


Out of the various methods employed in document search systems, “retrieve and rank” has gained quite some popularity. Using this method, the results of a retrieval model are re-ordered according to a re-ranker. Additionally, in the wake of advancements in generative AI and the development of Large Language Models (LLMs), rankers are now capable of performing listwise reranking tasks after analyzing complex patterns in language. However, a crucial problem exists that appears trivial but limits the overall effectiveness of these cascading systems.
The challenge of the bounded recall problem, where a document is irrevocably excluded from the final ranked list if it wasn’t retrieved in the initial phase, causes the loss of high-potential information. To solve this problem, researchers came up with an adaptive retrieval process. Adaptive Retrieval (AR) differentiates itself from previous works by leveraging the ranker’s assessments to expand the retrieval set dynamically. A clustering hypothesis is applied in this process to group similar documents that may be relevant to a query. Adaptive Retrieval (AR) could be better understood as a pseudo-relevance feedback mechanism that enhances the likelihood of including pertinent documents that may have been omitted during the initial retrieval.
Although AR serves as a robust solution in cascading systems, contemporary work in this vertical operates under the assumption that the relevance score depends only on the document and query, implying that one document’s score is computed independently of others. On the other hand, LLM-based ranking methods use signals from the entire ranked list to determine relevance. This article discusses the latest research that merges the benefits of LLMs with AR.
Researchers from the L3S Research Center, Germany, and the University of Glasgow have put forth SlideGar: Sliding Window-based Adaptive Retrieval to integrate AR with LLMs while accounting for the fundamental differences between their pointwise and listwise approaches. SlideGar modifies AR such that the resulting ranking function outputs a ranked order of documents rather than discrete relevance scores. The proposed algorithm merges results from the initial ranking with feedback documents provided by the most relevant documents identified up to that point.
The SlideGar algorithm utilizes AR methods like graph-based adaptive retrieval (Gar) and query affinity modeling-based adaptive retrieval (Quam) to find document neighbors in a constant amount of time. For LLM ranking, the authors employ a sliding window to overcome the constraint of input context. SlideGar processes the initial pool of documents given by the retriever for a specific query and, for a predefined length and step size, ranks the top w documents from left to right using a listwise ranker. These documents are then removed from the pool. The authors used the reciprocal of the rank as a pseudo-score for the documents.
The authors employed the MSMARCO corpus data for practical purposes and evaluated its performance on REC Deep Learning 2019 and 2020 query sets. They also used the latest versions of these datasets and de-duplicated them to remove redundancies. A variety of sparse and dense retrievers were utilized. For rankers, the authors employed different listwise rankers, including both zero-shot and fine-tuned models. The authors leveraged the open-source Python library, ReRankers, to apply these listwise re-rankers.
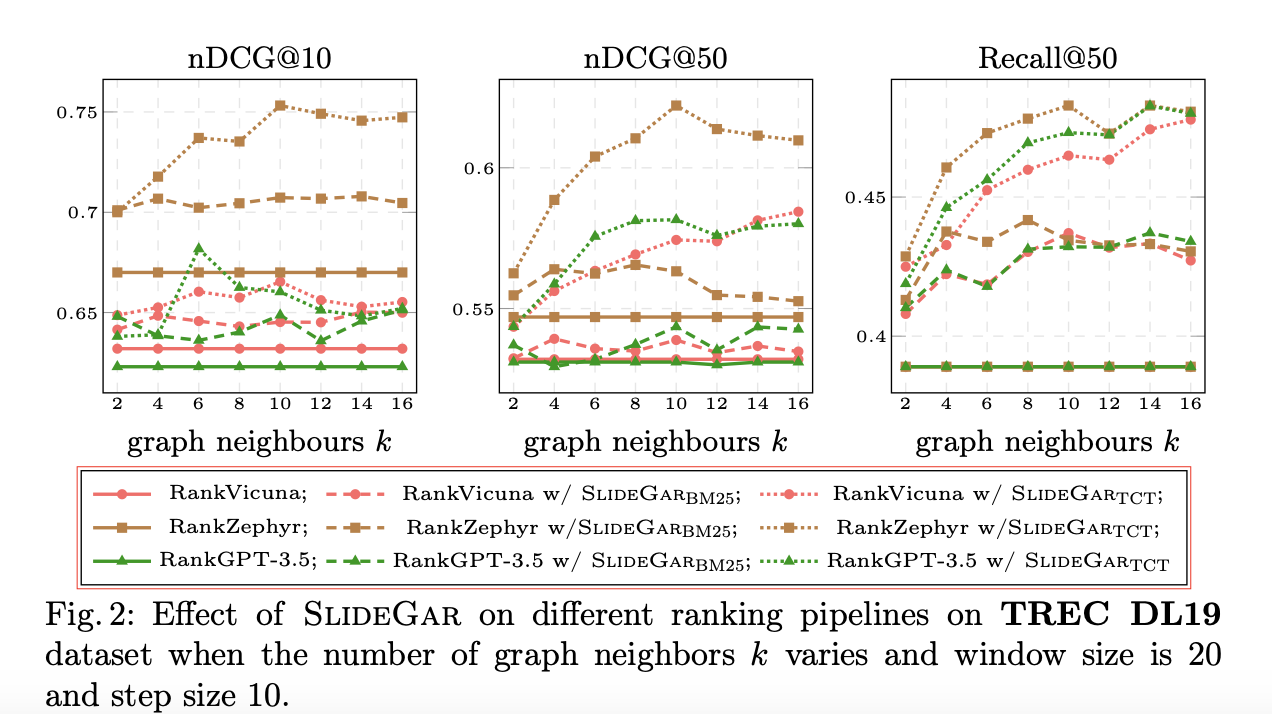
After conducting an extensive set of experiments across diverse LLM re-rankers, first-stage retrievers, and feedback documents, the authors ascertained that SlideGar improved the nDGC@10 score by up to 13% and recall by 28%, with a constant number of LLM inferences over the SOTA listwise rankers. Furthermore, regarding computation, the authors discovered that the proposed method adds negligible latency (a mere 0.02%).
Conclusion: In this research paper, the authors propose a new algorithm, SlideGar, that allows LLM re-rankers to address the challenge of bounded recall in retrieval. SlideGar merges the functionalities of AR and LLM re-rankers to complement each other. This work paves the way for researchers to further explore and adapt LLMs for ranking purposes.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 65k+ ML SubReddit.

The post SlideGar: A Novel AI Approach to Use LLMs in Retrieval Reranking, Solving the Challenge of Bound Recall appeared first on MarkTechPost.
