
Building AI Apps on Postgres? Start with pgai (Sponsored)

pgai is a PostgreSQL extension that brings more AI workflows to PostgreSQL, like embedding creation and model completion. pgai empowers developers with AI superpowers, making it easier to build search and retrieval-augmented generation (RAG) applications. Automates embedding creation with pgai Vectorizer, keeping your embeddings up to date as your data changes—no manual syncing required. Available free on GitHub or fully managed in Timescale Cloud.
Disclaimer: The details in this post have been derived from Uber Engineering Blog and other sources. All credit for the technical details goes to the Uber engineering team. The links to the original articles are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
In the early days, the engineers at Uber had to take care of databases and storage systems manually. Whenever they needed to set up, update, or fix something, they followed written instructions called "runbooks". These runbooks were like a step-by-step guide.
As Uber grew, this manual process became overwhelming. They had thousands of databases spread globally, and managing them by hand was a slow and difficult process prone to mistakes.
To solve this, Uber created Odin, an automated system that manages all these databases and storage clusters without human intervention. Unlike older systems that work with only specific types of databases, Odin is technology-agnostic, meaning it can handle many different databases and storage systems seamlessly.
Odin helps Uber’s engineers organize, scale, and maintain their storage infrastructure, ensuring everything runs smoothly and reliably. In this article, we will look at a comprehensive breakdown of Odin and the challenges Uber faced while developing it.
The Scale of Odin
Since 2014, Uber’s data infrastructure has expanded at an unprecedented scale.
What started with a few hundred hosts has now evolved into a massive fleet of over 100,000 hosts, supporting a huge number of stateful workloads.
These workloads are essential for Uber’s real-time services, including ride-hailing, food delivery, and payment processing, all of which depend on highly available and scalable storage solutions.
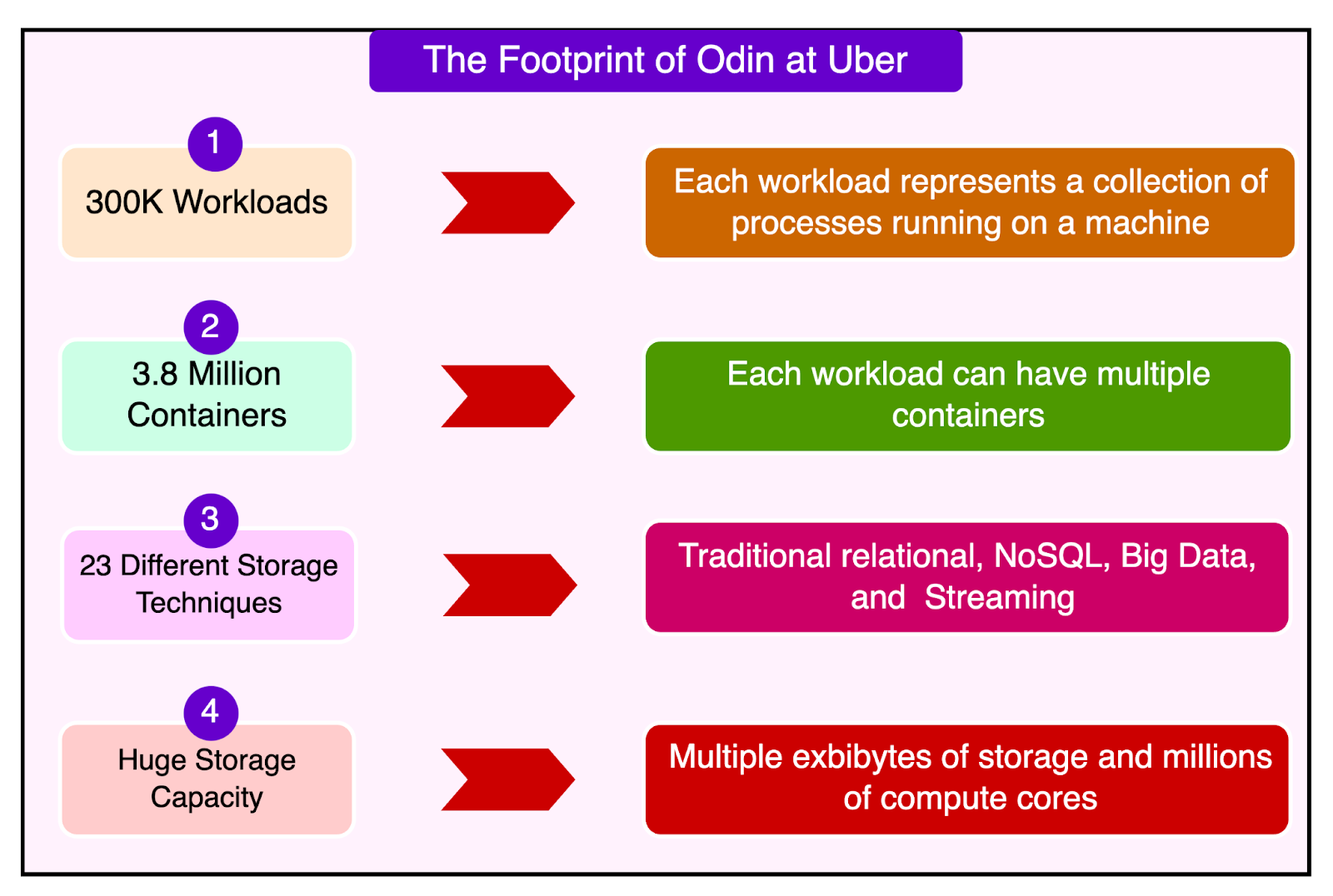
As per an estimate, Uber’s fleet collectively manages multiple exbibytes of storage. To put this into perspective 1 exbibyte equals 1,152,921.5 terabytes (TB). Multiple exbibytes place Uber’s storage in the zettabyte-scale range.
