


Visual representation learning using large models and self-supervised techniques has shown remarkable success in various visual tasks. However, deploying these models in real-world applications is challenging due to multiple resource constraints such as computation, storage, and power consumption. Adapting large pre-trained models for different scenarios with varying resource limitations involves weight pruning, knowledge distillation, or retraining smaller networks from scratch. These methods require significant development efforts, making it challenging to deploy AI products across various platforms. It poses a critical question: Is it possible to develop a pre-training method that simultaneously produces multiple models of different sizes, each capable of delivering high-quality visual representations?
Existing works attempt to overcome these challenges. One approach, Generative SSL, focuses on learning image representations in pixel space. Meanwhile, discriminative methods aim to bring representations of different views of the same image closer together while separating those from multiple images. Moreover, Contrastive learning with InfoNCE loss has become popular but struggles with dimensional collapse. Methods like AutoFormer and MaskTAS have explored neural architecture search (NAS) to train supernets that support the extraction of optimal sub-networks. However, these approaches often require additional search and re-training phases, which limits their efficiency in generating multiple models of varying sizes simultaneously.
A team from Ant Group has introduced a new self-supervised learning method called POA (Pre-training Once for All) to tackle the challenge of producing multiple models of varying sizes, simultaneously. POA is built upon the teacher-student self-distillation framework, introducing an innovative elastic student branch. This branch uses a series of sub-networks through parameter sharing, based on the idea that smaller models are sub-networks of larger ones in modern network structures. During pre-training, the elastic student randomly samples parameters from the complete student, and both students learn to mimic the teacher network’s output. This method enables effective pre-training on different parameter subsets.

The POA framework is evaluated using three popular backbone architectures: ViT, Swin Transformer, and ResNet. The Pre-training is performed on the ImageNet-1K dataset, with performance tested through k-NN and linear probing classification assessments and downstream tasks like object detection and semantic segmentation. Moreover, the Elastic Student acts as a model ensemble, making the training process smooth and enhancing learned representations. This architecture allows POA to achieve state-of-the-art accuracy across various model sizes in a single pre-training session, showing its ability to produce multiple high-performance models simultaneously.
The POA framework is compared with SEED, a self-supervised knowledge distillation method that uses a pre-trained DINOv2 network as the teacher. SEED significantly improves the performance of ViT-S/16 and ViT-B/16 when distilled from a pre-trained ViT-L/16 teacher, achieving k-NN accuracy gains of 1.8% and 1.4% respectively compared to learning from scratch. However, POA outperforms SEED, achieving even higher k-NN accuracy gains of 2.8% for ViT-S/16 and 2.1% for ViT-B/16. the ViT-S/16 and ViT-B/16 models derived directly from POA’s pre-trained teacher perform better than those enhanced by SEED, despite SEED using twice the training epochs.
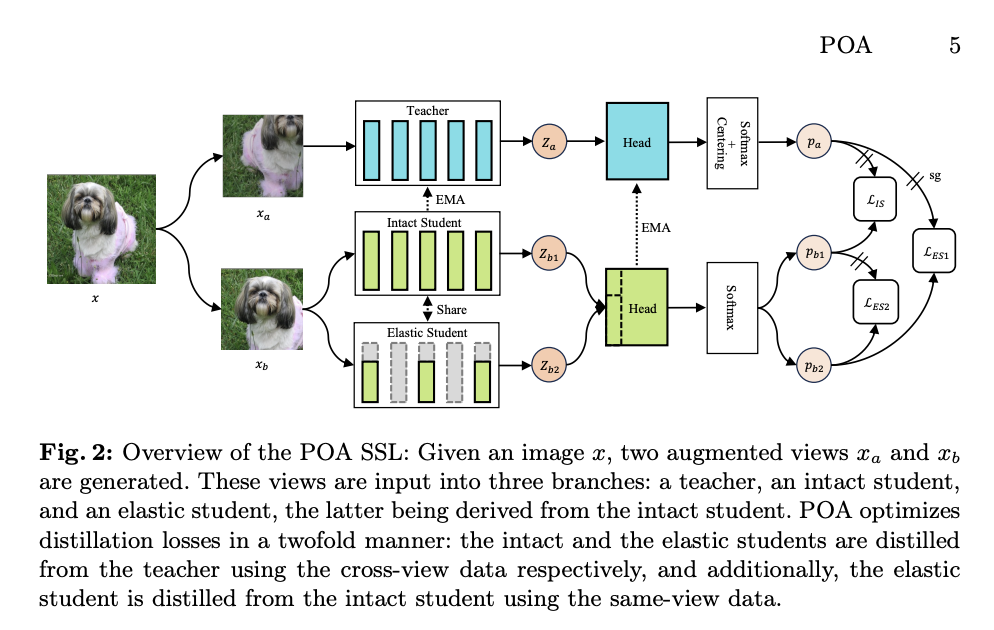
In summary, a team from Ant Group has proposed POA (Pre-training Once for All), a new self-supervised learning method to overcome the challenge of producing multiple models of varying sizes. The POA framework integrates self-distillation with once-for-all model generation, allowing simultaneous pre-training of various model sizes through an innovative elastic branch design. This approach significantly enhances deployment flexibility and enables the pre-trained model to achieve state-of-the-art results across various vision tasks. The team plans to extend the POA to Multimodal Large Language Models to explore its potential for real-world AI product deployment.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
The post POA: A Novel Self-Supervised Learning Paradigm for Efficient Multi-Scale Model Pre-Training appeared first on MarkTechPost.
