
Artificial intelligence in multi-agent environments has made significant strides, particularly in reinforcement learning. One of the core challenges in this domain is developing AI agents capable of communicating effectively through natural language. This is particularly critical in settings where each agent has only partial visibility of the environment, making knowledge-sharing essential for achieving collective goals. Social deduction games provide an ideal framework for testing AI’s ability to deduce information through conversations, as these games require reasoning, deception detection, and strategic collaboration.
A key issue in AI-driven social deduction is ensuring that agents can conduct meaningful discussions without relying on human demonstrations. Many language models falter in multi-agent settings due to their dependence on vast datasets of human conversations. The challenge intensifies as AI agents struggle to assess whether their contributions meaningfully impact decision-making. Without a clear mechanism to evaluate the usefulness of their messages, they often generate unstructured and ineffective communication, leading to suboptimal performance in strategic games that require deduction and persuasion.
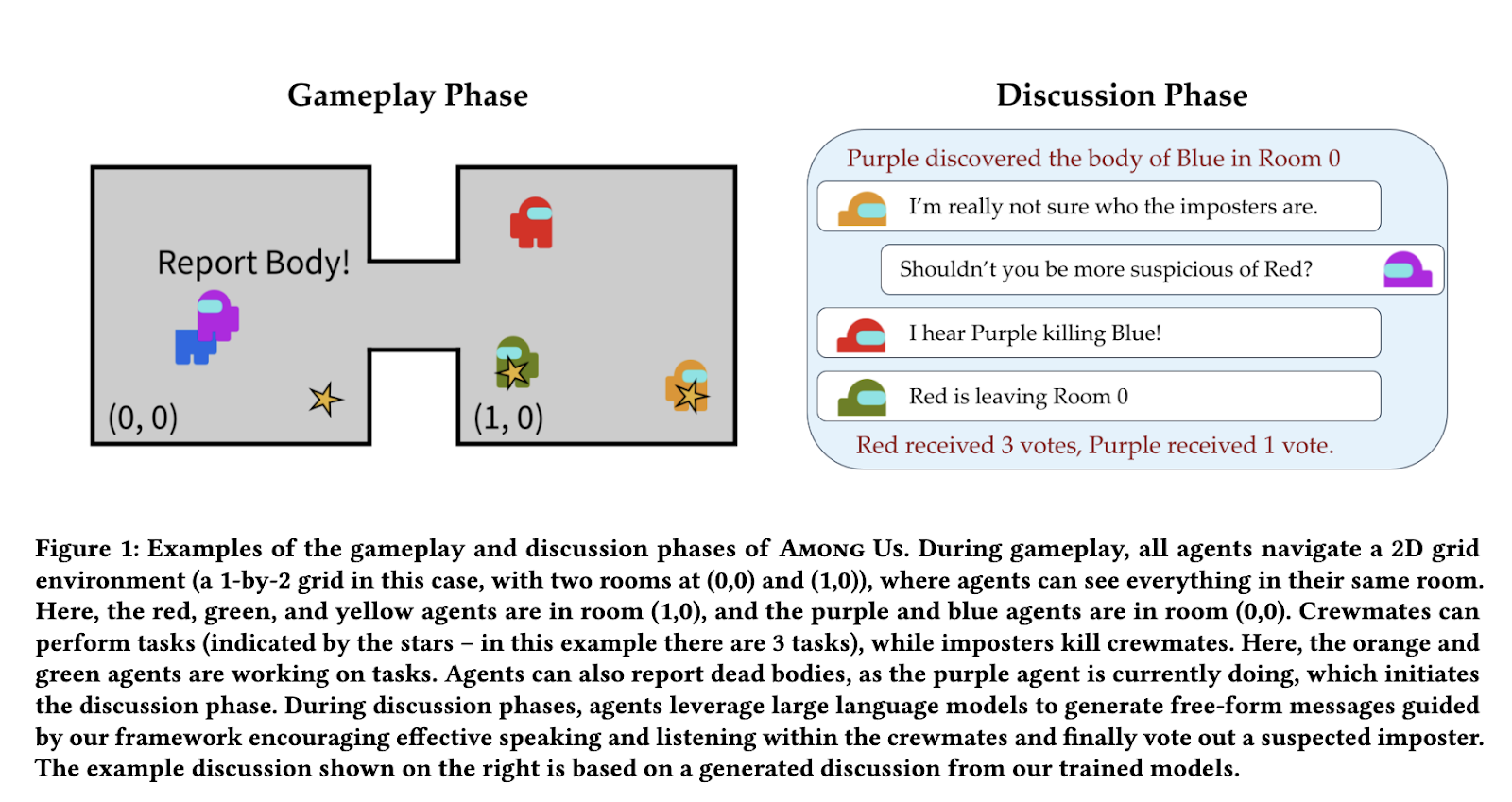
Existing reinforcement learning approaches attempt to address this problem but frequently fall short. Some techniques depend on pre-existing datasets of human interactions, which are not always available or adaptable to new scenarios. Others incorporate language models with reinforcement learning but fail due to sparse feedback, which makes it difficult for AI to refine its dialogue strategies. Traditional methods cannot thus systematically improve communication skills over time, making AI discussions in multi-agent environments less effective.
