


Understanding financial information means analyzing numbers, financial terms, and organized data like tables for useful insights. It requires math calculations and knowledge of economic concepts, rules, and relationships between financial terms. Although sophisticated AI models have shown excellent general reasoning ability, their suitability for financial tasks is questionable. Such tasks require more than simple mathematical calculations since they involve interpreting domain-specific vocabulary, recognizing relationships between financial points, and analyzing structured financial data.
Generally, reasoning approaches like chain-of-thought fine-tuning and reinforcement learning boost performance on multiple tasks but collapse with financial rationale. They improve logical reasoning but cannot replicate the complexity of economic information, which requires numerical comprehension, knowledge of the field, and data interpretation in an organized way. While large language models are widely used in finance for tasks like sentiment analysis, market prediction, and automated trading, general models are not optimized for financial reasoning. Finance-specific models, such as BloombergGPT and FinGPT, help understand financial terms but still face challenges in reasoning over financial documents and structured data.
To solve this, researchers from TheFinAI proposed Fino1, a financial reasoning model based on Llama-3.1-8B-Instruct. Existing models struggled with financial text, tabular data, and equations, showing poor performance in long-context tasks and multi-table reasoning. Simple dataset improvements and general techniques like CoT fine-tuning failed to bring consistent results. This framework employed reinforcement learning and iterative CoT fine-tuning to enhance financial reasoning, logical step refinement, and decision-making accuracy. Logical sequences were built systematically so the model could analyze financial issues step by step, and verification mechanisms tested reliability to determine correct financial conclusions. Two-stage LoRA fine-tuning resolved contradictions in numerical reasoning and equation solving, with the first stage fine-tuning the model to financial principles and the second stage fine-tuning intricate calculations. Organized training on various finance datasets, such as reports and tabular data, enhanced interpretation to provide more accurate financial statements and transaction records analysis.
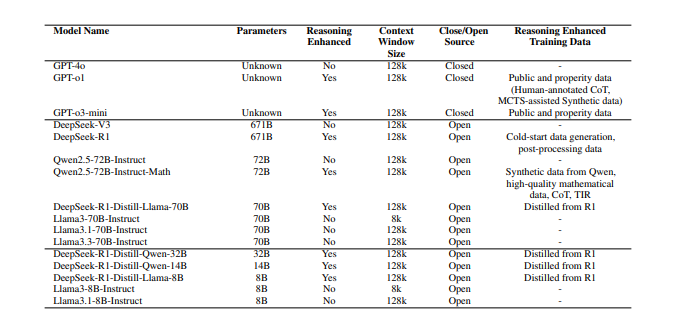
Researchers evaluated language models on financial reasoning tasks and found DeepSeek-R1 performed best (68.93) due to strong XBRL–Math results, followed by DeepSeek-R1-Distill-Llama-70B and DeepSeek-R1-Distill-Qwen-32B. GPT-4o performed well but lagged due to lower XBRL-Math scores. General-purpose models like Llama3.3-70B outperformed some reasoning-focused models, showing that general reasoning did not always enhance financial tasks. Researchers found that logical-task fine-tuning struggled with economic data, while mathematical enhancements improved XBRL-Math but hurt FinQA and DM-Simplong accuracy. Scaling model size did not always help, as smaller models sometimes performed better. Expanding pre-training data and refining post-training techniques improved financial reasoning. Fino1-8B, trained with reasoning paths from GPT-4o, outperformed others, proving financial-specific training was effective. These results highlighted the importance of domain-specific training to improve financial understanding and multi-step numerical reasoning.
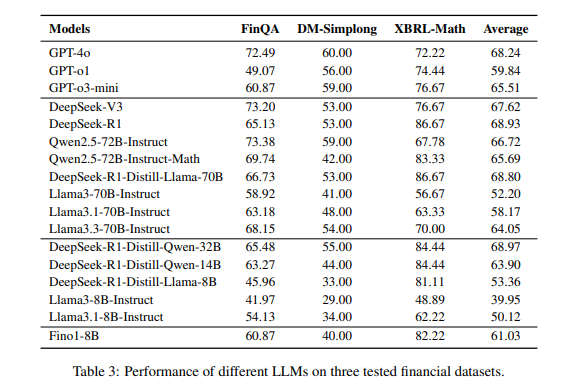
In summary, the new approach improved financial thinking in LLMs. By taking advantage of reasonability paths from GPT-4o on FinQA, Fino1 was 10% better across three financial tests. Although formal mathematical models performed best on numerical tasks such as XBRL-Math, they fell short of expectations in processing financial text and long contexts, with domain adaptation necessary. Despite the model scale and dataset diversity limitations, this framework can act as a baseline for future research. Advancements in dataset expansion, retrieval-augmented methods, and multi-step reasoning can further enhance financial LLMs for real-world applications.
Check out the Paper and Model on Hugging Face. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 75k+ ML SubReddit.

The post Meet Fino1-8B: A Fine-Tuned Version of Llama 3.1 8B Instruct Designed to Improve Performance on Financial Reasoning Tasks appeared first on MarkTechPost.
