
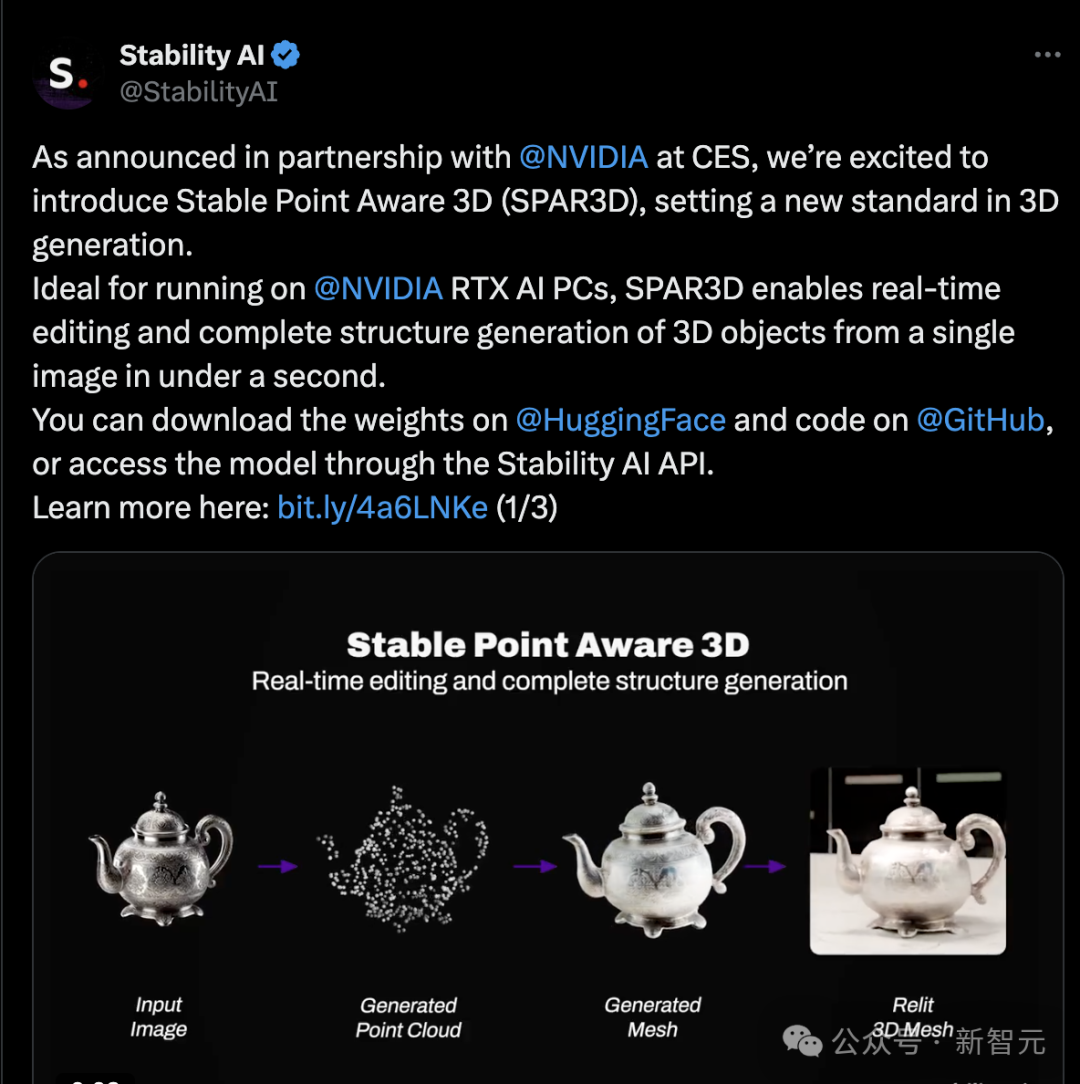
近日,Stability AI发布消息,公开3D重建新方法SPAR3D的设计原理、代码、模型权重等。