A research team from Stanford University introduced an innovative method for training AI agents in social deduction settings without human demonstrations—their approach leverages multi-agent reinforcement learning to develop AI capable of understanding and articulating meaningful arguments. The research focuses on the game *Among Us*, where crewmates must identify an imposter through verbal discussions. The researchers designed a training mechanism that divides communication into listening and speaking, allowing the AI to optimize both skills independently. The method integrates a structured reward system that progressively enables agents to refine their discussion techniques.
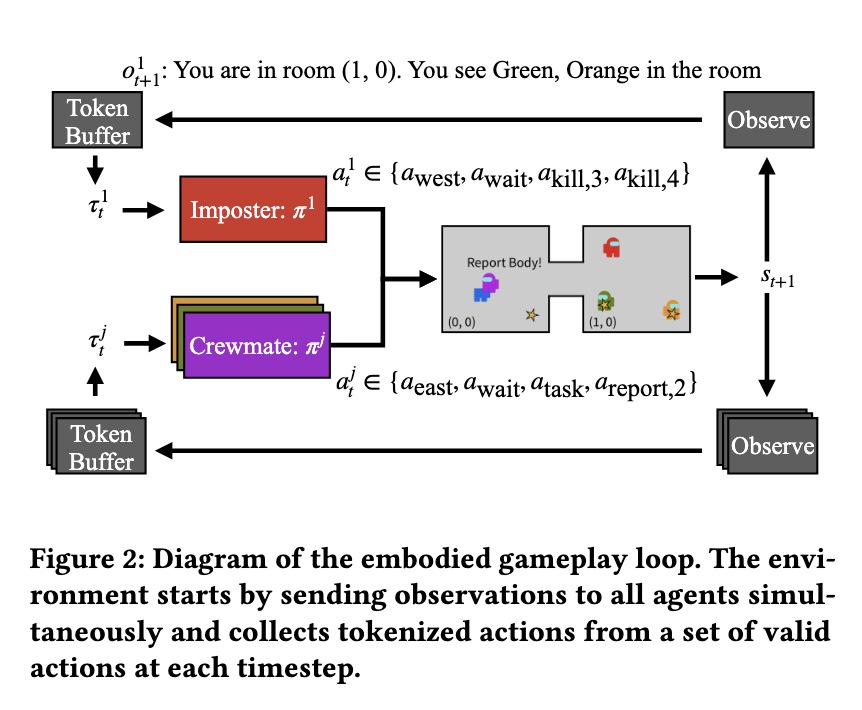
The methodology introduces a dense reward signal that provides precise feedback to improve communication. AI agents enhance their listening abilities by predicting environmental details based on prior discussions. At the same time, their speaking proficiency improves through reinforcement learning, where messages are assessed based on their impact on other agents’ beliefs. This structured approach ensures that AI-generated messages are logical, persuasive, and relevant to the conversation. The research team employed RWKV, a recurrent neural network model, as the foundation for their training, optimizing it for long-form discussions and dynamic gameplay environments.
