
With the rapid advancements in Large Language Models (LLMs) and Vision-Language Models (VLMs), many believe OCR has become obsolete. If LLMs can "see" and "read" documents, why not use them directly for text extraction?
The answer lies in reliability. Can you always be a 100% sure of the veracity of text output that LLMs interpret from a document/image? We put this to test with a simple experiment. We asked colleagues to use any LLM of their choice to extract a list of passenger names (10) from a sample PDF flight ticket.
Only NotebookLM and Deepseek got the list of names completely right!
While LLMs can interpret and summarize documents, they lack the precision and structured output required for critical business applications where 100% data accuracy is crucial. Additionally, LLMs require significant computational resources, making them costly and impractical for large-scale document processing, especially in enterprise and edge deployments.
OCR, on the other hand, is optimized for efficiency, running on low-power devices while delivering consistent results. When accuracy is non-negotiable whether in financial records, legal contracts, or regulatory compliance, OCR remains the most dependable solution.
Unlike LLMs, OCR APIs provide confidence scores and bounding boxes, allowing developers to detect uncertainties in extracted text. This level of control is crucial for businesses that cannot afford incorrect or hallucinated data. That’s why OCR APIs continue to be widely used in document automation workflows, AI-driven data extraction, and enterprise applications.
To assess the state of OCR in 2025, we benchmarked nine of the most popular OCR APIs, covering commercial solutions, open-source OCR engines, and document processing frameworks. Our goal is to provide an objective, data-driven comparison that helps developers and enterprises choose the best tool for their needs.
Methodology
Dataset Selection:
To ensure a comprehensive evaluation of OCR APIs or OCR models in real-world scenarios, we selected datasets that encompass a diverse range of document types and challenges commonly encountered in practical applications. Our dataset choices include:
- Common Business Documents: Forms, invoices, and financial statements containing structured text.Receipts: Printed transaction slips with varying fonts, noise, and faded text.Low-Resolution Images: Documents captured under suboptimal conditions, mimicking real-world scanning and photography limitations.Handwritten Text: Samples with different handwriting styles to test handwriting recognition capabilities.Blurred or Distorted Text: Images with motion blur or compression artifacts to assess OCR robustness.Rotated or Skewed Text: Documents scanned or photographed at an angle, requiring advanced text alignment handling.Tabular Data: Documents containing structured tabular information, challenging for OCR models to preserve layout integrity.Dense Text: Text-heavy documents, such as account opening forms, to evaluate performance in high-content areas.
