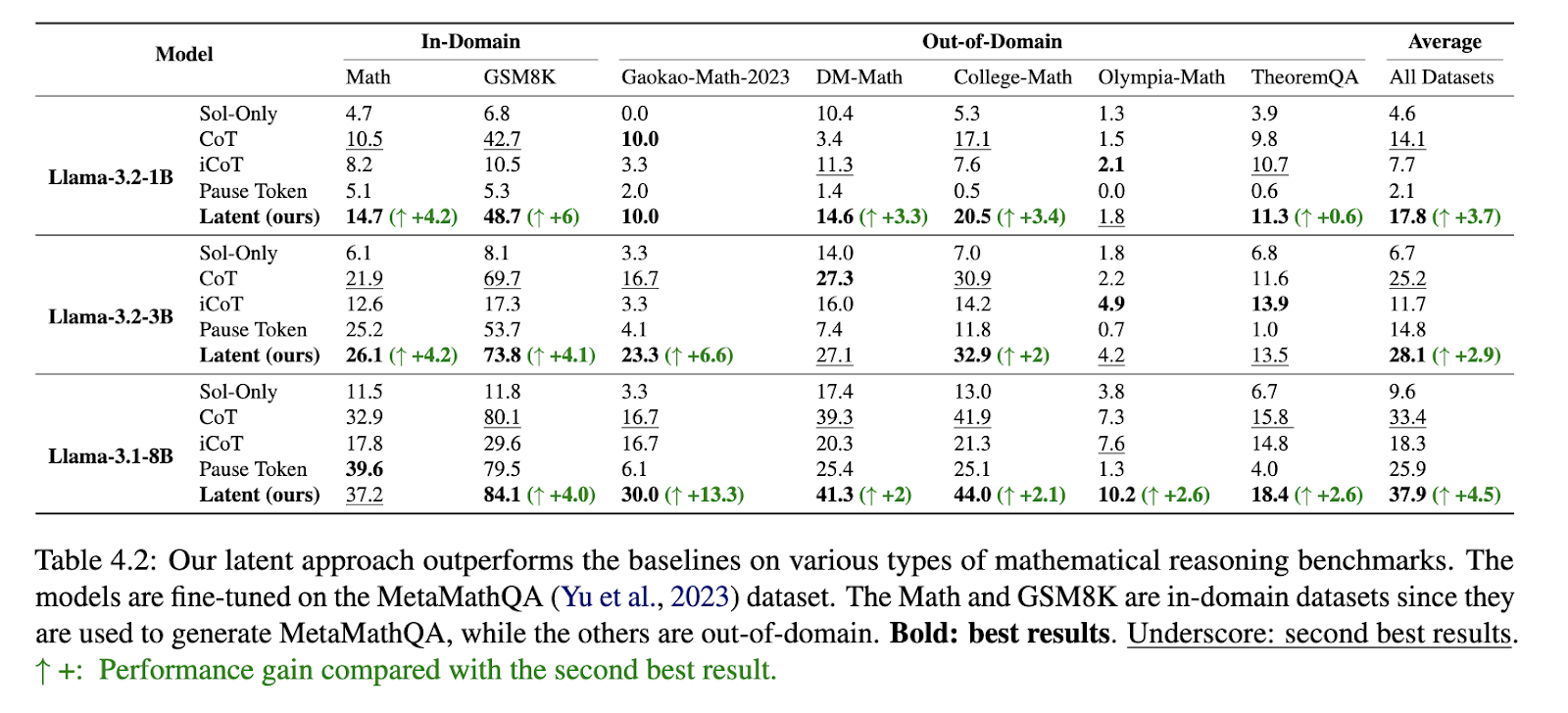
The proposed method demonstrated significant performance improvements across various benchmarks. The approach outperformed traditional chain-of-thought (CoT) models when applied to mathematical reasoning tasks. On the Math dataset, it achieved a 4.2% improvement over previous best-performing methods. In the GSM8K benchmark, the approach yielded a 4.1% gain, while in the Fresh-Gaokao-Math-2023 dataset, it outperformed existing models by 13.3%. The reduction in reasoning trace length was equally noteworthy, with an average decrease of 17%, which resulted in faster inference times and lower memory consumption. Evaluations on logical reasoning datasets such as ProntoQA and ProsQA further validated the approach’s effectiveness, with accuracy improvements of 1.2% and 18.7%, respectively. The model achieved 100% accuracy on simpler reasoning tasks, demonstrating its capacity for efficient logical deduction.
The introduction of latent tokens has provided a significant step forward in optimizing LLM reasoning without compromising accuracy. By reducing the dependence on full-text reasoning sequences and leveraging discrete latent representations, the researchers have developed an approach that maintains efficiency while improving model generalization. The hybrid structure ensures that essential reasoning components are preserved, offering a practical solution to the challenge of balancing interpretability and computational efficiency. As LLMs continue to evolve, such methods may pave the way for more resource-efficient artificial intelligence systems that retain high levels of reasoning capability.
Check out the Technical details. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.
The post This AI Paper Introduces a Latent Token Approach: Enhancing LLM Reasoning Efficiency with VQ-VAE Compression appeared first on MarkTechPost.
