
Transformer后继者终于现身!
2017年,Attention Is All You Need首次引入注意力机制,成为现代LLM诞生标志。
虽然Transformer依然大行其道,但其架构的缺陷却饱受诟病,尤其是无法扩展更长上下文。
正所谓,「风浪越大,鱼越贵!」
近日,谷歌研究团队迎难而上,提出支持200K上下文处理窗口的新架构——Titans。
最重要的是,轻松扩展到2M上下文的Titans架构,要比Transformer和线性RNN更加有效。
论文链接:https://arxiv.org/abs/2501.00663

Titans是什么
研究者认为大多数现有架构将记忆视为由输入引起的神经更新,并将学习定义为在给定目标的情况下有效获取有用记忆的过程。
从这个角度来看,循环神经网络(RNN)可以被定义为具有向量值记忆模块ℳ(也称为隐藏状态)的模型,其主要步骤包括:在时间t给定新输入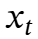 时,
时,
(1)使用函数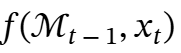 更新记忆(带有压缩);
更新记忆(带有压缩);
(2)使用函数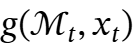 检索输入的相应记忆。
检索输入的相应记忆。
类似地,Transformer可以被视为具有不断增长的记忆和两个相似步骤的架构。即:
(1)通过将键和值附加到记忆中来更新记忆(无压缩);
(2)通过查找查询向量与键向量的相似性来检索查询向量的相应记忆,然后将其用于加权值向量以生成输出。
由于记忆分为短期记忆、工作记忆和长期记忆,而其中每个部分都相互独立地服务于不同的场景,也具有不同的神经结构。
受此启发,研究者提出了两个问题:
1. 如何设计一个高效架构,将不同且相互关联的记忆模块整合起来?
2. 是否需要一个深度记忆模块,以有效存储和记住长期历史信息?
本研究旨在通过设计一个长期神经记忆模块来解决上述问题,神经长期记忆模块的设计受到人类长期记忆系统的启发,能存储和检索过去的信息。
该模块不是无差别地记住所有信息,而是会通过「惊讶度」来选择性地记住那些重要或令人惊讶的信息。
并且其记忆不是静态的,可以根据新的信息动态更新。这种动态更新机制类似于人类的学习过程,使得模型能够不断适应新的数据和任务需求。
为了更好地管理有限的内存,模块引入了衰减机制。该机制根据记忆的大小和数据的惊讶程度来调整记忆的权重,从而优化内存管理。
长期神经记忆模块设计完成后,面临的一个关键问题是如何把记忆高效地整合进深度学习架构。研究者提出了Titans架构,由三个模块构成:
1. 核心模块(Core):包含短期记忆,负责主要的数据处理流程,采用具有有限窗口大小的注意力机制。
2. 长期记忆模块(Long-term Memory):此模块是研究者设计的神经长期记忆模块,负责存储和记住远距离的历史信息。
3. 持久记忆模块(Persistent Memory):这是一组可学习但与数据无关的参数,主要用于对任务知识进行编码,为模型提供先验知识储备。
在此基础上,研究者提出了Titans架构的三种变体:
记忆作为上下文(MAC)架构
核心分支把对应的长期记忆、持久记忆和当前输入信息拼接在一起,然后用注意力机制来处理上下文,并决定哪些信息应存储在长期记忆中。
在测试时,与上下文记忆对应的参数仍在学习,与核心分支对应的参数负责上下文学习,而持久记忆的参数则负责存储任务相关知识,因此是固定的。
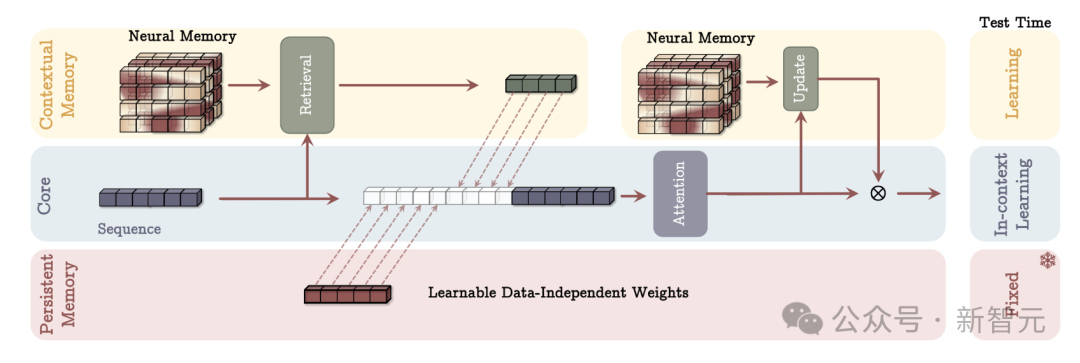
记忆作为门控(MAG)架构
在此架构中,一个分支用输入数据更新长期记忆,另一个分支使用滑动窗口注意力(SWA),最后将两者结果通过门控机制组合。
在此设计中,滑动窗口注意力充当精确的短期记忆,而神经记忆模块则作为模型的衰减记忆。这种架构设计也可视为一种多头架构,其中头的结构各不相同。
与MAC架构不同的是,MAG架构仅将持久记忆融入上下文,并通过门控机制将记忆与核心分支结合。门控机制决定了来自持久记忆的信息在多大程度上影响核心分支的处理结果。
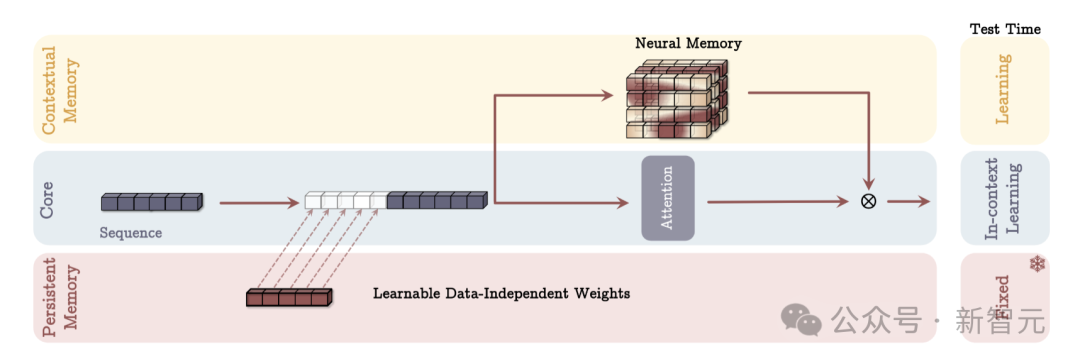
记忆作为层(MAL)架构
将神经记忆模块作为深度神经网络的一层,结合滑动窗口注意力机制。记忆层的核心功能是对过去和当前的上下文信息进行压缩处理,之后将处理结果传递给注意力模块。

在测试时去学习记忆
神经长期记忆模块
对于神经网络来讲,记忆能力通常反而会限制模型的泛化能力,并可能引发隐私问题,导致在测试时性能下降。
此外,由于测试数据可能属于分布外数据,训练数据的记忆在测试时可能就并没有什么效用。
因此,研究者认为,训练长期记忆的关键思想是将其训练视为一个在线学习问题,学会在测试时如何记住或忘记数据。在这种设置中,模型学习的是一个能够记忆的函数,但不会过拟合训练数据,从而在测试时实现更好的泛化。
学习过程与目标函数:由于令人惊讶的事件对人类来说更易记住。受此启发,作者将「惊讶度」定义为相对于输入的梯度。梯度越大,输入数据与过去数据的差异就越大。因此,利用这个惊讶度,我们可以更新记忆如下:
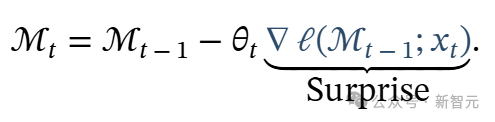
如此就能将过去的信息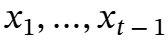 压缩到长期神经记忆模块
压缩到长期神经记忆模块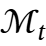 的参数中。
的参数中。
然而,这种惊讶度的度量方法也可能会导致错过一些重要信息。也就是说,在若干个惊讶步骤之后,梯度可能变得非常小,从而导致陷入平坦区域(即局部最小值),错失序列中的某些信息。
而从人类记忆的角度来看,某个事件虽然值得记住,但可能不会在很长时间内一直让我们感到惊讶。
因此为了改进上述惊讶度度量,作者将惊讶度度量分为两部分:(1)过去的惊讶,衡量最近过去的惊讶度;(2)瞬时惊讶,衡量即将到来的数据的惊讶度。
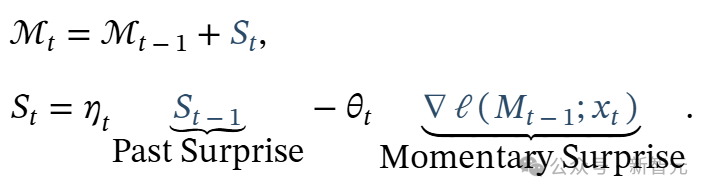
在此公式中,项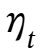 是数据依赖的惊喜衰减,控制着惊喜随时间如何衰减;而项 θt 则控制着应以数据依赖的方式将多少瞬时惊喜纳入最终的惊喜度量中。
是数据依赖的惊喜衰减,控制着惊喜随时间如何衰减;而项 θt 则控制着应以数据依赖的方式将多少瞬时惊喜纳入最终的惊喜度量中。
这种数据依赖性在此设计中尤为重要:虽然前一个标记的惊喜可能影响下一个标记的惊喜,但这主要在所有标记相关且处于同一上下文时才有效。
因此,数据依赖的η可以控制记忆是否需要:
(1)通过设置→0忽略上一次的惊喜(可能由于上下文的变化)
(2)通过设置→1完全纳入上一次的惊喜(可能因为该标记与其最近的过去标记高度相关)。
在本工作中,作者专注于关联记忆,旨在将过去的数据存储为键值对。即给定 ,类似于Transformers,使用两个线性层将其投影为键和值:
,类似于Transformers,使用两个线性层将其投影为键和值:

接着,作者希望记忆模块能够学习键和值之间的关联。为此,定义损失函数如下:
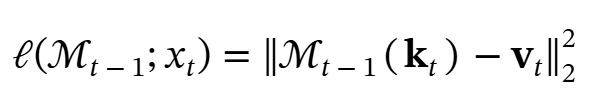
通过在元模型的内循环中优化上述损失函数,模型就可以学会如何在测试时记忆键与值之间的映射。
遗忘机制:在处理非常大的序列(例如,数百万个标记)时,明确哪些过去信息应该被遗忘至关重要。为此,作者使用了一种自适应遗忘机制,允许内存遗忘不再需要的信息,从而更好地管理内存的有限容量。也就是说,给定下一个标记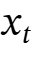 ,然后将更新规则修改为:
,然后将更新规则修改为:
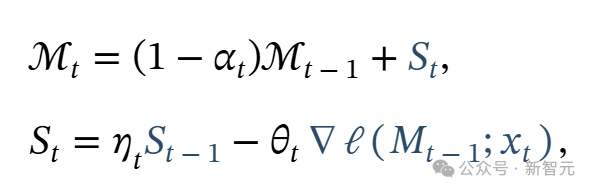
其中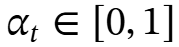 是灵活控制记忆的门控机制;即决定应遗忘多少信息。例如,它可以通过让
是灵活控制记忆的门控机制;即决定应遗忘多少信息。例如,它可以通过让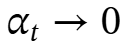 来更新记忆而不影响过去的抽象,并可以通过让
来更新记忆而不影响过去的抽象,并可以通过让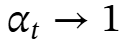 来清除整个记忆。
来清除整个记忆。
检索记忆:作者简单地使用不更新权重的前向传递(即推理)来检索与查询对应的记忆。形式上,给定输入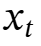 ,使用线性层 WQ 来投影输入,即
,使用线性层 WQ 来投影输入,即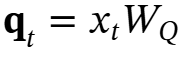 ,并通过以下方式从记忆
,并通过以下方式从记忆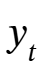 中检索相应(或有用的)信息:
中检索相应(或有用的)信息:
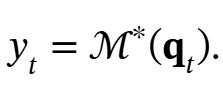
实验结果
Ali Behrouz

Peilin Zhong

Vahab Mirrokni




内容中包含的图片若涉及版权问题,请及时与我们联系删除