This level of storage capacity is necessary because Uber generates massive volumes of real-time data, such as:
Ride and trip history
GPS tracking logs
User profiles and payment transactions
Machine learning models
Operational logs.
Odin allows Uber to manage this enormous ecosystem through automation, self-healing mechanisms, and efficient resource scheduling. It is responsible for handling:
300,000 workloads, where each workload represents a collection of processes running on a machine, similar to Kubernetes pods.
3.8 million individual containers, which means each workload can have multiple containers running different components of Uber’s stateful services.
In essence, Odin optimizes how storage is allocated and accessed to ensure fast read/write performance while preventing unnecessary duplication and inefficiency. Odin is also technology-agnostic, meaning it doesn’t just manage a single type of database or storage system but instead integrates with 23 different storage technologies, including:
Traditional Online Databases such as MySQL (relational) and Cassandra (distributed NoSQL database)
Big Data and Streaming Platforms such as HDFS, Kafka, and Presto
Resource Scheduling and Workflow Management such as Yarn and Buildkite
Each of these technologies serves a specific purpose within Uber’s ecosystem, and Odin ensures they can all operate efficiently within the same unified infrastructure. For example:
MySQL and Cassandra require high availability and read/write consistency, so Odin ensures replicas are correctly placed and synchronized.
Kafka requires high-throughput storage and low-latency access, so Odin manages partition distribution across nodes.
HDFS and Presto require large-scale batch processing, so Odin makes sure that storage resources are efficiently utilized.
Odin’s Architecture and Design Principles
Unlike traditional imperative systems that require explicit commands to perform tasks, Odin follows a declarative model where engineers define what the system should look like (goal state) rather than how to achieve it.
To maintain the goal state, Odin employs self-healing remediation loops that continuously monitor the system state and detect deviations. If any deviation is found, it takes corrective actions automatically without human intervention.
See the diagram below that shows the steps within Odin’s remediation loop.