To ensure our benchmark covers all these real-world challenges, we select the following datasets:
- STROIE (link to dataset)

- FUNSD (link to dataset)
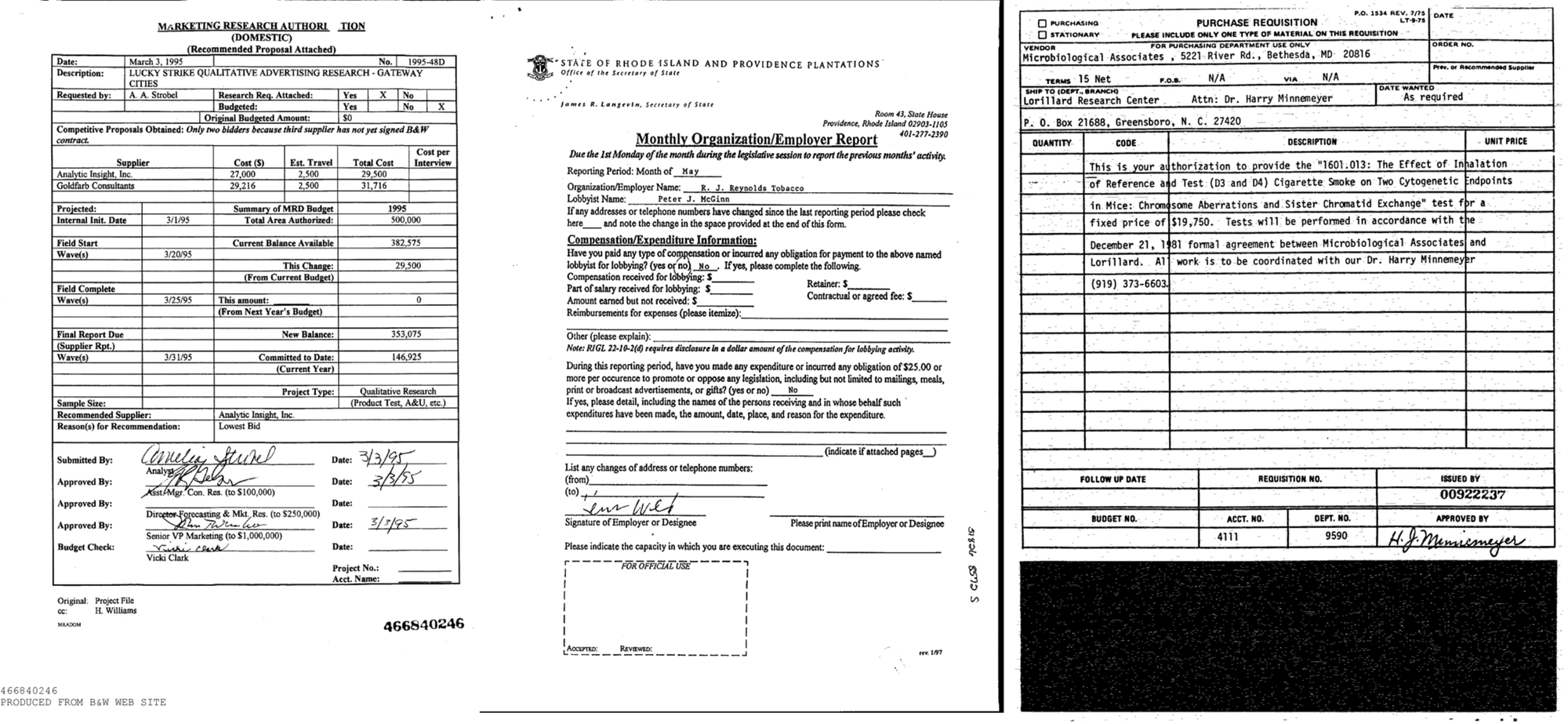
These datasets provide a comprehensive testbed for evaluating OCR performance across practical and real life scenarios.
Models Selection
To evaluate OCR performance across different scenarios, we include a mix of commercial APIs, open-source OCR models, and document processing frameworks. This ensures a balanced comparison between proprietary solutions and freely available alternatives. The models used in our benchmark are:
- Popular Commercial OCR APIs:
- Google Cloud Vision AIAzure AI Document IntelligenceAmazon Textract
- SuryaPaddleOCRRapidOCRExtractous
- MarkerUnstructured-IO
To demonstrate how each OCR API processes an image, we provide code snippets for running OCR using both commercial APIs and open-source frameworks. These examples show how to load an image, apply OCR, and extract the text, offering a practical guide for implementation and comparison. Below are the code snippets for each model:
- Google Cloud Vision AI: First step is to set up a new Google Cloud Project. In the Google Cloud Console, navigate to APIs & Services → Library, search for Vision API, and click Enable. Go to APIs & Services → Credentials, click Create Credentials → Service Account, name it (e.g., vision-ocr-service), and click Create & Continue. Assign the Owner (or Editor) role and click Done. Now, in Service Accounts, select the account, go to Keys → Add Key → Create New Key, choose JSON, and download the .json file.
Required Packages:
pip install google-cloud-visionfrom google.cloud import visionfrom google.oauth2 import service_accountcredentials = service_account.Credentials.from_service_account_file("/content/ocr-nanonets-cea4ddeb1dd2.json") #path to the json file downloadedclient = vision.ImageAnnotatorClient(credentials=credentials)def detect_text(image_path): """Detects text in an image using Google Cloud Vision AI.""" with open(image_path, 'rb') as image_file: content = image_file.read() image = vision.Image(content=content) response = client.text_detection(image=image) texts = response.text_annotations if texts: return texts[0].description else: return "No text detected." if response.error.message: raise Exception(f"Error: {response.error.message}")# Replace with your image pathimage_path = "/content/drive/MyDrive/OCR_datasets/STROIE/test_data/img/X00016469670.jpg"print(detect_text(image_path))- Azure AI Document Intelligence: Create an Azure Account (Azure Portal) to get $200 free credits for 30 days. In the Azure Portal, go to Create a Resource, search for Azure AI Document Intelligence (Form Recognizer), and click Create. Choose a Subscription, Resource Group, Region (nearest to you), set Pricing Tier to Free (if available) or Standard, then click Review + Create → Create. Once created, go to the Azure AI Document Intelligence resource, navigate to Keys and Endpoint, and copy the API Key and Endpoint.
