


Understanding videos with AI requires handling sequences of images efficiently. A major challenge in current video-based AI models is their inability to process videos as a continuous flow, missing important motion details and disrupting continuity. This lack of temporal modeling prevents tracing changes; therefore, events and interactions are partially unknown. Long videos also make the process difficult, with high computational expenses and requiring techniques like frame skipping, which loses valuable information and reduces accuracy. Overlap among data within frames also does not compress well, resulting in redundancy and wastage of resources.
Currently, video-language models treat videos as static frame sequences with image encoders and vision-language projectors, which is challenging to represent motion and continuity. Language models have to infer temporal relations independently, resulting in partial comprehension. Subsampling of frames reduces the computational load at the expense of removing useful details, affecting accuracy. Token reduction methods like recursive KV cache compression and frame selection add complexity without yielding much improvement. Though advanced video encoders and pooling methods assist, they remain inefficient and not scalable, rendering long-video processing computationally intensive.

To address these challenges, researchers from NVIDIA, Rutgers University, UC Berkeley, MIT, Nanjing University, and KAIST proposed STORM (Spatiotemporal Token Reduction for Multimodal LLMs), a Mamba-based temporal projector architecture for efficient processing of long videos. Unlike traditional methods, where temporal relations are inferred separately on each video frame, and language models are utilized for inferring the temporal relations, STORM adds temporal information at the video tokens level to eliminate computation redundancy and enhance efficiency. The model improves video representations with a bidirectional spatiotemporal scanning mechanism while mitigating the burden of temporal reasoning from the LLM.
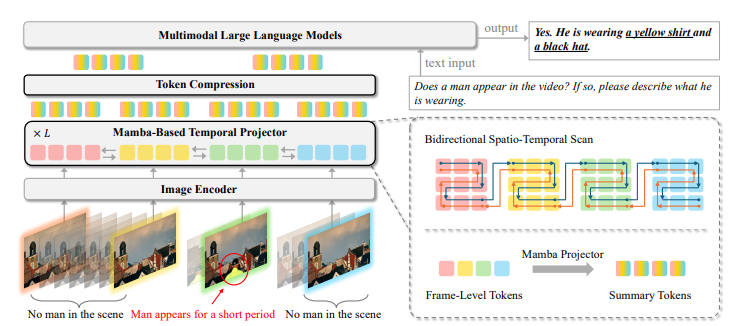
The framework uses Mamba layers to enhance temporal modeling, incorporating a bidirectional scanning module to capture dependencies across spatial and temporal dimensions. The temporal encoder processes the image and video inputs differently, acting as a spatial scanner for images to integrate global spatial context and as a spatiotemporal scanner for videos to capture temporal dynamics. During training, token compression techniques improved computational efficiency while maintaining essential information, allowing inference on a single GPU. Training-free token subsampling at test time reduced computational burdens further while retaining important temporal details. This technique facilitated efficient processing of long videos without requiring specialized equipment or deep adaptations.
