快科技2月4日消息,据报道,中国的研究人员发明了一种创新的高性能算法,可以大幅提升NVIDIA消费级GPU的科学计算性能,最高达惊人的800倍!
这一算法来自深圳北理莫斯科大学的团队,该校由北京理工大学、莫斯科国立罗蒙诺索夫大学联合创立。新的算法增强了近场动力学(Peridynamics)的计算效率,这是一种前沿的非局部理论,可以解决材料断裂、损坏等复杂的物理问题,广泛用于航空、工程、军事等领域。但是,近场动力学的计算非常复杂,传统模拟方法效率不够高。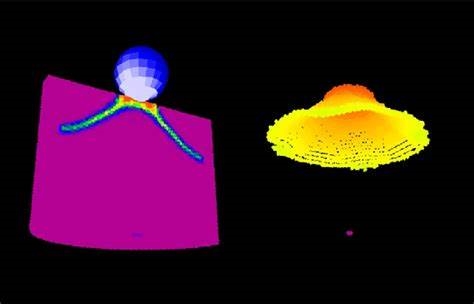


🚀 **性能飞跃**:中国研究人员的创新算法,使NVIDIA消费级GPU的科学计算性能提升高达800倍,突破了传统计算瓶颈。
💡 **技术创新**:深圳北理莫斯科大学团队通过优化近场动力学算法,并结合NVIDIA CUDA技术,创建了PD-General框架,实现了高效的并行计算。
🔬 **应用前景**:新算法在航空航天、工程制造和军事研究等领域具有广泛的应用前景,能够加速材料测试、结构分析和抗冲击研究。
💰 **成本优势**:该算法无需高性能GPU芯片,仅需普通消费级GPU即可完成,降低了科研成本,且不受美国制裁限制。
快科技2月4日消息,据报道,中国的研究人员发明了一种创新的高性能算法,可以大幅提升NVIDIA消费级GPU的科学计算性能,最高达惊人的800倍!
这一算法来自深圳北理莫斯科大学的团队,该校由北京理工大学、莫斯科国立罗蒙诺索夫大学联合创立。新的算法增强了近场动力学(Peridynamics)的计算效率,这是一种前沿的非局部理论,可以解决材料断裂、损坏等复杂的物理问题,广泛用于航空、工程、军事等领域。但是,近场动力学的计算非常复杂,传统模拟方法效率不够高。AI辅助创作,多种专业模板,深度分析,高质量内容生成。从观点提取到深度思考,FishAI为您提供全方位的创作支持。新版本引入自定义参数,让您的创作更加个性化和精准。

鱼阅,AI 时代的下一个智能信息助手,助你摆脱信息焦虑