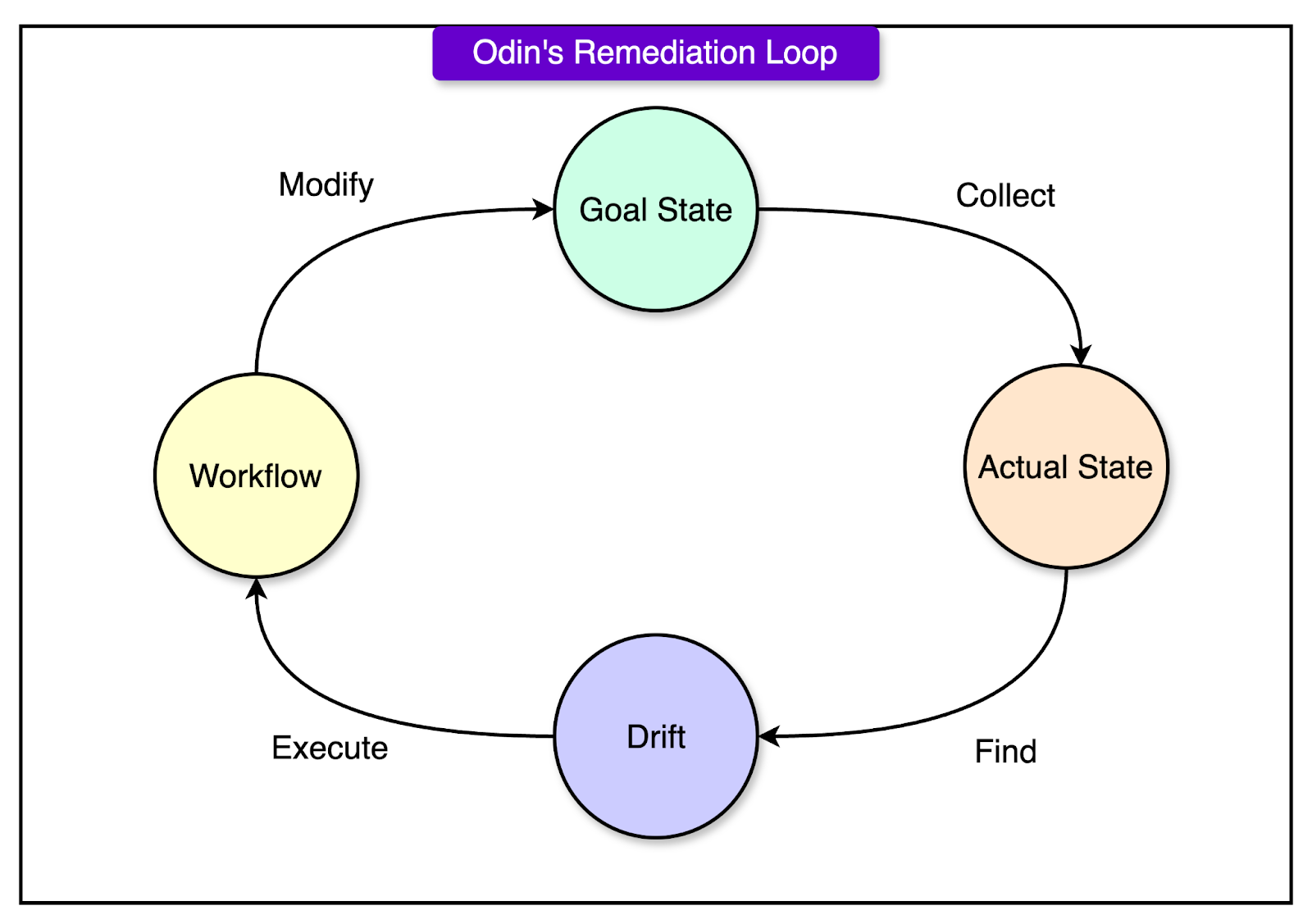
For example, an engineer defines that a database should always have three replicas. Odin automatically ensures this is always the case. If a replica fails or a node crashes, Odin self-heals by spinning up a new instance to meet the goal state.
This design is similar to Kubernetes but optimized for stateful workloads such as databases and large-scale storage systems.
The diagram below shows a high-level view of Odin’s architecture.
