


In this tutorial, we demonstrate the workflow for fine-tuning Mistral 7B using QLoRA with Axolotl, showing how to manage limited GPU resources while customizing the model for new tasks. We’ll install Axolotl, create a small example dataset, configure the LoRA-specific hyperparameters, run the fine-tuning process, and test the resulting model’s performance.
Step 1: Prepare the Environment and Install Axolotl
# 1. Check GPU availability!nvidia-smi# 2. Install git-lfs (for handling large model files)!sudo apt-get -y install git-lfs!git lfs install# 3. Clone Axolotl and install from source!git clone https://github.com/OpenAccess-AI-Collective/axolotl.git%cd axolotl!pip install -e .# (Optional) If you need a specific PyTorch version, install it BEFORE Axolotl:# !pip install torch==2.0.1+cu118 --extra-index-url https://download.pytorch.org/whl/cu118# Return to /content directory%cd /contentFirst, we check which GPU is there and how much memory is there. We then install Git LFS so that large model files (like Mistral 7B) can be handled properly. After that, we clone the Axolotl repository from GitHub and install it in “editable” mode, which allows us to call its commands from anywhere. An optional section lets you install a specific PyTorch version if needed. Finally, we navigate back to the /content directory to organize subsequent files and paths neatly.
Step 2: Create a Tiny Sample Dataset and QLoRA Config for Mistral 7B
import os# Create a small JSONL datasetos.makedirs("data", exist_ok=True)with open("data/sample_instructions.jsonl", "w") as f: f.write('{"instruction": "Explain quantum computing in simple terms.", "input": "", "output": "Quantum computing uses qubits..."}\n') f.write('{"instruction": "What is the capital of France?", "input": "", "output": "The capital of France is Paris."}\n')# Write a QLoRA config for Mistral 7Bconfig_text = """\base_model: mistralai/mistral-7b-v0.1tokenizer: mistralai/mistral-7b-v0.1# We'll use QLoRA to minimize memory usagetrain_type: qlorabits: 4double_quant: truequant_type: nf4lora_r: 8lora_alpha: 16lora_dropout: 0.05target_modules: - q_proj - k_proj - v_projdata: datasets: - path: /content/data/sample_instructions.jsonl val_set_size: 0 max_seq_length: 512 cutoff_len: 512training_arguments: output_dir: /content/mistral-7b-qlora-output num_train_epochs: 1 per_device_train_batch_size: 1 gradient_accumulation_steps: 4 learning_rate: 0.0002 fp16: true logging_steps: 10 save_strategy: "epoch" evaluation_strategy: "no"wandb: enabled: false"""with open("qlora_mistral_7b.yml", "w") as f: f.write(config_text)print("Dataset and QLoRA config created.")Here, we build a minimal JSONL dataset with two instruction-response pairs, giving us a toy example to train on. We then construct a YAML configuration that points to the Mistral 7B base model, sets up QLoRA parameters for memory-efficient fine-tuning, and defines training hyperparameters like batch size, learning rate, and sequence length. We also specify LoRA settings such as dropout and rank and finally save this configuration as qlora_mistral_7b.yml.
Step 3: Fine-Tune with Axolotl
# This will download Mistral 7B (~13 GB) and start fine-tuning with QLoRA.# If you encounter OOM (Out Of Memory) errors, reduce max_seq_length or LoRA rank.!axolotl --config /content/qlora_mistral_7b.ymlHere, Axolotl automatically fetches and downloads the Mistral 7B weights (a large file) and then initiates a QLoRA-based fine-tuning procedure. The model is quantized to 4-bit precision, which helps reduce GPU memory usage. You’ll see training logs that show the progress, including the training loss, step by step.
Step 4: Test the Fine-Tuned Model
import torchfrom peft import PeftModelfrom transformers import AutoModelForCausalLM, AutoTokenizer# Load the base Mistral 7B modelbase_model_path = "mistralai/mistral-7b-v0.1" #First establish access using your user account on HF then run this partoutput_dir = "/content/mistral-7b-qlora-output"print("\nLoading base model and tokenizer...")tokenizer = AutoTokenizer.from_pretrained( base_model_path, trust_remote_code=True)base_model = AutoModelForCausalLM.from_pretrained( base_model_path, device_map="auto", torch_dtype=torch.float16, trust_remote_code=True)print("\nLoading QLoRA adapter...")model = PeftModel.from_pretrained( base_model, output_dir, device_map="auto", torch_dtype=torch.float16)model.eval()# Example promptprompt = "What are the main differences between classical and quantum computing?"inputs = tokenizer(prompt, return_tensors="pt").to("cuda")print("\nGenerating response...")with torch.no_grad(): outputs = model.generate(**inputs, max_new_tokens=128)response = tokenizer.decode(outputs[0], skip_special_tokens=True)print("\n=== Model Output ===")print(response)Finally, we load the base Mistral 7B model again and then apply the newly trained LoRA weights. We craft a quick prompt about the differences between classical and quantum computing, convert it to tokens, and generate a response using the fine-tuned model. This confirms that our QLoRA training has taken effect and that we can successfully run inference on the updated model.
Snapshot of supported models with Axolotl
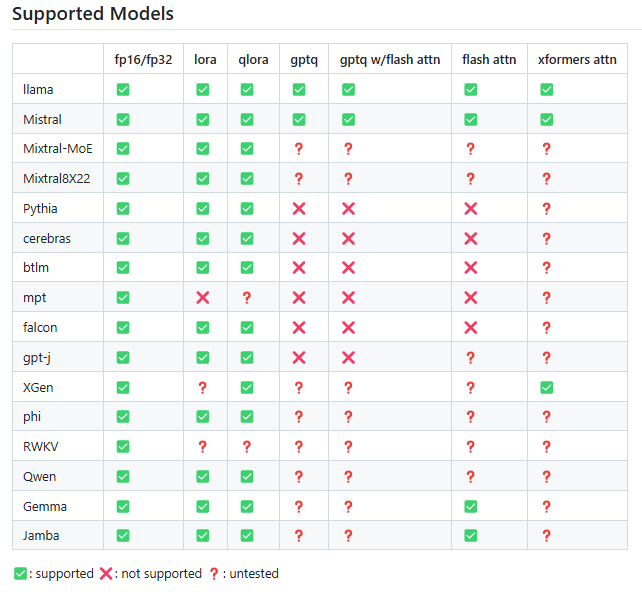
In conclusion, the above steps have shown you how to prepare the environment, set up a small dataset, configure LoRA-specific hyperparameters, and run a QLoRA fine-tuning session on Mistral 7B with Axolotl. This approach showcases a parameter-efficient training process suitable for resource-limited environments. You can now expand the dataset, modify hyperparameters, or experiment with different open-source LLMs to further refine and optimize your fine-tuning pipeline.
Download the Colab Notebook here. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 75k+ ML SubReddit.

The post Tutorial to Fine-Tuning Mistral 7B with QLoRA Using Axolotl for Efficient LLM Training appeared first on MarkTechPost.
