


The main challenge in developing advanced visual language models (VLMs) lies in enabling these models to effectively process and understand long video sequences that contain extensive contextual information. Long-context understanding is crucial for applications such as detailed video analysis, autonomous systems, and real-world AI implementations where tasks require the comprehension of complex, multi-modal inputs over extended periods. However, current models are limited in their ability to handle long sequences, which restricts their performance and usability in tasks requiring deep contextual analysis. This challenge is significant because overcoming it would unlock the potential for AI systems to perform more sophisticated tasks in real time and across various domains.
Existing methods designed to handle long-context vision-language tasks often encounter scalability and efficiency issues. Approaches such as Ring-Style Sequence Parallelism and Megatron-LM have extended context length in language models but struggle when applied to multi-modal tasks that involve both visual and textual data. These methods are hindered by their computational demands, making them impractical for real-time applications or tasks requiring the processing of very long sequences. Additionally, most visual language models are optimized for short contexts, limiting their effectiveness for longer video sequences. These constraints prevent AI models from achieving the necessary performance levels in tasks that demand extended context understanding, such as video summarization and long-form video captioning.
A team of researchers from NVIDIA, MIT, UC Berkeley, and UT Austin proposes LongVILA, an innovative approach that offers a full-stack solution for long-context visual language models. LongVILA introduces the Multi-Modal Sequence Parallelism (MM-SP) system, which significantly enhances the efficiency of long-context training and inference by enabling models to process sequences up to 2 million tokens in length using 256 GPUs. This system is more efficient than existing methods, achieving a 2.1× – 5.7× speedup compared to Ring-Style Sequence Parallelism and a 1.1× – 1.4× improvement over Megatron-LM. The novelty of LongVILA lies in its ability to scale context length while seamlessly integrating with frameworks like Hugging Face Transformers. The five-stage training pipeline further enhances the model’s capabilities, focusing on multi-modal alignment, large-scale pre-training, context extension, and supervised fine-tuning, leading to substantial performance improvements on long video tasks.
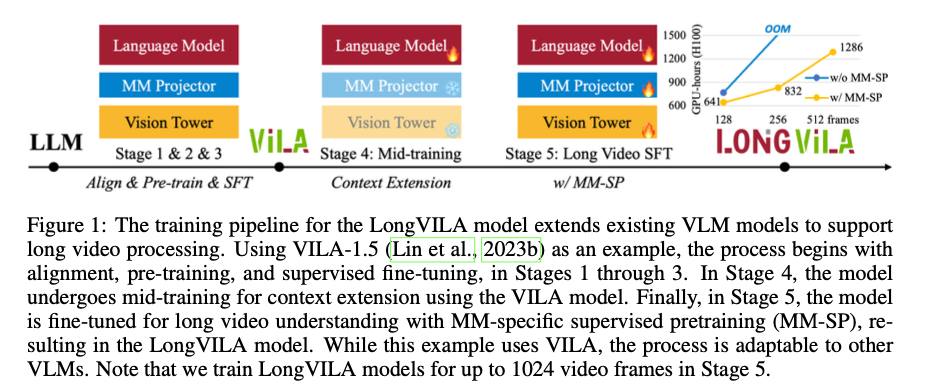
The foundation of LongVILA is the MM-SP system, designed to handle the training and inference of long-context VLMs by distributing computational loads across multiple GPUs. The system employs a two-stage sharding strategy that ensures balanced processing of both the image encoder and the language modeling stages. This strategy is crucial for efficiently handling the diverse data types involved in multi-modal tasks, particularly when processing extremely long video sequences. The training pipeline is composed of five stages: multi-modal alignment, large-scale pre-training, short-supervised fine-tuning, context extension, and long-supervised fine-tuning. Each stage incrementally extends the model’s capability from handling short contexts to processing long video sequences with up to 1024 frames. A new dataset was also developed for long video instruction-following, comprising 15,292 videos, each around 10 minutes long, to support the final supervised fine-tuning stage.
The LongVILA approach achieves substantial improvements in handling long video tasks, particularly in its ability to process extended sequences with high accuracy. The model demonstrated a significant 99.5% accuracy when processing videos with a context length of 274,000 tokens, far exceeding the capabilities of previous models that were limited to shorter sequences. Additionally, LongVILA-8B consistently outperforms existing state-of-the-art models on benchmarks for video tasks of varying lengths, showcasing its superior ability to manage and analyze long video content effectively. The performance gains achieved by LongVILA highlight its efficiency and scalability, making it a leading solution for tasks that require deep contextual understanding over extended sequences.

In conclusion, LongVILA represents a significant advancement in the field of AI, particularly for tasks requiring long-context understanding in multi-modal settings. By offering a comprehensive solution that includes a novel sequence parallelism system, a multi-stage training pipeline, and specialized datasets, LongVILA effectively addresses the critical challenge of processing long video sequences. This method not only improves the scalability and efficiency of visual language models but also sets a new standard for performance in long video tasks, marking a substantial contribution to the advancement of AI research.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 49k+ ML SubReddit
Find Upcoming AI Webinars here
The post Processing 2-Hour Videos Seamlessly: This AI Paper Unveils LONGVILA, Advancing Long-Context Visual Language Models for Long Videos appeared first on MarkTechPost.