Required Packages:
pip install azure-ai-documentintelligencefrom azure.ai.documentintelligence import DocumentIntelligenceClientfrom azure.core.credentials import AzureKeyCredentialimport io# Replace with your Azure endpoint and API keyAZURE_ENDPOINT = "https://your-region.api.cognitive.microsoft.com/"AZURE_KEY = "your-api-key"client = DocumentIntelligenceClient(AZURE_ENDPOINT, AzureKeyCredential(AZURE_KEY))def extract_text(image_path): """Extracts text from an image using Azure AI Document Intelligence.""" with open(image_path, "rb") as image_file: image_data = image_file.read() poller = client.begin_analyze_document("prebuilt-read", document=image_data) result = poller.result() extracted_text = [] for page in result.pages: for line in page.lines: extracted_text.append(line.content) print("Detected text:") print("\n".join(extracted_text)) image_path = image_pathextract_text(image_path)- Amazon Textract: Create an AWS Account (AWS Sign-Up) to access Amazon Textract's free-tier (1,000 pages/month for 3 months). In the AWS Management Console, go to IAM (Identity & Access Management) → Users → Create User, name it (e.g., textract-user), and select Programmatic Access. Under Permissions, attach AmazonTextractFullAccess and AmazonS3ReadOnlyAccess (if using S3). Click Create User and copy the Access Key ID and Secret Access Key.
Required Packages:
pip install boto3Set Environment Variables:
export AWS_ACCESS_KEY_ID="your-access-key"export AWS_SECRET_ACCESS_KEY="your-secret-key"export AWS_REGION="your-region"import boto3textract = boto3.client("textract", region_name="us-east-1")def extract_text(image_path): """Extracts text from an image using Amazon Textract.""" with open(image_path, "rb") as image_file: image_bytes = image_file.read() response = textract.detect_document_text(Document={"Bytes": image_bytes}) extracted_text = [] for item in response["Blocks"]: if item["BlockType"] == "LINE": extracted_text.append(item["Text"]) print("Detected text:") print("\n".join(extracted_text)) image_path = image_pathextract_text(image_path)- Surya : Use pip install surya-ocr to download the necessary packages. Then create a python file with the following code and run it in terminal.
from PIL import Imagefrom surya.recognition import RecognitionPredictorfrom surya.detection import DetectionPredictorimage = Image.open(image_path)langs = ["en"]recognition_predictor = RecognitionPredictor()detection_predictor = DetectionPredictor()predictions = recognition_predictor([image], [langs], detection_predictor)- PaddleOCR : Use “pip install paddleocr paddlepaddle” to install the required packages. Then create a python file with the following code and run it in terminal.
from paddleocr import PaddleOCRocr = PaddleOCR(use_angle_cls=True, lang="en")result = ocr.ocr(image_path, cls=True)- RapidOCR : Use “pip install rapidocr_onnxruntime” to install the required packages. Then create a python file with the following code and run it in terminal.
from rapidocr_onnxruntime import RapidOCRengine = RapidOCR()img_path = image_pathresult, elapse = engine(img_path)- Extractous: Use “sudo apt install tesseract-ocr tesseract-ocr-deu” to install the required packages. Then create a python file with the following code and run it in terminal.
from extractous import Extractor, TesseractOcrConfigextractor = Extractor().set_ocr_config(TesseractOcrConfig().set_language("en"))result, metadata = extractor.extract_file_to_string(image_path)print(result)- Marker: Use “pip install marker-pdf” to install the required packages. Then in terminal use the following code.
