词袋模型没有考虑词的顺序和上下文信息,N-gram模型通过考虑文本中连续 n 个词的序列来捕捉词的顺序和局部上下文信息。n-gram 可以是 unigram(1-gram),bigram(2-gram),trigram(3-gram)等。假设有一个文档:"I love machine learning.":
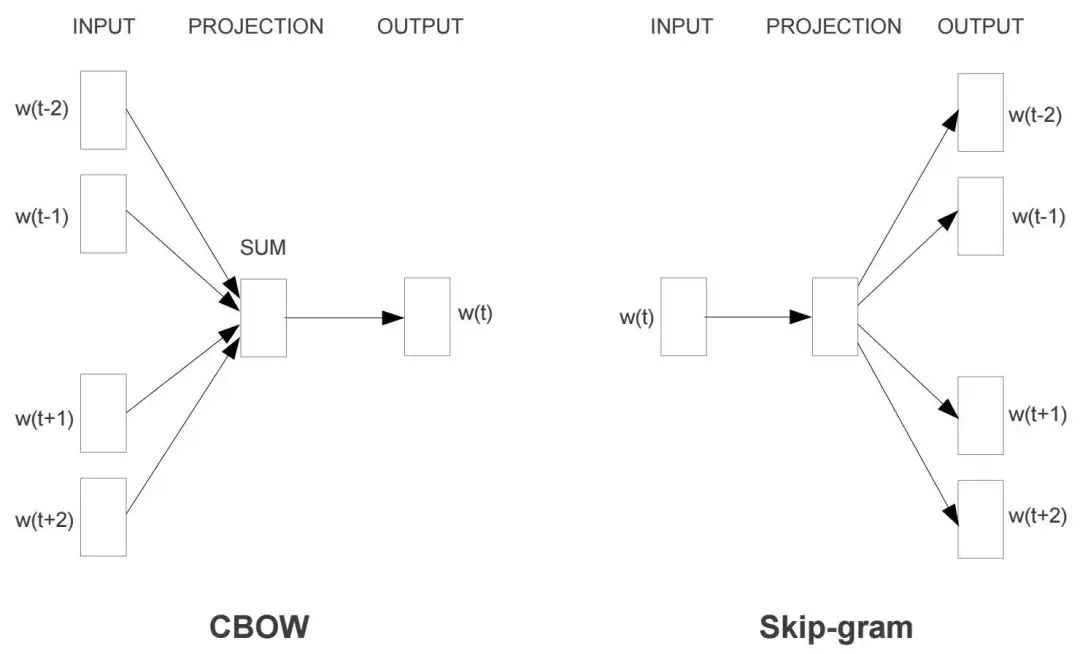
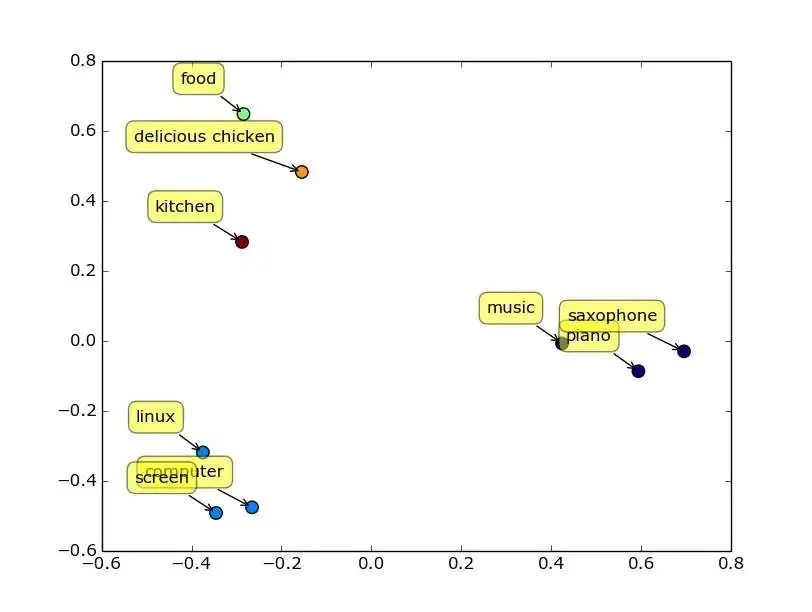
词向量(词嵌入,Word Embedding) 是将每个词都映射到低维空间上的一个稠密向量(Dense Vector)。这里的低维空间上的每一维也可以看作是中一个主题模型中的一个主题,只不过不像主题模型中那么直观(不具备可解释性)。词向量在学习时考虑到了当前词的上下文信息,以Word2Vec为例,它实际上是一种浅层的神经网络模型(输入层、映射层、输出层),它有两种网络结构,分别是CBOW和Skip-gram,参考下图:不管是CBOW还是Skip-gram,都是通过最大化上下文词出现的概率来进行模型的优化。其他常见的词嵌入方法,还有GloVe(Global Vectors for Word Representation)、FastText。词向量的几何性:词嵌入的向量空间具备几何性,因此允许使用向量之间的距离和角度来衡量相似性。常用的相似度度量包括:
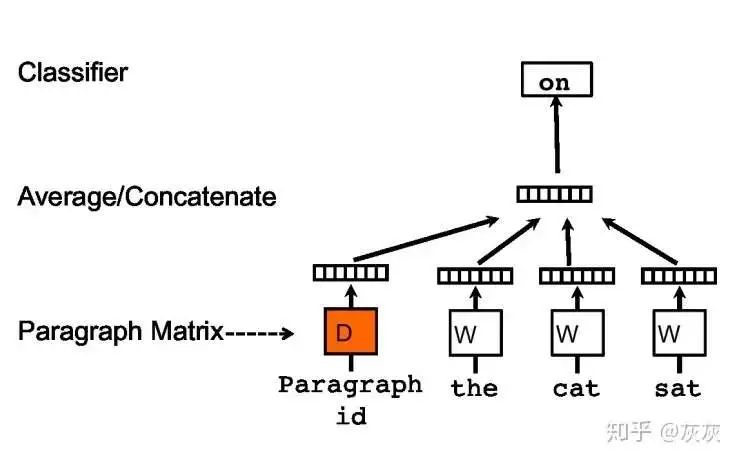
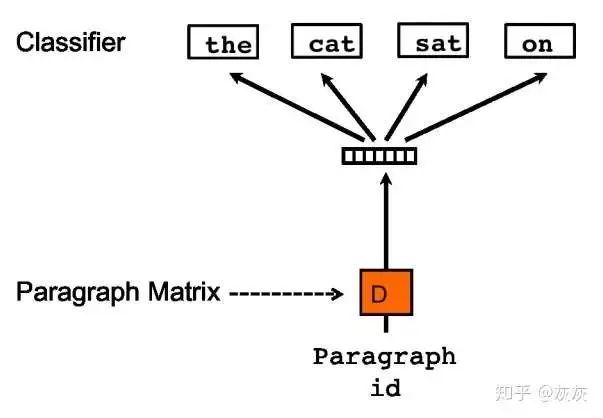
PV-DBOW(Distributed Bag of Words of paragraph vector)模型
给定一个文档D,随机选择一个目标词w_t使用文档D的向量预测目标词w_t