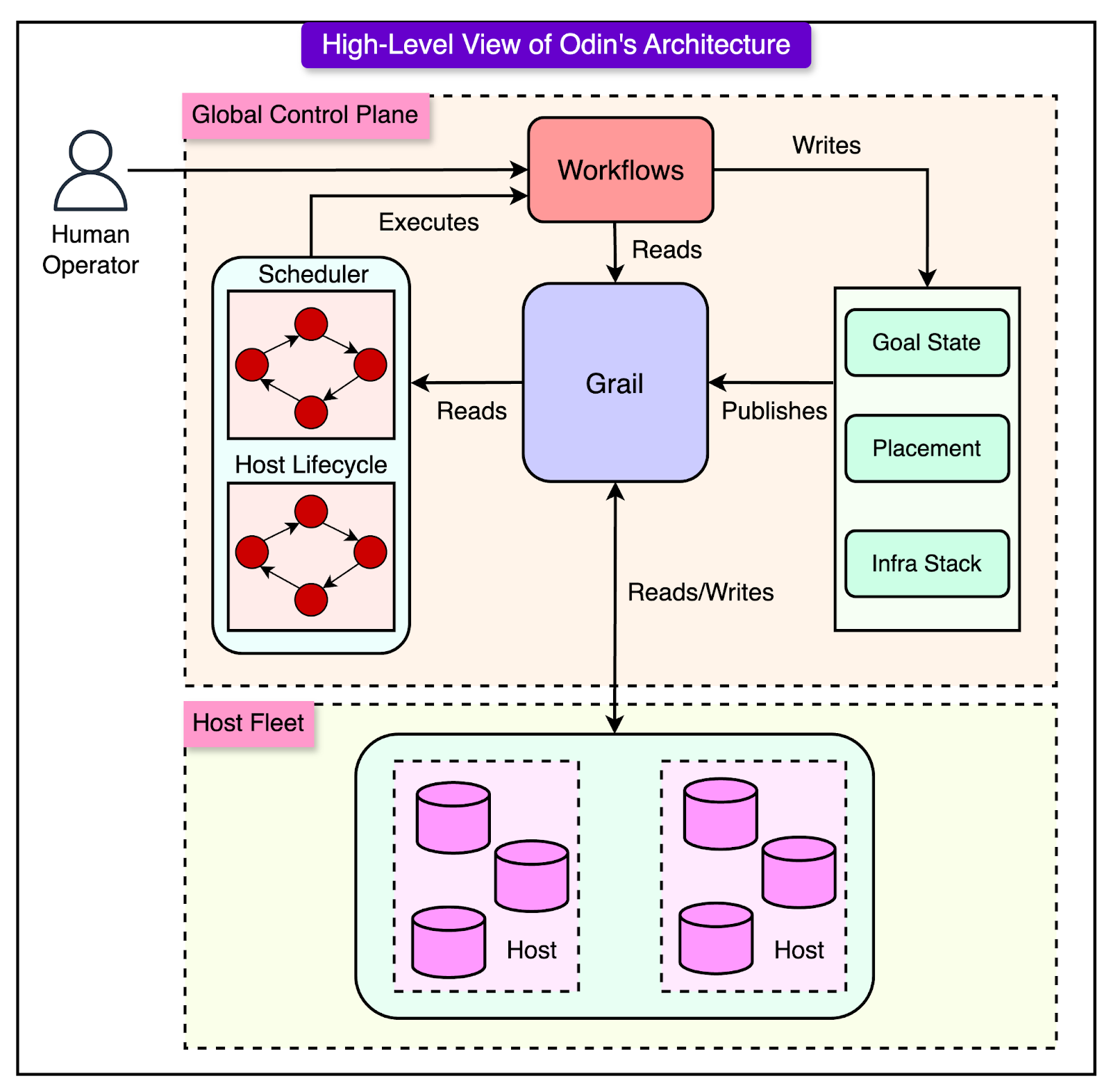
The key architectural components of Odin are as follows:
1 - Grail: The Data Integration Platform
Odin’s intelligence depends on having an accurate and up-to-date view of Uber’s global infrastructure. This is handled by Grail.
Grail provides a real-time snapshot of all hosts, containers, and workloads across Uber’s infrastructure. It works similarly to the Kubernetes API Server but at a much larger scale. It allows engineers and remediation loops to query global system state instantly, enabling informed scheduling and decision-making.
The key advantages of Grail are as follows:
Operates across tens of thousands of hosts in multiple data centers and cloud regions.
Works with all storage technologies managed by Odin.
Unlike traditional database monitoring tools that operate per data center, Grail aggregates data across all Uber locations.
2 - Remediation Loops
At the core of Odin’s automation capabilities are remediation loops.
Each remediation loop is a separate microservice. This allows independent development and deployment without affecting other parts of the system. It follows a four-step cycle:
Inspect the goal state (what the system should look like).
Collect the actual state (what the system currently looks like).
Identify discrepancies between the goal and the actual state.
Trigger corrective actions using Cadence workflows.
This process is continuous, ensuring that Odin actively maintains stability and performance.