!marker_single image_path --output_dir saving_directory --output_format json- Unstructured-IO: Use “pip install "unstructured[image]"” to install the required packages. Then create a python file with the following code and run it in terminal.
from unstructured.partition.auto import partitionelements = partition(filename=image_path)print("\n\n".join([str(el) for el in elements]))Evaluation Metrics
To assess the effectiveness of each OCR model, we evaluate both accuracy and performance using the following metrics:
- Character Error Rate (CER): Measures the ratio of incorrect characters (insertions, deletions, and substitutions) to the total characters in the ground truth text. Lower CER indicates better accuracy.Word Error Rate (WER): Similar to CER but operates at the word level, calculating errors relative to the total number of words. It helps assess how well models recognize complete words.ROUGE Score: A text similarity metric that compares OCR output with the ground truth based on overlapping n-grams, capturing both precision and recall.
For performance evaluation, we measure:
- Inference Time (Latency per Image): The time taken by each model to process a single image, indicating speed and efficiency in real-world applications.
Cost Evaluation:
- For commercial OCR APIs, cost is determined by their pricing models, typically based on the number of processed pages or images. For open-source OCR APIs, while there are no direct usage costs, we assess computational overhead by measuring memory usage during inference.
Benchmarking Results
Since the datasets used—STROIE (different receipt images) and FUNSD (business documents with tabular layouts)—contain diverse layout styles, the extracted text varies across models based on their ability to preserve structure. This variation affects the Word Error Rate (WER) and Character Error Rate (CER), as these metrics depend on the position of words and characters in the output.
A high error rate indicates that a model struggles to maintain the chronological order of text, especially in complex layouts and tabular formats.
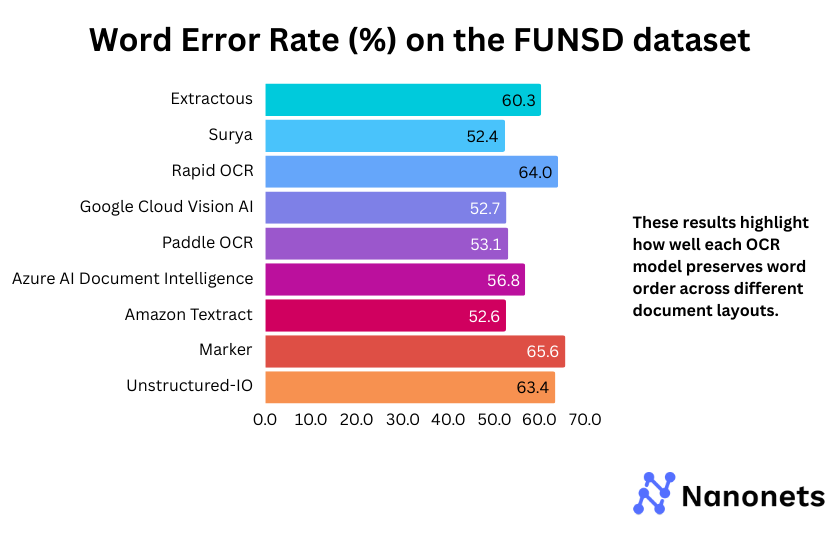
1. Word Error Rate
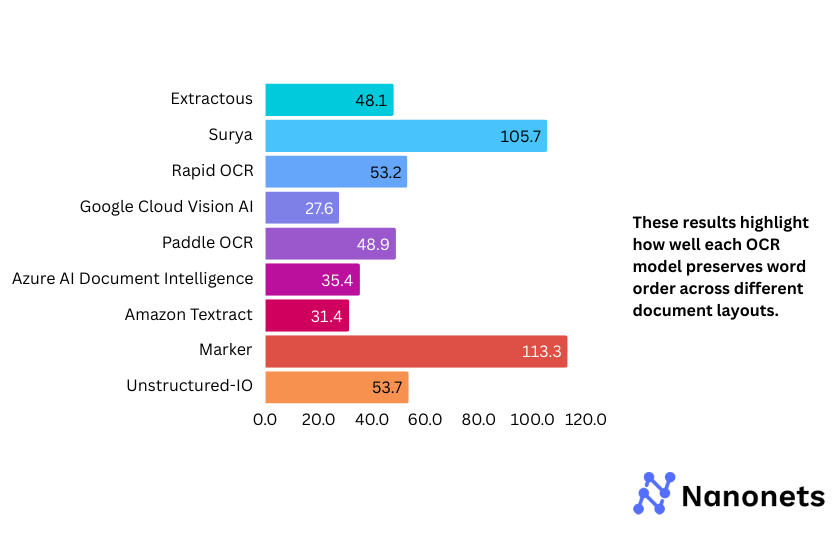
WER of each model on the FUNSD and STROIE datasets is presented below. These results highlight how well each model preserves word order across different document layouts.
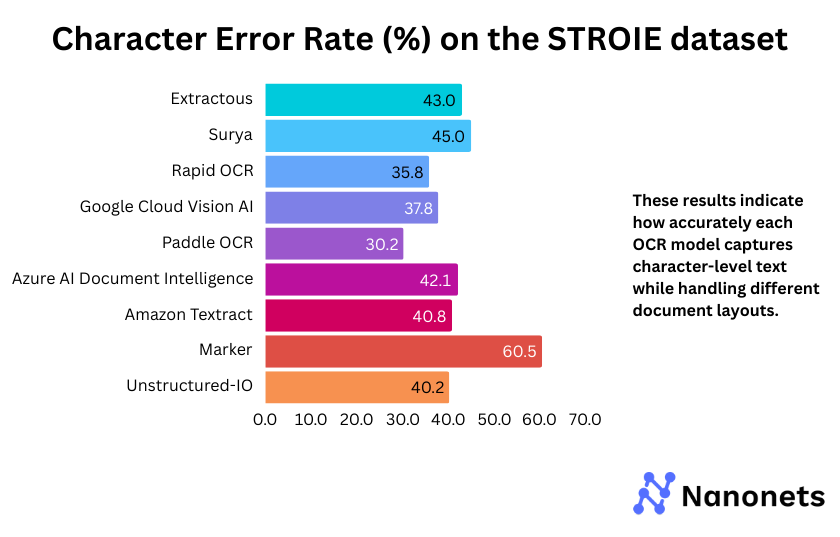
2. Character Error Rate
CER of each model on the FUNSD and STROIE datasets is presented below. These results indicate how accurately each model captures character-level text while handling different document layouts.
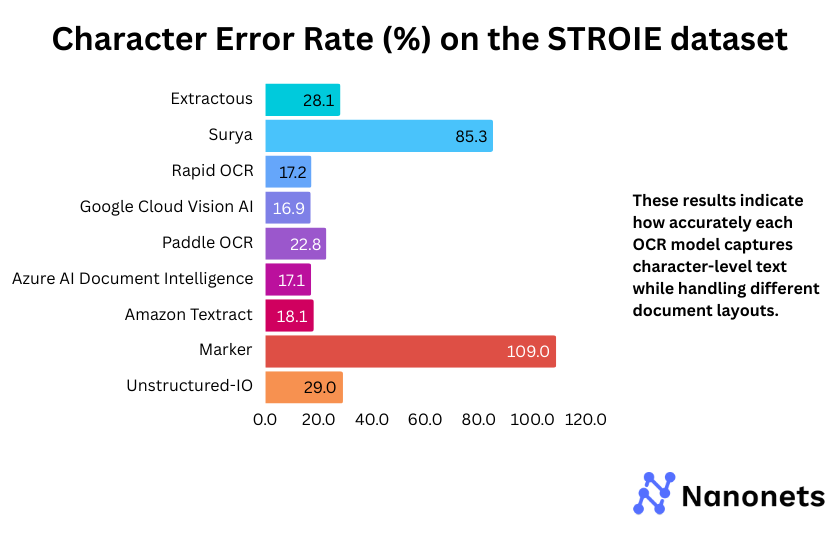
Why are the WER and CER metrics for Surya and Marker so high on the STROIE dataset?
STROIE’s intricate layouts make OCR difficult. Surya tries to fill gaps by inserting extra words, leading to high WER and CER, even after post-processing. Marker, which uses Surya for OCR and outputs markdown text, inherits these issues. The markdown formatting further misaligns text, worsening the error rates.