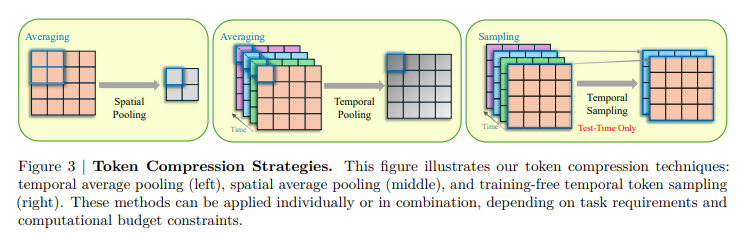
Experiments were conducted to evaluate the STORM model for video understanding. Training was performed using pre-trained SigLIP models, with a temporal projector introduced through random initialization. The process involved two stages: an alignment stage, where the image encoder and LLM were frozen while only the temporal projector was trained using image-text pairs, and a supervised fine-tuning stage (SFT) with a diverse dataset of 12.5 million samples, including text, image-text, and video-text data. Token compression methods, including temporal and spatial pooling, decreased computational burden. The last model was evaluated on long-video benchmarks such as EgoSchema, MVBench, MLVU, LongVideoBench, and VideoMME, with the performance being compared with other video LLMs.
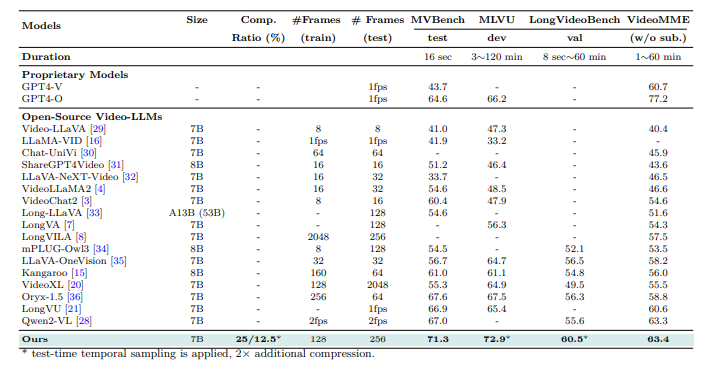
Upon evaluation, STORM outperformed existing models, achieving state-of-the-art results on benchmarks. The Mamba module improved efficiency by compressing visual tokens while retaining key information, reducing inference time by up to 65.5%. Temporal pooling worked best on long videos, optimizing performance with few tokens. STORM also performed greatly better than the baseline VILA model, particularly in tasks that involved understanding the global context. Results verified the significance of Mamba for optimized token compression, with performance boosts rising along with the video length from 8 to 128 frames.
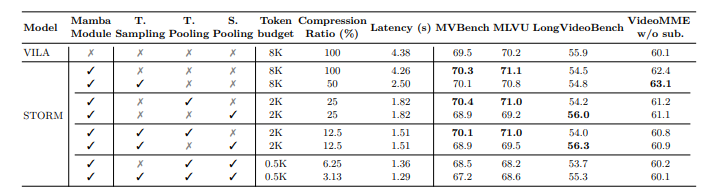
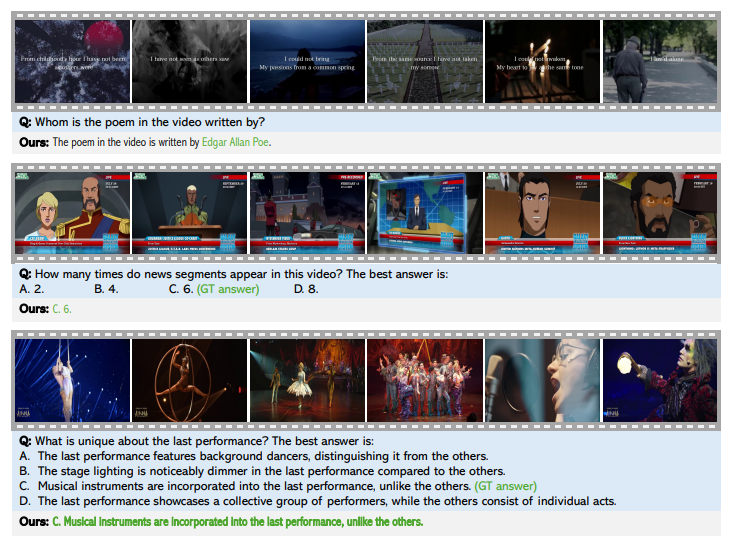
In summary, the proposed STORM model improved long-video understanding using a Mamba-based temporal encoder and efficient token reduction. It enabled strong compression without losing key temporal information, recording state-of-the-art performance on long-video benchmarks while keeping computation low. The method can act as a baseline for future research, facilitating innovation in token compression, multimodal alignment, and real-world deployment to improve video-language model accuracy and efficiency.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.


 It’s operated using an easy-to-use CLI
It’s operated using an easy-to-use CLI  and native client SDKs in Python and TypeScript
and native client SDKs in Python and TypeScript  .
.The post STORM (Spatiotemporal TOken Reduction for Multimodal LLMs): A Novel AI Architecture Incorporating a Dedicated Temporal Encoder between the Image Encoder and the LLM appeared first on MarkTechPost.