3 - The Control Plane
Odin’s control plane is responsible for orchestrating workloads, scheduling tasks, and managing cluster topology.
The core responsibilities of the Control Plane are as follows:
Workload Scheduling: It decides where and how workloads should be deployed based on system health, resource availability, and performance needs.
Cluster Management and Topology Decisions: Determines how databases and storage clusters should be distributed across Uber’s infrastructure.
Workflow Execution (via Cadence): Engineers interact with the control plane through Cadence workflows. These workflows define specific actions, such as upgrading a database or rescheduling workloads.
4 - Host-Level Agents
Odin’s architecture separates global control from local execution using two host-level agents.
Odin-Agent: This runs on every host in Uber’s infrastructure and handles generic host-level tasks, such as resource allocation (CPU, memory, and disk), container lifecycle management, and disk volume and cgroup management.
Technology-Specific Worker: A containerized agent that runs inside each database or storage workload. It is tailored to the specific technology being used (for example, MySQL and Cassandra). This agent ensures that the database internals align with the goal state.
See the diagram below that shows the two host-level agents in more detail.
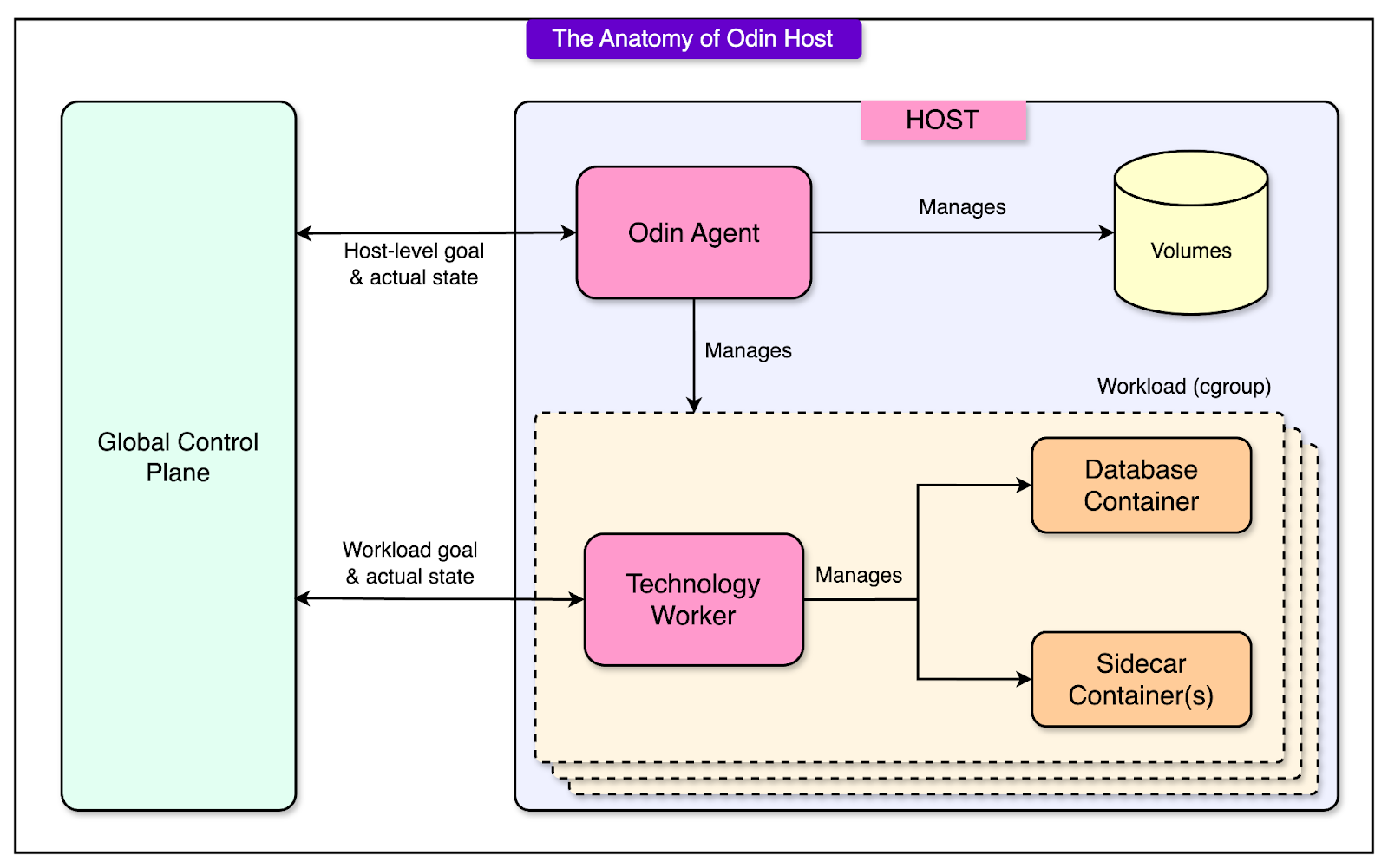
By separating general host management (Odin-Agent) from database-specific logic (Worker), Odin maintains standardization and customization across different workloads.