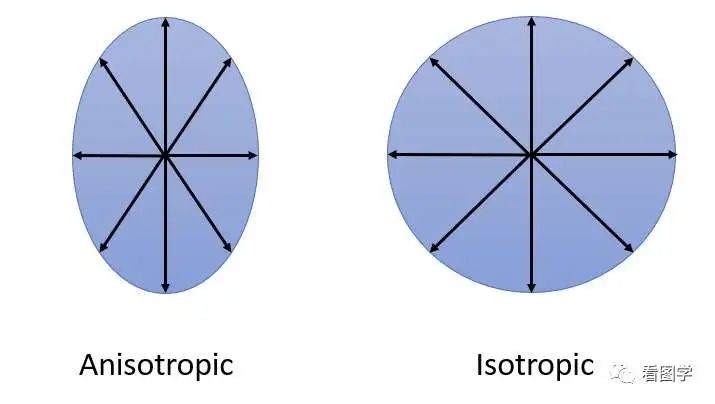
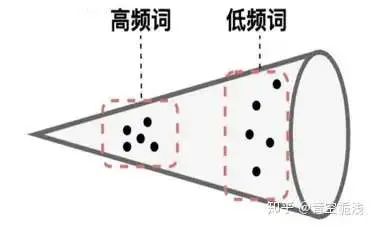
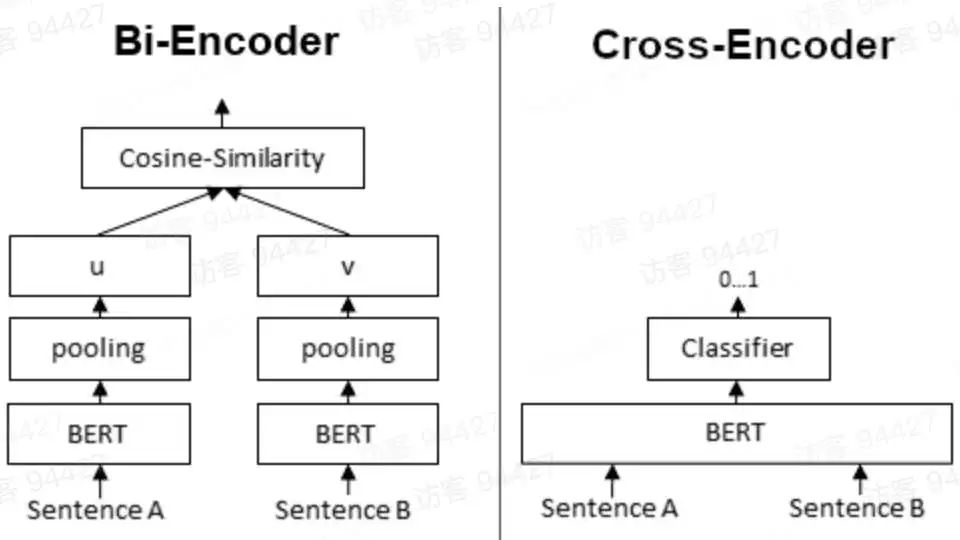
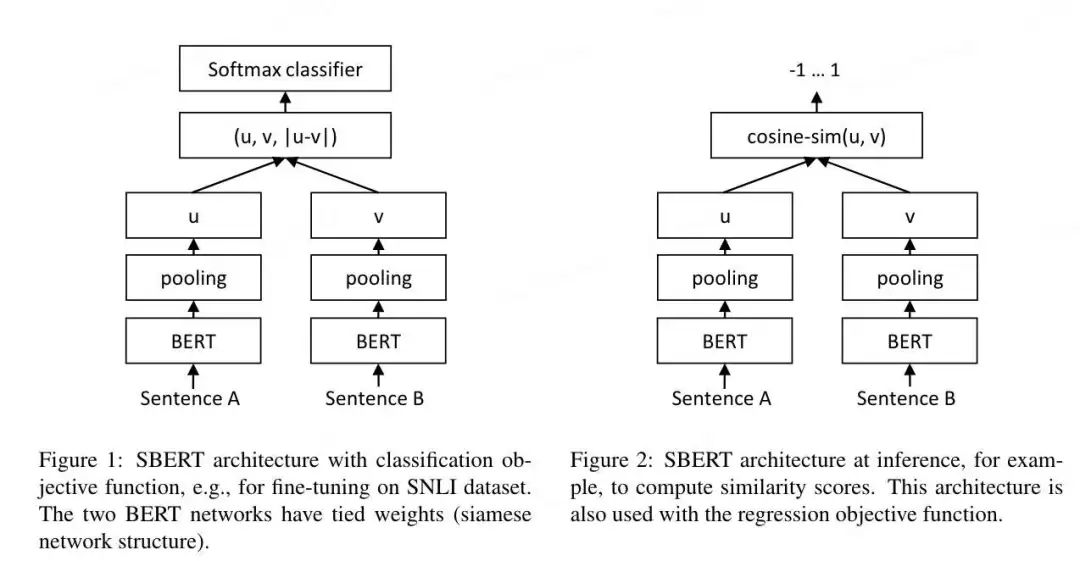
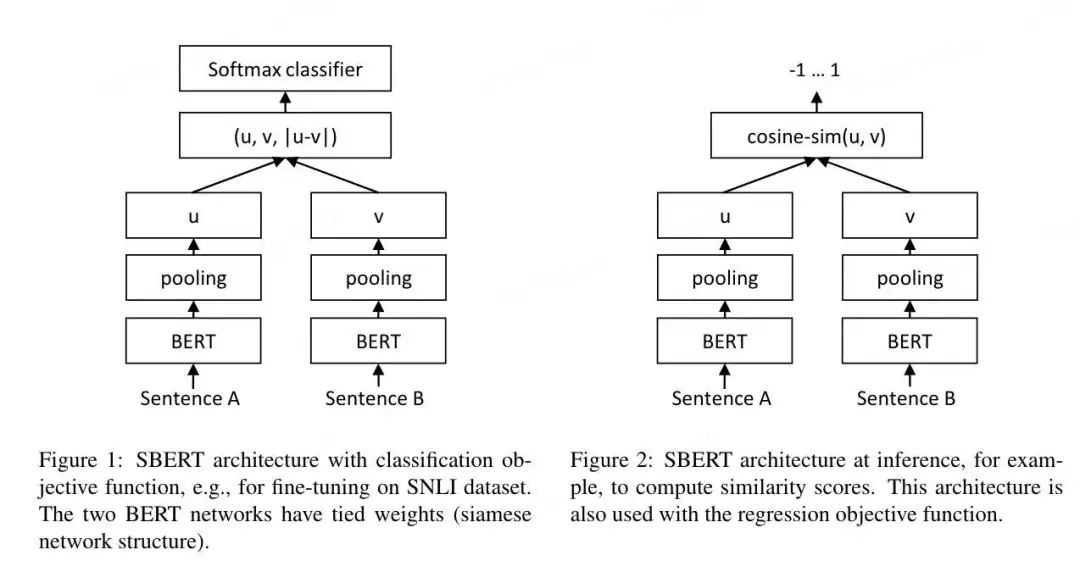
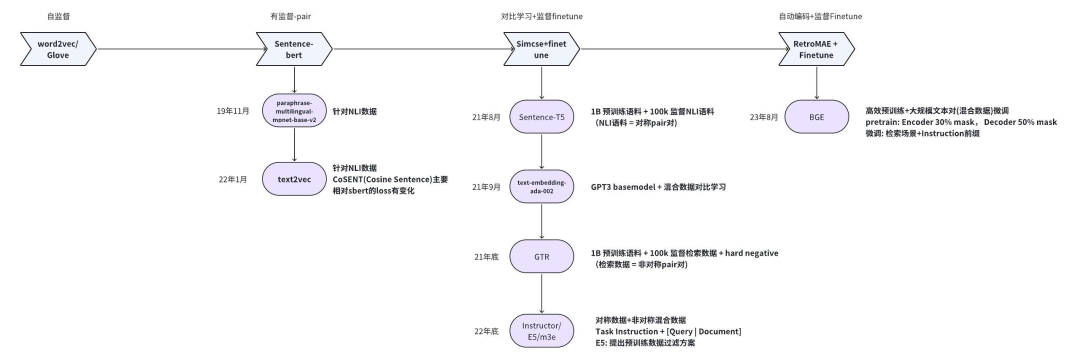
Doc2vec的推理优化:在预测新的*句子向量(推理)时,Paragraph vector首先被随机初始化,放入模型中再重新根据随机梯度下降不断迭代求得最终稳定下来的句子向量。与训练时相比,此时该模型的词向量和投影层到输出层的soft weights参数固定,只剩下Paragraph vector用梯度下降法求得,所以预测新句子时虽然也要放入模型中不断迭代求出,相比于训练时,速度会快得多。将文本输入Bert模型中后,通常使用最后一个隐藏层中[CLS]标记对应的向量或对最后一个隐藏层做MeanPooling,来获取该文本对应的向量表示。为什么Bert向量表示不能直接用于相似度计算?核心原因就是:各向异性(anisotropy)。各向异性是一个物理学、材料科学领域的概念,原本指材料或系统在不同方向上表现出不同物理性质的现象。作为吃货的我们肯定非常有经验,吃肉的时候顺纹切的肉比横纹切的肉更有嚼劲。类似的还有木头的顺纹和横纹的抗压和抗拉能力也不同,石墨单晶的电导率在不同方向差异很大。各向异性在向量空间上的含义就是分布与方向有关系,而各向同性就是各个方向都一样,比如二维的空间,各向异性和各向同性对比如下(左图为各向异性,右图为各向同性)。Bert的各向异性是指:“Anisotropic” means word embeddings occupy a narrow cone in the vector space.简单解释就是,词向量在向量空间中占据了一个狭窄的圆锥形体。Bert的词向量在空间中的分布呈现锥形,研究者发现高频的词都靠近原点(所有词的均值),而低频词远离原点,这会导致即使一个高频词与一个低频词的语义等价,但是词频的差异也会带来巨大的差异,从而词向量的距离不能很好的表达词间的语义相关性。另外,还存在高频词分布紧凑,低频词的分布稀疏的问题。分布稀疏会导致区间的语义不完整(poorly defined),低频词向量训练的不充分,从而导致进行向量相似度计算时出现问题。不只是Bert,大多数Transformer架构的预训练模型学习到的词向量空间(包括GPT-2),都有类似的问题(感兴趣的可以去看「Gao et al. 2019」https://arxiv.org/abs/1907.12009,「Wang et al. 2020」https://openreview.net/pdf?id=ByxY8CNtvr,「Ethayarajh, 2019」https://arxiv.org/abs/1909.00512):各项异性的缺点: 一个好的向量表示应该同时满足alignment和uniformity,前者表示相似的向量距离应该相近,后者就表示向量在空间上应该尽量均匀,最好是各向同性的。各向异性就有个问题,那就是最后学到的向量都挤在一起,彼此之间计算余弦相似度都很高,并不是一个很好的表示。各项异性问题的优化方法:有监督学习优化: 通过标注语料构建双塔Bert或者单塔Bert来进行模型微调,使靠近下游任务的Bert层向量更加靠近句子相似embedding的表达,从而使向量空间平滑。有监督学习优化的代表是SBERT。无监督学习优化:通过对Bert的向量空间进行线性变换,缓解各向异性的问题。无监督学习优化的代表是Bert-flow和Bert-whitening。基于对比学习的思想,通过对文本本身进行增广(转译、删除、插入、调换顺序、Dropout等),扩展出的句子作为正样本,其他句子的增广作为负样本,通过拉近正样本对的向量距离,同时增加与负样本的向量距离,实现模型优化,又叫自监督学习优化,代表就是SimCSE。BERT向量模型(SBERT模型)与BERT交互式语义模型(BERT二分类模型)的区别:SBERT模型通过对预训练的BERT结构进行修改,并通过在有监督任务(如自然语言推理、语义文本相似度)上进行微调,优化Bert向量直接进行相似度计算的性能。SBERT模型分为孪生(Siamese) 和三级(triplet) 网络,针对不同的网络结构,设置了三个不同的目标函数:Classification Objective Function:孪生(Siamese)网络训练,针对分类问题。上左图,u,v分别表示输入的2个句子的向量表示,*|u-v|*表示取两个向量element-wise的绝对值。模型训练时使用交叉熵损失函数计算loss。Regression Objective Function:孪生(Siamese)网络训练,针对回归问题。上右图,直接计算u,v向量的余弦相似度,训练时使用均方误差(Mean Squared Error, MSE)进行loss计算。3.Triplet Objective Function:三级(triplet)网络训练,模型有变成三个句子输入。给定一个锚定句?,一个肯定句?和一个否定句?,模型通过使?与?的距离小于与?与?的距离,来优化模型,即其中,? 表示边距,在论文中,距离度量为欧式距离,边距大小为1。同一时间的其他针对句向量的研究,「USE(Universal Sentence Encoder)」https://arxiv.org/abs/1803.11175、「InferSent」https://arxiv.org/abs/1705.02364等,他们的共性在于都使用了“双塔”类的结构。
关于自然推理任务?自然语言推理(Natural Language Inference, NLI)是自然语言处理(NLP)中的一个重要任务,旨在判断两个给定句子之间的逻辑关系。具体来说,NLI任务通常涉及三个主要的逻辑关系:蕴含(Entailment):前提(Premise)蕴含假设(Hypothesis),即如果前提为真,则假设也为真。矛盾(Contradiction):前提与假设相矛盾,即如果前提为真,则假设为假。中立(Neutral):前提与假设既不蕴含也不矛盾,即前提为真时,假设可能为真也可能为假。使用NLI的标注数据集(SNLI,MNLI等)训练出的语义向量模型,展现出了较好的语义扩展性和鲁棒性,适合进行zero-shot或者few-shot。
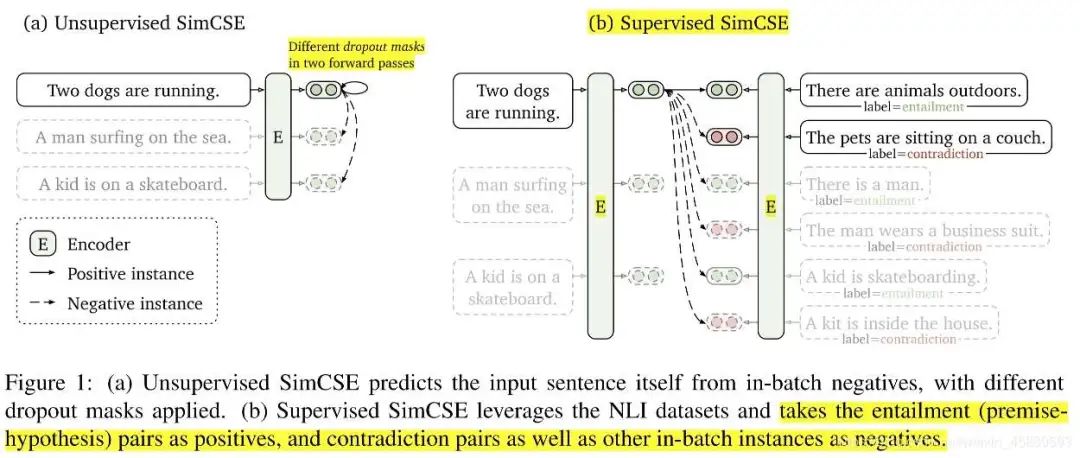
既然Bert向量空间不均匀,那就想办法把该向量空降映射一个均匀的空间中,例如标准高斯(Standard Gaussian) 分布。「BERT-flow」https://arxiv.org/abs/2011.05864,就是基于流式生成模型,将BERT的表示可逆地映射到一个标准高斯分布上。具体做法是,在Bert后面接一个flow模型,flow模型的训练是无监督的,并且Bert的参数是不参与训练,只有flow的参数被优化,而训练的目标则为最大化预先计算好的Bert的句向量的似然函数。训练过程简单说就是学习一个可逆的映射?,把服从高斯分布的变量?