Variation in Model Performance Across Datasets
OCR models perform differently based on dataset structure. Google Cloud Vision AI and Azure AI Document Intelligence handle diverse layouts better, while open-source models like RapidOCR and Surya struggle with structured formats, leading to more errors.
Since the models struggle to preserve layouts, leading to high WER and CER, we use another metric—ROUGE Score—to assess text similarity between the model's output and the ground truth. Unlike WER and CER, ROUGE focuses on content similarity rather than word position. This means that regardless of layout preservation, a high ROUGE score indicates that the extracted text closely matches the reference, while a low score suggests significant content discrepancies.
3. ROUGE Score
ROUGE Score of each model on the FUNSD and STROIE datasets is presented below. These results reflect the content similarity between the extracted text and the ground truth, regardless of layout preservation.
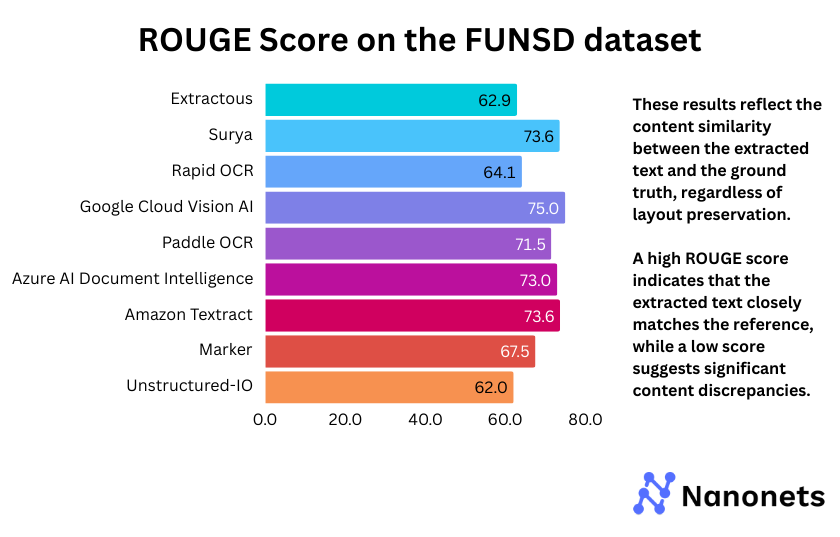
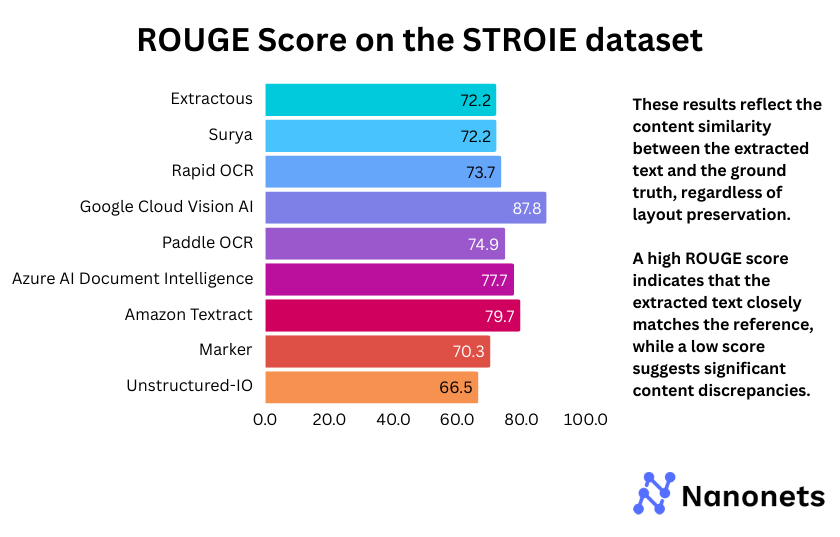
The ROUGE scores reveal that Google Cloud Vision AI consistently outperforms other models across both FUNSD (75.0%) and STROIE (87.8%), indicating superior text extraction. Surya and Marker, which rely on the same backend, show comparable performance, though Marker slightly lags on STROIE (70.3%). Extractous and Unstructured-IO score the lowest in both datasets, suggesting weaker text coherence. PaddleOCR and Azure AI Document Intelligence achieve balanced results, making them competitive alternatives. The overall trend highlights the strength of commercial APIs, while open-source models exhibit mixed performance.
4. Latency per image
Latency per image for each model is presented below. This measures the time taken by each model to perform OCR on one image, providing insights into their efficiency and processing speed.
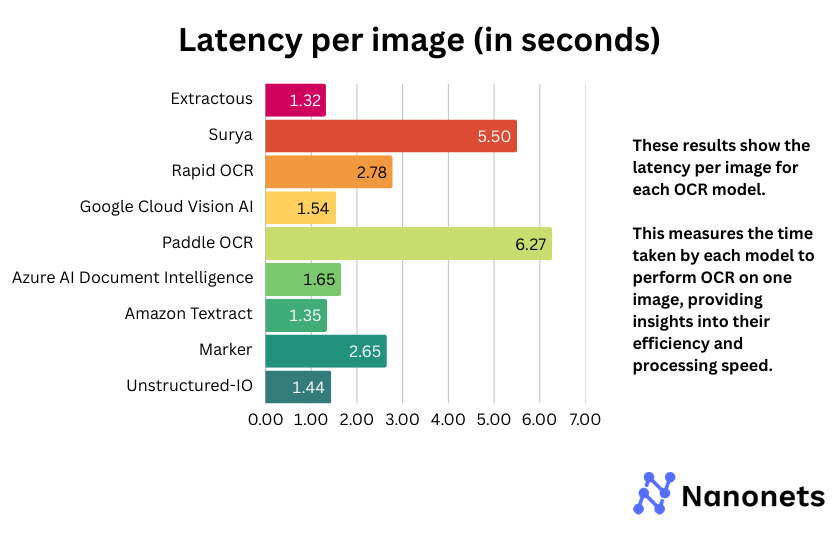
The latency analysis shows that Google Cloud Vision AI, Amazon Textract, and Extractous maintain a good balance between speed and accuracy. Surya and Paddle OCR exhibit notably higher inference times, suggesting potential inefficiencies. Open-source models like Rapid OCR and Marker vary in performance, with some offering competitive speeds while others lag behind. Azure AI Document Intelligence also shows moderate latency, making it a viable choice depending on the use case.
5. Cost or memory usage per image
For commercial APIs, we present the usage cost (cost per 1000 images processed). For open-source models, the metric indicates memory consumption as a proxy for cost, providing insights into their resource efficiency.
| OCR API | Cost per 1,000 Pages |
|---|---|
| Google Cloud Vision AI | $1.50 |
| Amazon Textract | $1.50 |
| Azure AI Document Intelligence | $0.50 |
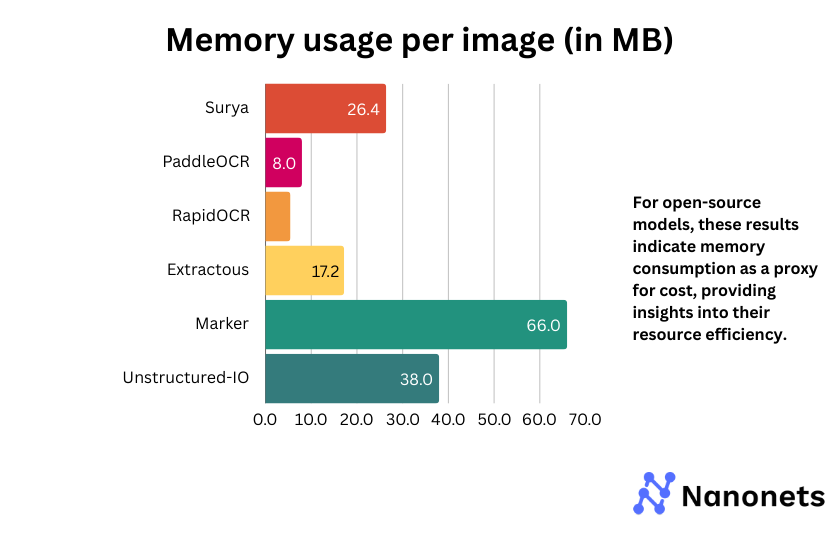
Among open-source models, Marker and Unstructured-IO have significantly higher memory consumption, which may impact deployment in resource-constrained environments. Surya and Extractous strike a balance between performance and memory efficiency. PaddleOCR and RapidOCR are the most lightweight options, making them ideal for low-memory scenarios.
