


Vision-language models (VLMs) have demonstrated impressive capabilities in general image understanding, but face significant challenges when processing text-rich visual content such as charts, documents, diagrams, and screenshots. These specialised images require complex reasoning that combines textual comprehension with spatial understanding—a skill set critical for analysing scientific literature, improving accessibility features, and enabling AI agents to function effectively in real-world environments. Current VLMs struggle with these tasks primarily due to the scarcity of high-quality training data that realistically represents the diverse array of text-embedded visual formats encountered in practical applications. This data limitation has created a performance gap in scenarios requiring nuanced interpretation of structured visual information, hampering the deployment of these models in specialized domains where text-rich image processing is essential.
Several approaches have been developed to enhance vision-language models for processing visual content. Early architectures explored different integration strategies including cross-attention mechanisms, Q-Former structures, and MLP projection layers to bridge visual and linguistic features. However, these models often suffer from significant imbalance i-e their language components substantially outweigh visual processing capabilities, leading to hallucinations when high-quality training data is scarce. Existing benchmarks for text-rich image understanding (charts, documents, infographics, diagrams, screenshots) remain limited in size, scope, and diversity, making them suitable for evaluation but inadequate for comprehensive training. Previous synthetic data generation efforts have typically focused on narrow domains using small sets of chart types with handcrafted question templates. Some approaches utilize text-only LLMs to generate annotations from tables or descriptions, while others explore code-based rendering of synthetic charts. Despite these advances, current synthetic datasets remain constrained in topic diversity, figure variety, and rendering methodology—critical limitations that hinder generalization to novel, out-of-distribution tasks.
A team of researchers from University of Pennsylvania, and Allen Institute for Artificial Intelligence introduced the Code Guided Synthetic Data Generation System (CoSyn) which offers a flexible framework to address the challenges in text-rich image processing by creating diverse synthetic multimodal training data. This innovative system utilizes the code generation capabilities of text-only LLMS to produce both data and rendering code for various text-rich visual formats using 11 supported rendering tools including Python, HTML, and LaTeX. CoSyn generates not only the images but also corresponding textual instructions grounded in the underlying code representation, creating comprehensive vision-language instruction-tuning datasets. The researchers used this framework to develop CoSyn-400K, a large-scale diverse synthetic dataset specifically designed for text-rich image understanding.