映射到BERT编码的?,那?−1就可以把?映射到均匀的高斯分布,这时我们最大化从高斯分布中产生BERT表示的概率,就学习到了这个映射:关于流式生成模型的原理,感兴趣的自己看:ICLR 2015 NICE-Non-linear Independent Components EstimationICLR 2017 Density estimation using Real NVPNIPS 2018 Glow: Generative Flow with Invertible 1×1 Convolutions「Bert-whitening」(https://spaces.ac.cn/archives/8069)的作者就是苏神@苏剑林(https://www.zhihu.com/people/su-jian-lin-22),他首先分析了余弦相似度的假定:余弦相似度的计算为两个向量的内积除以各自的模长,而该式子的局限性为仅在标准正交基下成立。同时,经过假设分析,得出结论:一个符合“各向同性”的空间就可以认为它源于标准正交基。他觉得Bert-flow虽然有效,但是训练flow模型太麻烦,可以找到一个更简单的方式实现空间转换。标准正态分布的均值为0、协方差矩阵为单位阵,它的做法就是将Bert向量的均值变换为0、协方差矩阵变换为单位阵,也就是传统数据挖掘中中的**白化(whitening)**操作。对比学习(Contrastive learning) 的目的是通过将语义上接近的邻居拉到一起,将非邻居推开,从而学习有效的表征(「Hadsell et al., 2006」(https://ieeexplore.ieee.org/document/1640964))。SBert模型本身也是一种对比学习的体现,但是它需要进行有监督训练,依赖标注数据,因此无法在大规模的语料下进行训练。