Conclusion
Based on the evaluation across latency, inference time, and ROUGE score, no single model dominates in all aspects. However, some models stand out in specific areas:
- Best Latency & Inference Time: Extractous and Amazon Textract demonstrate the fastest response times, making them ideal for real-time applications.Best ROUGE Score (Accuracy): Google Cloud Vision AI and Azure AI Document Intelligence achieve the highest accuracy in text recognition, making them strong candidates for applications requiring precise OCR.Best Memory Efficiency: RapidOCR and PaddleOCR consume the least memory, making them highly suitable for low-resource environments.
Best Model Overall
Considering a balance between accuracy, speed, and efficiency, Google Cloud Vision AI emerges as the best overall performer. It provides strong accuracy with competitive inference time. However, for open sourced models, PaddleOCR and RapidOCR offer the best trade-off between accuracy, speed and memory efficiency.
Leaderboard of Best OCR APIs based on different performance metrics:
| Metric | Best Model | Score / Value |
|---|---|---|
| Highest Accuracy (ROUGE Score) | Google Cloud Vision AI | Best ROUGE Score |
| Best Layout Handling (Least WER & CER) | Google Cloud Vision AI | Lowest WER & CER |
| Fastest OCR (Lowest Latency) | Extractous | Lowest Processing Time |
| Memory Efficient | RapidOCR | Least Memory Usage |
| Most Cost-Effective among Commercial APIs | Azure AI Document Intelligence | Lowest Cost Per Page |
LLM vs. Dedicated OCR: A Case Study
To understand how OCR models compare to Large Language Models (LLMs) in text extraction, we tested a challenging image using both LLaMa 3.2 11B Vision and RapidOCR, a small but dedicated OCR model.

Results:
- LLaMa 3.2 11B Vision
- Struggled with faint text, failing to reconstruct certain words.Misinterpreted some characters and added hallucinated words.Took significantly longer to process the image.Used a lot of compute resources.
- Accurately extracted most of the text despite the difficult conditions.Ran efficiently on very low compute resources.
Is OCR Still Relevant Today?
With the rise of multimodal LLMs capable of interpreting images and text, some believe OCR may become obsolete. However, the reality is more nuanced.
If you or your end customers need to be 100% sure of data you're extracting from documents or images, OCR still is your best bet for now! Confidence scores and bounding boxes from OCR APIs can be used to infer when the output is not reliable.
With LLMs you can never be 100% sure of the veracity of the text output because of hallucinations and the lack of confidence scores.
Who Still Needs OCR?
- Enterprises Handling High-Volume Documents: Banks, legal firms, and insurance companies rely on OCR for automated document processing at scale.Governments and Compliance: Passport scanning, tax records, and regulatory filings still require OCR for structured extraction.AI-Powered Data Pipelines: Many businesses integrate OCR with NLP pipelines to convert documents into structured data before applying AI models.Multilingual and Low-Resource Language Applications: OCR remains essential for digitizing rare scripts where LLMs lack training data.
Why Should Enterprises Still Care About OCR When Everyone Wants LLMs?
- Accuracy and Reliability: LLMs generate hallucinations, while OCR ensures precise text extraction, making it critical for legal, financial, and government applications.Speed and Cost Efficiency: OCR is lightweight and works on edge devices, while LLMs require high compute resources and cloud inference costs.The future is not OCR vs. LLMs—it is OCR and LLMs: OCR can extract clean text, and LLMs can then process and interpret it for insights. AI-powered OCR models will continue to improve, integrating LLM reasoning for better post-processing.
Final Thoughts
While LLMs have expanded the possibilities of text extraction from images, OCR remains indispensable for structured, high-accuracy text retrieval and will always be crucial for reliable document processing. Rather than replacing OCR, LLMs will complement it, bringing better understanding, context, and automation to extracted data.