Odin’s Key Features and Innovations
As mentioned, Odin is a stateful workload management system designed to handle Uber’s massive-scale database and storage infrastructure.
1 - Self Healing System
Odin continuously compares the desired goal state with the actual state of the system. If a deviation is detected, it automatically triggers corrective actions through Cadence workflows.
No human intervention is required in this process. The system detects and fixes failures autonomously. This eliminates downtime caused by manual debugging. Moreover, Odin constantly fine-tunes itself to maintain optimal performance.
2 - High Availability and Fault Tolerance
Odin ensures high availability through dynamic workload rescheduling and failure-handling mechanisms.
60% of workloads are rescheduled each month to balance resource utilization. Workloads move between hosts dynamically to optimize performance and maintain resilience against failures. Odin makes real-time rescheduling decisions based on resource usage, fault tolerance, and availability requirements.
One of Odin’s key innovations is its make-before-break strategy. Before shutting down a workload, Odin provisions a replacement instance. The old instance is only removed once the new one is fully operational. This approach is important for stateful workloads like databases, where shutting down a node without a replacement can cause data loss, unavailability, or increased latency.
3 - Efficient Storage Management
When Odin was introduced, containerizing databases was still a relatively uncommon and controversial practice. However, Uber fully embraced containerized stateful workloads.
An innovation Odin brought to the table was placing multiple database instances on a single host. Traditionally, databases run on dedicated machines, wasting resources. Odin enables up to 100 databases to be colocated on the same host by managing CPU, memory, and disk allocation.
Unlike traditional NAS-based database solutions, Odin relies on locally attached SSDs and HDDs. This results in lower latency, higher throughput, and reduced costs.
4 - Workload Identity and Stateful Migration
Stateful applications require persistent identity across rescheduling events. Unlike Kubernetes StatefulSets, which assigns a stable pod identity, Odin takes a different approach.
In this approach, workload identity is preserved across rescheduling events. Data replication is performed before workload termination. Goal-state propagation ensures that the new instance picks up exactly where the old one left off. In other words, the workload transition is seamless, with no downtime or loss of service.
Challenges and Optimization Strategies in Odin
Managing a platform as large as Odin comes with significant engineering challenges.
As Uber scaled, Odin had to evolve from a human-driven system to a fully automated, highly coordinated, and resilient infrastructure management platform.
Some key takeaways are as follows:
The manual workload management was no longer scalable. Fleet-wide optimizations were needed for resiliency, cost savings, upgrades, and data center migrations.
Uncoordinated operations (like workload migrations and container upgrades) could take down clusters. Consensus-based databases needed careful migration strategies.
A global coordination system was needed to solve these problems. This was done using predefined budgets for allowable disruptions and enforcing platform-wide global concurrency constraints.
Conclusion
Odin represents a significant leap in stateful workload management, enabling Uber to scale its infrastructure from hundreds to over 100,000 hosts while maintaining high availability, cost efficiency, and operational stability.
By transitioning from manual, human-driven operations to an intent-based, self-healing, and automated orchestration system, Odin has eliminated inefficiencies and minimized downtime in Uber’s mission-critical storage systems.
The key innovations behind Odin, such as self-healing remediation loops, intelligent workload rescheduling, make-before-break migrations, and platform-wide coordination mechanisms, have allowed Uber to achieve 95%+ resource utilization.
As Uber continues to grow, Odin is set to evolve further, integrating new optimizations, smarter automation, and deeper AI-driven workload management.
References:
