


Learning useful features from large amounts of unlabeled images is important, and models like DINO and DINOv2 are designed for this. These models work well for tasks like image classification and segmentation, but their training process is difficult. A key challenge is avoiding representation collapse, where the model produces the same output for different images. Many settings must be carefully adjusted to prevent this, making training unstable and hard to manage. DINOv2 tries to solve this by directly using negative samples, but the training setup remains complex. Because of this, improving these models or using them in new areas is difficult, even though their learned features are very effective.
Currently, methods for learning image features rely on complex and unstable training setups. Techniques like SimCLR, SimSiam, VICReg, MoCo, and BYOL attempt to discover useful representations but face various challenges. SimCLR and MoCo require large batch sizes and explicit negative samples, making them computationally expensive. SimSiam and BYOL try to avoid collapse by modifying the gradient structure, which requires careful tuning. VICReg penalizes feature alignment and covariance but does not address feature variance effectively. Techniques like I-JEPA and C-JEPA focus on patch-based learning but add more complexity. These methods struggle to preserve simplicity, stability, and efficiency, complicating training and limiting flexibility.
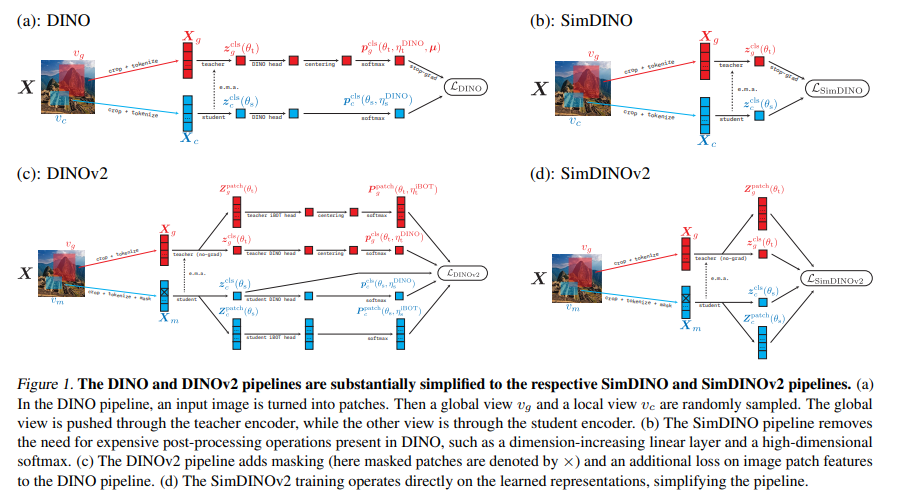
To solve DINO’s complexities, researchers from UC Berkeley, TranscEngram, Microsoft Research and HKU proposed SimDINO and SimDINOv2. These models simplify training by incorporating a coding rate regularization term into the loss function, which prevents representation collapse and removes the need for heavy post-processing and hyperparameter tuning. By preventing unnecessary design choices, SimDINO improves training stability and efficiency. SimDINOv2 enhances performance by handling small and large regions of an image without applying high-dimensional transformations and eliminating the teacher-student paradigm, rendering the method more robust and efficient than existing methods.
This framework maximizes learning by directly controlling feature representations to be useful throughout training without intricate adaptations. The coding rate term gives the model structured and informative features, leading to better generalization and downstream task performance. This simplifies the training pipeline and removes the teacher-student paradigm. SimDINO reduces computational overhead while maintaining high-quality results, making it a more efficient alternative for self-supervised learning in vision tasks.

Researchers evaluated SimDINO and SimDINOv2 against DINO and DINOv2 on ImageNet–1K, COCO val2017, ADE20K, and DAVIS–2017 using ViT architectures with a patch size 16. SimDINO achieved higher k-NN and linear accuracy while maintaining stable training, unlike DINO, which showed performance drops. SimDINO outperformed DINO on COCO val2017 using MaskCut in object detection and segmentation. For semantic segmentation on ADE20K, SimDINOv2 improved DINOv2 by 4.4 mIoU on ViT-B. On DAVIS-2017, SimDINO variants performed better, though DINOv2 and SimDINOv2 underperformed their predecessors due to evaluation sensitivity. Stability tests showed that DINO was more sensitive to hyperparameters and dataset variations, diverging on ViT-L, while SimDINO remained robust, significantly outperforming DINO when trained on COCO train 2017.
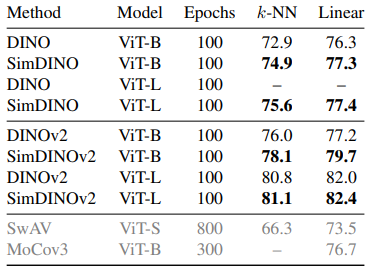
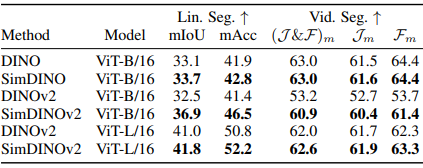
In conclusion, the proposed SimDINO and SimDINOv2 models simplified the complex design choices of DINO and DINOv2 by introducing a coding-rate-related regularization term, making training pipelines more stable and robust while improving performance on downstream tasks. These models enhanced Pareto over their ancestors by eliminating unnecessary complexities, showing the advantages of directly dealing with trade-offs in vision self-supervised learning. The efficient framework establishes a foundation to analyze the geometric structure of self-supervised learning losses and model optimization without self-distillation. These ideas can also be applied to other self-supervised learning models to make training more stable and efficient, which makes SimDINO a strong starting point for developing better deep-learning models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.

The post Simplifying Self-Supervised Vision: How Coding Rate Regularization Transforms DINO & DINOv2 appeared first on MarkTechPost.
