


Retrieval-Augmented Generation (RAG) is a key technique in enterprise applications that combines large foundation models with external retrieval systems to generate responses that are both accurate and grounded in factual information. Unlike traditional foundation models, which are trained on massive datasets and remain static post-deployment, RAG enhances reliability by incorporating real-time or domain-specific information during the generation process. This integration addresses common issues like hallucinations or gaps in long-tail factual knowledge. RAG systems typically follow a sequential pipeline where retrieved information is provided as input to the generative model, with the overall performance depending heavily on the quality of the retrieval process. To ensure scalability, dense retrievers often use bi-encoder architectures for compressing documents and queries into fixed-size vectors, enabling efficient search algorithms. However, this efficiency comes at the cost of reduced flexibility for handling complex or multi-hop queries, which require iterative reasoning and retrieval steps based on dynamically evolving information.
Recent advancements in RAG have introduced iterative retrieval-generation methods to overcome the limitations of a single retrieval step. Approaches like FLARE and ITER-RETGEN enable models to decide when and what to retrieve during generation, enhancing performance in complex reasoning tasks. Methods like IRCoT adopt chain-of-thought reasoning, refining retrieval steps recursively, while Self-RAG integrates retrieval, generation, and critique for improved factual accuracy. Scaling test-time computing has also been explored to boost RAG performance, with strategies such as retrieving more documents or using long-context LLMs, as seen in LongRAG and IterDRAG. Tree-of-Thought (ToT) and STaR extend reasoning capabilities by leveraging structured exploration and intermediate training states, though these approaches increase token consumption and response latency. Newer methods, like Search-o1, integrate open-source models with active search mechanisms, further advancing RAG’s potential in knowledge-intensive tasks.
Researchers from Microsoft Corporation and the Renmin University of China introduced CoRAG (Chain-of-Retrieval Augmented Generation), a method for training RAG models to iteratively retrieve and reason before generating answers. Unlike conventional RAG systems, CoRAG dynamically reformulates queries based on the evolving reasoning state. The approach uses rejection sampling to augment datasets with intermediate retrieval chains, enabling fine-tuning of open-source models. CoRAG achieves state-of-the-art results on benchmarks like KILT, particularly excelling in multi-hop reasoning tasks by addressing retrieval bottlenecks. It supports diverse decoding strategies, adjusts test-time retrieval dynamically, and demonstrates robustness to varying retriever quality, offering a pathway to more grounded and factual AI models.
The CoRAG framework enhances RAG models through three key components: retrieval chain generation, model training, and test-time scaling strategies. Retrieval chains are generated using rejection sampling, where intermediate sub-queries and sub-answers are iteratively formed, and the chain with the highest log-likelihood score is selected to augment datasets. Using a multi-task learning framework, the model is trained on these augmented datasets for sub-query, sub-answer, and final answer prediction. At test time, decoding strategies like greedy decoding, best-of-N sampling, and tree search allow for controlling token consumption and retrieval steps. These approaches optimize the trade-off between performance and compute efficiency.
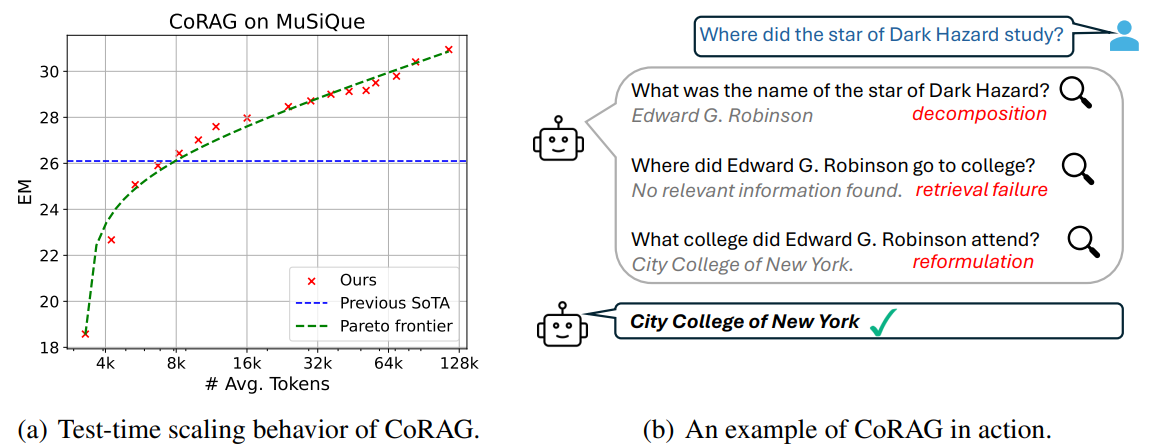
The evaluation of CoRAG was conducted using two benchmarks: (1) multi-hop QA datasets, including 2WikiMultihopQA, HotpotQA, Bamboogle, and MuSiQue, to test multi-hop reasoning, and (2) the KILT benchmark for generalization across knowledge-intensive tasks. Fine-tuning was performed on Llama-3.1-8B-Instruct using retrieval chain-augmented datasets. CoRAG-8B significantly outperformed baselines in most multi-hop QA datasets, except Bamboogle, where limited instances and outdated retrieval data caused variability. In the KILT benchmark, CoRAG achieved state-of-the-art performance across tasks, except for FEVER, where a larger model slightly surpassed it. Performance scaling experiments showed improvements with increased retrieval chain lengths and sampling strategies.
In conclusion, the study presents CoRAG, a framework that trains LLMs to retrieve and reason through complex queries iteratively. Unlike traditional RAG methods that rely on a single retrieval step, CoRAG dynamically reformulates queries during retrieval, enhancing accuracy. Intermediate retrieval chains are automatically generated using rejection sampling, eliminating the need for manual annotations. At test time, adaptive decoding strategies balance performance with computational efficiency. CoRAG achieves state-of-the-art results on multi-hop QA datasets and the KILT benchmark, outperforming larger models. Detailed analysis highlights its scaling and generalization capabilities, paving the way for advancing factual, grounded, and trustworthy AI systems in challenging tasks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 70k+ ML SubReddit.

The post Microsoft AI Introduces CoRAG (Chain-of-Retrieval Augmented Generation): An AI Framework for Iterative Retrieval and Reasoning in Knowledge-Intensive Tasks appeared first on MarkTechPost.
