


Large Language Models (LLMs) face significant challenges in optimizing their post-training methods, particularly in balancing Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) approaches. While SFT uses direct instruction-response pairs and RL methods like RLHF use preference-based learning, the optimal allocation of limited training resources between these approaches remains unclear. Recent studies have shown that models can achieve task alignment and improved reasoning capabilities without extensive SFT, challenging traditional sequential post-training pipelines. Moreover, the substantial cost of collecting and annotating human data compared to compute costs creates a need to understand the effectiveness of different training methods under fixed data-annotation budgets.
Existing research has explored various trade-offs in language model training under fixed budgets, including comparisons between pretraining versus finetuning and finetuning versus model distillation. Studies have examined the data and compute costs of SFT and RL methods in isolation along with cost-efficiency considerations in generating human and synthetic data. While some research shows the effects of high-quality preference data on RL methods like Direct Preference Optimization (DPO) and PPO, other studies focus on the relationship between SFT and RL methods regarding model forgetfulness, generalization, and alignment. However, these studies haven’t failed to address optimal resource allocation between SFT and RL-based approaches under strict data annotation constraints.
Researchers from the Georgia Institute of Technology have proposed a comprehensive study examining the optimal allocation of training data budgets between SFT and Preference Finetuning (PFT) in LLMs. The study investigates this relationship across four diverse tasks, multiple model sizes, and various data annotation costs. It addresses the “cold start problem” in mathematical tasks, where eliminating SFT leads to suboptimal performance due to distribution shifts when applying DPO directly to the base model. Their findings suggest that while larger data budgets benefit from combining both methods, allocating even a small portion of the budget to SFT can significantly improve performance on analytical tasks.
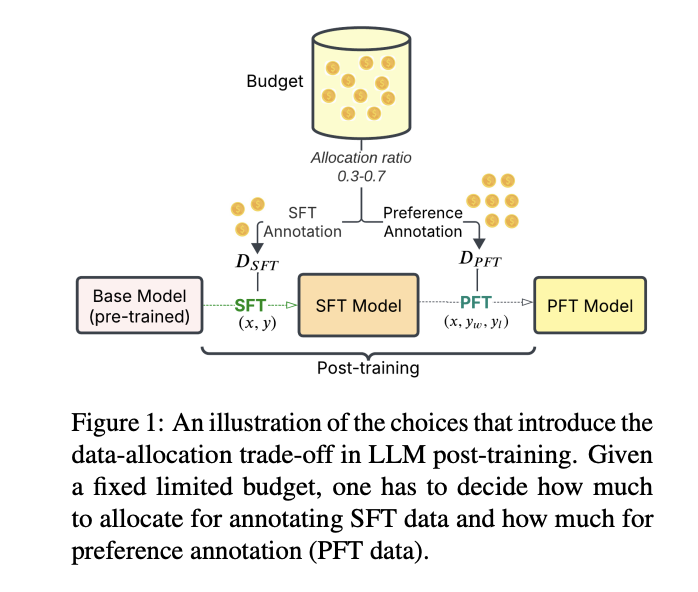
The study evaluates the cost-effectiveness and optimal resource allocation between SFT and PFT in post-training LLMs under 10 billion parameters. The research methodology measures data budgets through training examples or monetary annotation costs, assuming equal labor costs for both methods and the availability of training prompts. The experimental setup begins with no task-specific labeled data, using open-source datasets, or synthetically curated data for each target task. To maintain focus on task-specific improvements, general-purpose conversational datasets commonly used in PFT, such as UltraFeedback and Chatbot Arena preferences are excluded. This controlled approach allows for precise measurement of performance improvements resulting from targeted data annotation.
The results reveal that optimal allocation of the training budget between SFT and PFT methods proves crucial, with properly balanced datasets outperforming suboptimally allocated datasets 2-5 times larger in size. Using 5K examples with 25% SFT allocation for tasks like Summarization, Helpfulness, and Grade School Math matches the performance of 20K examples with 75% SFT allocation. The study identifies that pure SFT excels in low-data scenarios, while larger data budgets benefit from higher proportions of preference data. Moreover, direct preference finetuning on base models shows limited success in mathematical tasks, and allocating even a small portion to SFT significantly improves performance by better aligning the reference model’s response style.
In conclusion, this paper provides crucial insights into optimizing LLM post-training under resource constraints, particularly regarding the interplay between SFT and PFT. The study identifies a significant “cold-start problem” when applying PFT directly to base models, which can be mitigated effectively by allocating even 10% of the budget to initial SFT. However, the research acknowledges limitations, including offline methods like DPO and KTO use for RL implementation, and potential biases from using GPT4 for synthetic data generation and evaluation. Moreover, the model size is limited to 10 Billion parameters otherwise it would be extremely compute resource intensive to run thousands of finetuning runs with larger model sizes like 70B parameters.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.

The post Optimizing Training Data Allocation Between Supervised and Preference Finetuning in Large Language Models appeared first on MarkTechPost.
