
Published on February 22, 2025 9:39 AM GMT
Date: Around the last week of May 2025
Location: Science Park, University of Amsterdam (tentative)
Organizers: Jan Pieter van der Schaar (University of Amsterdam), Nabil Iqbal (Durham University) and Karthik Viswanathan (University of Amsterdam)
We are excited to announce a two-day workshop on "Interpretability in LLMs using Geometrical and Statistical Methods" during the last week of May (tentative), with around 20 participants from Amsterdam, AREA Science Park (Trieste), and our invited speakers.
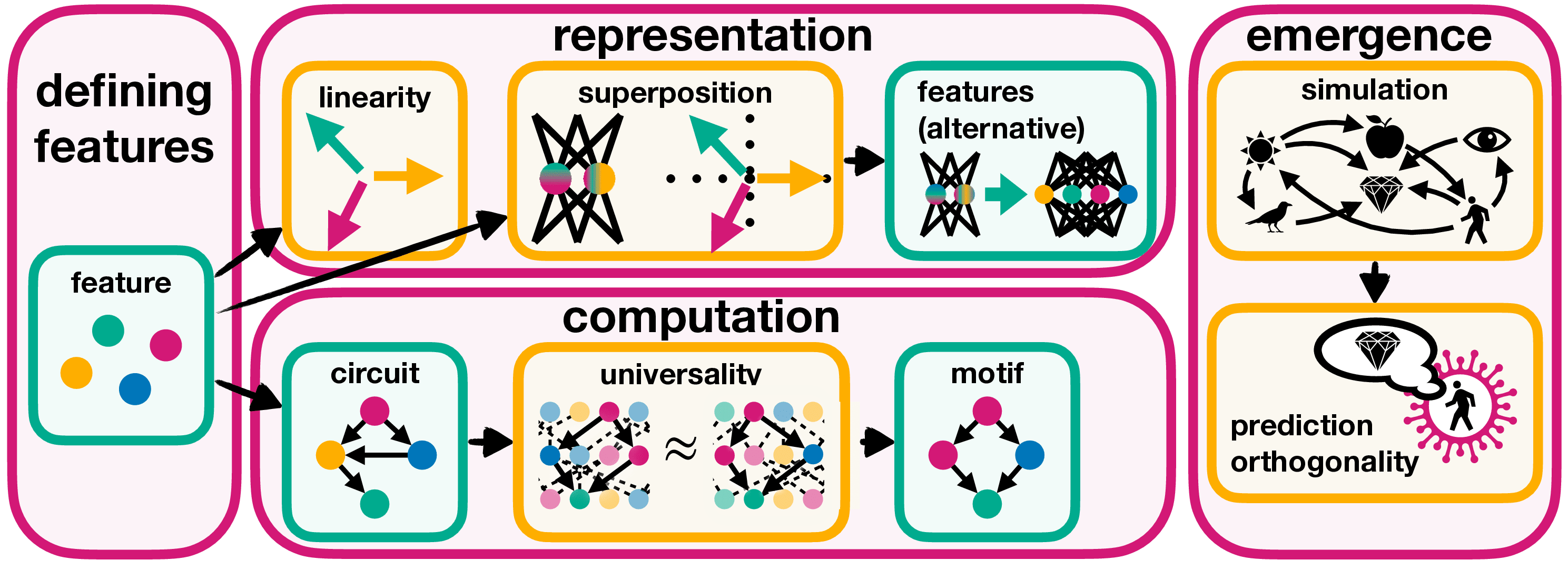
This workshop explores recent developments in understanding the inner workings of Large Language Models (LLMs) by leveraging concepts from geometry and statistics. The workshop aims to provide an accessible introduction to these approaches, focusing on their potential to address key challenges in AI alignment, safety, and efficiency, while providing an overview of the current research problems in LLM interpretability. By bridging theoretical insights with practical applications, this workshop seeks to foster an exchange of ideas and motivate research at the intersection of computational geometry, statistical mechanics, and AI interpretability.
Overview
The workshop spans two days where Day 1 focuses on the geometric and statistical properties of internal representations in LLMs. The talks on this day are expected to have a physics-oriented perspective. On the second day, we aim to broaden the scope, covering mechanistic interpretability and its applications to AI safety, and exploring how the ideas from Day 1 can contribute to current research challenges in AI safety.
Day 1: Geometric and Statistical Methods for Interpretability
On the first day, we will explore how large language models process and represent information through their internal representations. The discussions will focus on the geometry of embeddings - how they evolve across model layers and the insights they provide. The talks on Day 1 are expected to align with the themes discussed in this blogpost and paper.
Day 2: Mechanistic Interpretability and Applications to AI Safety
On the second day, the focus will shift toward the mechanistic aspects of interpretability, examining how specific circuits in a model’s architecture can be identified and analyzed. The discussions will also explore how these insights can be applied to AI safety research. The talks on Day 2 are expected to align with the themes discussed in this blogpost and paper.
Format
The workshop is still in its early planning stages, so the format may evolve. Currently, the plan is to have 3-4 talks per day, with dedicated time for discussions and potential collaborations. The workshop is currently intended to be fully in-person, but this may be adjusted based on the level of interest from the online community. The speakers and the schedule are yet to be decided.
Questions?
Reach out to me at k.viswanathan@uva.nl or comment below. We look forward to seeing you. In the meantime, here’s a fun comic to keep you occupied!

Discuss