如果能找到一种方法,能够基于文本预料自动生成用于SBert模型训练的数据,就可以解决数据标注依赖的问题。基于对比学习的无监督学习方法,就是通过对文本本身进行传统的文本增广(如转译、删除、插入、调换顺序等等),并将增广后得到的文本作为正样本(即假设文本增广前后,语义相似),同时取同一batch下,其他句子的增广结果作为负样例,就得到了可以进行SBert(或同类模型)训练的预料。而SimCSE(https://arxiv.org/abs/2104.08821)发现,发现利用预训练模型中自带的Dropout mask作为“增广手段”得到的Sentence Embeddings,其质量远好于传统的文本增广方法:利用模型中的Dropout mask,对每一个样例进行两次前向传播,得到两个不同的embeddings向量,将同一个样例得到的向量对作为正样本对,对于每一个向量,选取同一个batch中所有样例产生的embeddings向量作为负样本,以此来训练模型。训练损失函数为:SimCSE也提供了有监督学习的训练范式,利用NLI标注数据集进行训练,将每一个样例和与其相对的entailment作为正样本对,同一个batch中其他样例的entailment作为负样本,该样本相对应的contradiction作为hard negative进行训练。训练损失函数为:


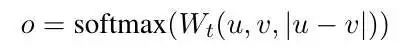

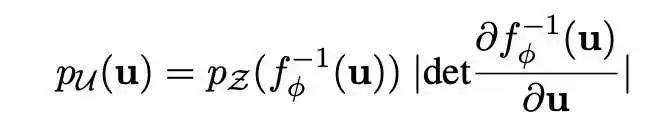
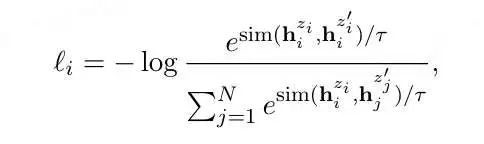
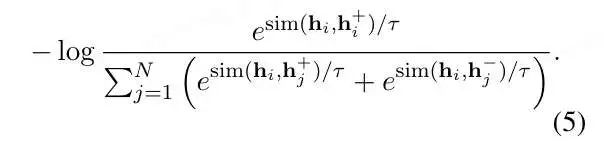
 一起“点赞”三连↓
一起“点赞”三连↓