Experimental results demonstrated that this training approach significantly improved AI performance compared to traditional reinforcement learning techniques. The trained AI exhibited behaviors akin to human players, including suspect accusation, evidence presentation, and reasoning based on observed actions. The study showed that AI models utilizing this structured discussion learning framework achieved a win rate of approximately 56%, compared to the 28% win rate of reinforcement learning models without the structured dialogue framework. Furthermore, the AI trained using this method outperformed models four times larger in size, underscoring the efficiency of the proposed training strategy. When analyzing discussion behaviors, the research team observed that the AI could accurately identify imposters at a success rate twice as high as baseline reinforcement learning approaches.
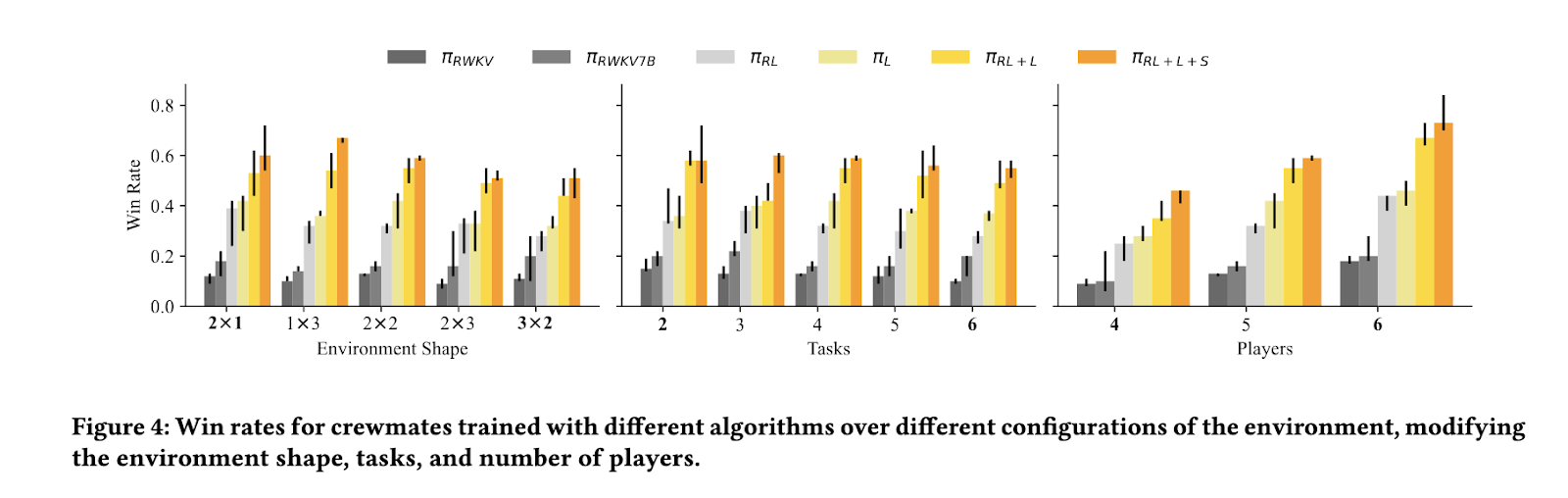
Further analysis revealed that AI models trained under this framework adapted effectively to adversarial strategies. Imposters attempted to manipulate discussions by shifting blame, initially confusing AI crewmates. However, the AI agents learned to differentiate between genuine accusations and misleading statements through iterative training. Researchers found that AI-generated messages that explicitly named a suspect were more likely to influence group decisions. This emergent behavior closely resembled human intuition, indicating that the AI could adapt discussion strategies dynamically.
This research marks a significant advancement in AI-driven social deduction. By addressing the communication challenges in multi-agent settings, the study provides a structured and effective framework for training AI agents to engage in meaningful discussions without relying on extensive human demonstrations. The proposed method enhances AI decision-making, allowing for more persuasive and logical reasoning in environments that require collaboration and the detection of deception. The research opens possibilities for broader applications, including AI assistants capable of analyzing complex discussions, negotiating, and strategizing in real-world scenarios.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 75k+ ML SubReddit.

The post Stanford Researchers Introduced a Multi-Agent Reinforcement Learning Framework for Effective Social Deduction in AI Communication appeared first on MarkTechPost.
