


LLMs have demonstrated impressive cognitive abilities, making significant strides in artificial intelligence through their ability to generate and predict text. However, while various benchmarks evaluate their perception, reasoning, and decision-making, less attention has been given to their exploratory capacity. Exploration, a key aspect of intelligence in humans and AI, involves seeking new information and adapting to unfamiliar environments, often at the expense of immediate rewards. Unlike exploitation, which relies on leveraging known information for short-term gains, exploration enhances adaptability and long-term understanding. The extent to which LLMs can effectively explore, particularly in open-ended tasks, remains an open question.
Exploration has been widely studied in reinforcement learning and human cognition, typically categorized into three main strategies: random exploration, uncertainty-driven exploration, and empowerment. Random exploration introduces variability into actions, allowing discoveries through stochastic behavior. Uncertainty-driven exploration prioritizes actions with uncertain outcomes to reduce ambiguity and improve decision-making. Empowerment, by contrast, focuses on maximizing potential future possibilities rather than optimizing for specific rewards, aligning closely with scientific discovery and open-ended learning. While preliminary studies indicate that LLMs exhibit limited exploratory behaviors, current research is often restricted to narrow tasks such as bandit problems, failing to capture the broader dimensions of exploration, particularly empowerment-based strategies.
Researchers at the Georgia Tech. examined whether LLMs can outperform humans in open-ended exploration using Little Alchemy 2, where agents combine elements to discover new ones. Their findings revealed that most LLMs underperformed compared to humans, except for the o1 model. Unlike humans, who balance uncertainty and empowerment, LLMs primarily rely on uncertainty-driven strategies. Sparse Autoencoder (SAE) analysis showed that uncertainty is processed in earlier transformer layers, while empowerment occurs later, leading to premature decisions. This study provides insights into LLMs’ limitations in exploration and suggests future improvements to enhance their adaptability and decision-making processes.
The study used Little Alchemy 2, where players combine elements to discover new ones, assessing LLMs’ exploration strategies. Data from 29,493 human participants across 4.69 million trials established a benchmark. Four LLMs—GPT-4o, o1, LLaMA3.1-8B, and LLaMA3.1-70B—were tested, with varying sampling temperatures to examine exploration-exploitation trade-offs. Regression models analyzed empowerment and uncertainty in decision-making, while SAEs identified how LLMs represent these cognitive variables. Results showed that o1 significantly outperformed other LLMs, discovering 177 elements compared to humans’ 42, while other models performed worse, highlighting challenges in LLM-driven open-ended exploration.
The study evaluates LLMs’ exploration strategies, highlighting o1’s superior performance over humans (t = 9.71, p < 0.001), while other LLMs performed worse. Larger models showed improvement, with LLaMA3.1-70B surpassing LLaMA3.1-8B and GPT-4o slightly outperforming LLaMA3.1-70B. Exploration became harder in later trials, favoring empowerment-based strategies over uncertainty-driven ones. Higher temperatures reduced redundant behaviors but did not enhance empowerment. Analysis showed uncertainty was processed earlier than empowerment, influencing decision-making. Ablation experiments confirmed uncertainty’s critical role, while empowerment had minimal impact. These findings suggest current LLMs struggle with open-ended exploration due to architectural limitations.
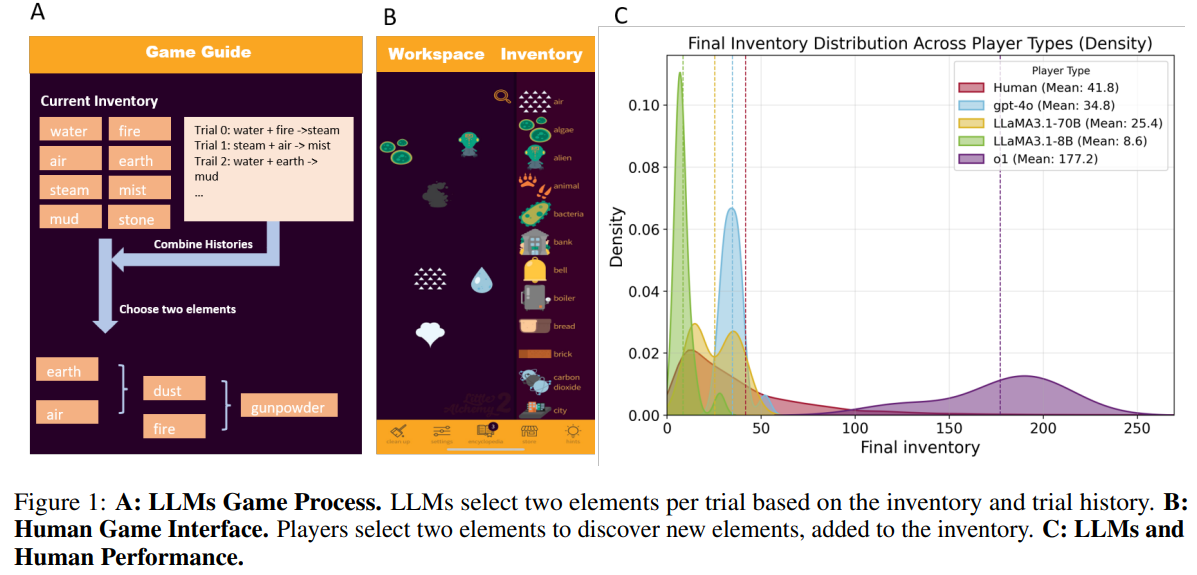
In conclusion, the study examines LLMs’ exploratory capabilities in open-ended tasks using Little Alchemy 2. Most LLMs rely on uncertainty-driven strategies, leading to short-term gains but poor long-term adaptability. Only o1 surpasses humans by effectively balancing uncertainty and empowerment. Analysis with SAE reveals that uncertainty is processed in early transformer layers, while empowerment emerges later, causing premature decision-making. Traditional inference paradigms limit exploration capacity, though reasoning models like DeepSeek-R1 show promise. Future research should explore architecture adjustments, extended reasoning frameworks, and explicit exploratory objectives to enhance LLMs’ ability to engage in human-like exploration.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 70k+ ML SubReddit.
 Meet IntellAgent: An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System (Promoted)
Meet IntellAgent: An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System (Promoted)
The post Exploration Challenges in LLMs: Balancing Uncertainty and Empowerment in Open-Ended Tasks appeared first on MarkTechPost.