The CoSyn system operates through a sophisticated four-stage workflow beginning with a natural language query like “generate a dataset of book covers.” First, the system selects one of 20 generation pipelines built on 11 diverse rendering tools including Matplotlib, Plotly, LaTeX, HTML, Mermaid, and specialized tools like Lilypond for music sheets and RDKit for chemical structures. The process starts with topic generation guided by sampled personas that enhance content diversity, followed by detailed data generation that populates content specific to the chosen topic. Next, the system generates executable code that renders the synthetic images using the appropriate tool. Finally, using only the code as context, the system prompts language models to generate corresponding textual instructions, including questions, answers, and chain-of-thought reasoning explanations. To enhance diversity beyond what sampling parameters alone can achieve, CoSyn incorporates 200K unique personas during topic generation, effectively countering the repetitive output tendencies of language models. The implementation leverages the DataDreamer library for robust multi-stage generation, using Claude-3.5-Sonnet for code generation and GPT-4o-mini for instruction data generation.
The model trained on CoSyn’s synthetic data demonstrates exceptional performance across text-rich image understanding benchmarks. When evaluated against seven specialized datasets, the 7B parameter model achieves the highest average performance, surpassing the second-best model (Llama 3.2 11B) by a significant margin of 3.9%. The model ranks first in four out of seven benchmarks and second in the remaining three, highlighting its consistent capabilities across diverse text-rich image tasks. Perhaps most remarkably, even the zero-shot version of the model without any exposure to training instances from evaluation datasets outperforms most competing open and closed models, including those that had been fine-tuned on benchmark training data. This unexpected result provides compelling evidence that the skills acquired from CoSyn’s synthetic data transfer effectively to downstream tasks without requiring domain-specific training examples. Additional ablation studies demonstrate that combining synthetic data with auxiliary and evaluation datasets yields the best performance (80.9%), substantially outperforming models trained on evaluation data alone (75.9%).
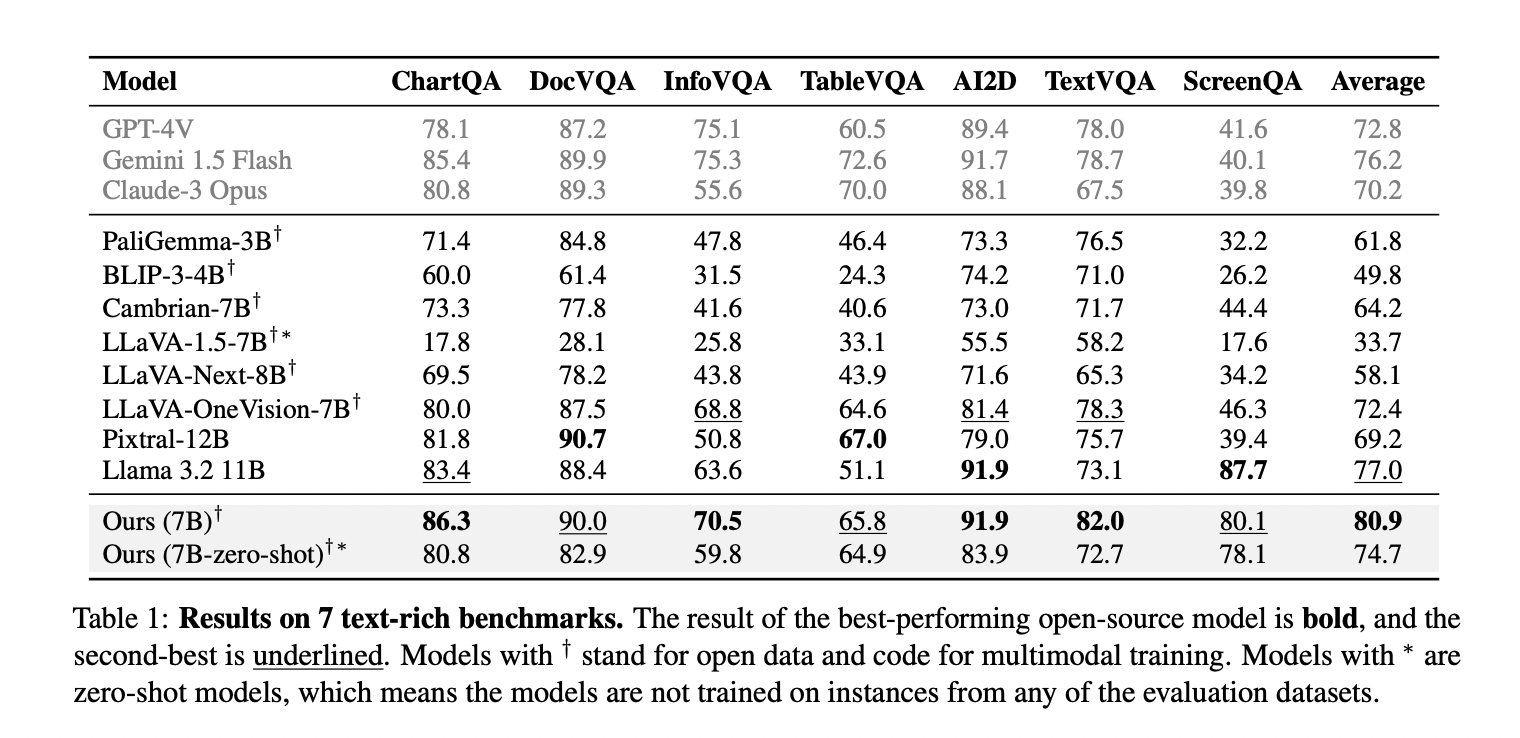
The CoSyn framework represents a significant advancement in vision-language model development, utilizing synthetic data generation to substantially improve performance on text-rich image understanding tasks. By harnessing the code generation capabilities of text-only LLMs, the system creates diverse, high-quality training data that enables models to generalize across domains with remarkable efficiency. Analysis confirms that CoSyn-generated data successfully mitigates biases present in existing datasets, resulting in models that perform robustly on realistic, human-written queries rather than just template-based questions. The demonstrated improvements in zero-shot learning, multi-hop reasoning, and novel domain adaptation highlight synthetic data’s crucial role in developing VLMs capable of handling complex text-rich visual content in practical applications.
Check out the Paper and Dataset here. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.

The post CoSyn: An AI Framework that Leverages the Coding Capabilities of Text-only Large Language Models (LLMs) to Automatically Create Synthetic Text-Rich Multimodal Data appeared first on MarkTechPost.