架构设计
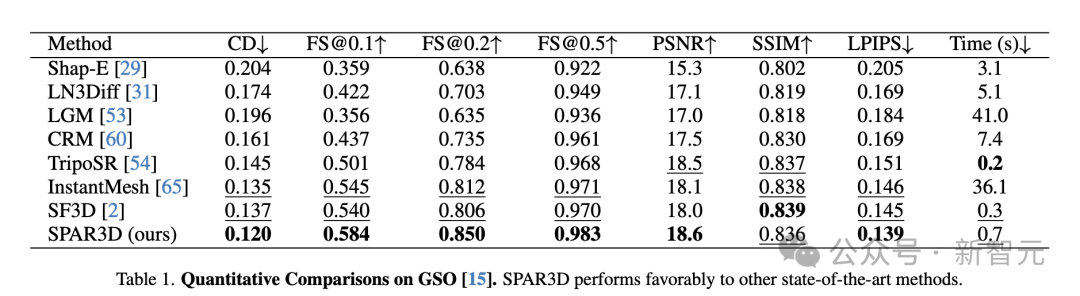
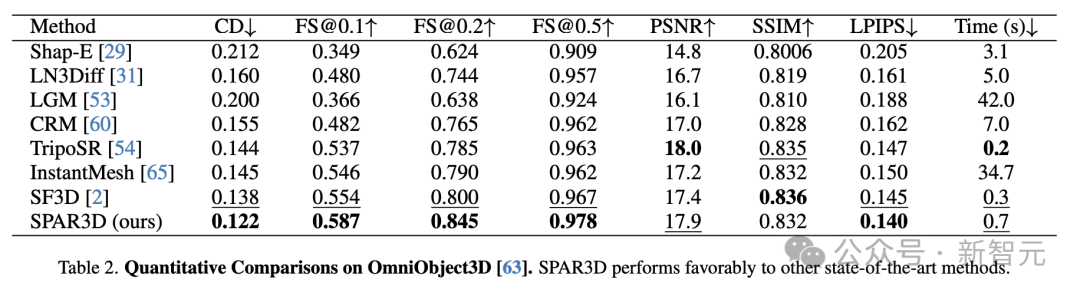
定量比较
在GSO和Omniobject3D数据集上定量比较了SPAR3D与其他基准方法。
如表1和表2所示,SPAR3D在这两个数据集的大多数指标上显著优于所有其他回归或生成基准方法。
SPAR3D也是可以做到1秒内完成重建的模型之一,每个物体的推理速度为0.7秒,显著快于基于3D或多视图的扩散方法。
简而言之,比SPAR3D快的没它好,比它好的没它快。
定性结果
纯回归方法如SF3D或TripoSR重建的网格与输入图像对齐良好,但背面往往不够精确且过度平滑。
基于多视图扩散的方法,如LGM、CRM和InstantMesh,在背面展示了更多的细节。然而,合成视角中的不一致性导致了明显的伪影,整体效果更差。
纯生成方法如Shap-E和LN3Diff能够生成锐利的表面。然而,许多细节是错误的虚拟幻象,未能准确地遵循输入图像,且可见表面重建得也不正确。
与先前的工作相比,SPAR3D生成的网格不仅忠实地再现了输入图像,还展现了生成得当的遮挡部分,细节合理。

作者进一步展示了SPAR3D在自然图像上的定性结果。
这些图像通过文本-图像模型生成,或来自ImageNet验证集。高质量的重建网格展示了SPAR3D的强泛化能力。

编辑效果
使用显式点云作为中间表示,能够实现对生成网格的交互式编辑。
用户可以通过操控点云轻松地改变网格的不可见表面。
在图7中,展示了一些使用SPAR3D进行编辑的示例,用户可以通过添加主要物体部件来改进重建,或改善不理想的生成细节。
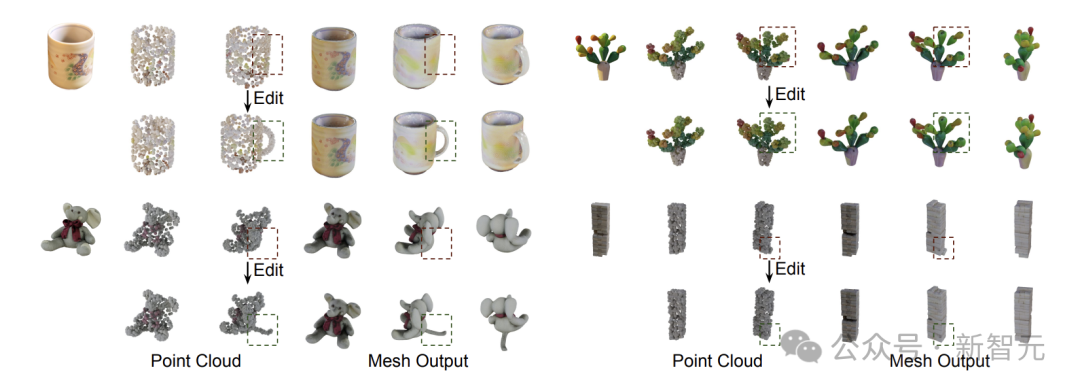
图7:编辑效果
在左侧的两个例子中,通过复制现有点云,为马克杯添加了把手,为大象添加了尾巴。在右侧的两个例子中,通过移动或删除点云,修复了不完美之处,并改善了网格的局部细节。所有编辑耗时不到一分钟。
实验分析
为了进一步了解SPAR3D的工作原理,作者设计了新的实验。
设计SPAR3D时的核心假设是:两阶段设计有效地将单目三维重建问题中的不确定部分(背面建模)和确定部分(可见表面建模)分开。
理想情况下,网格化阶段应主要依赖输入图像重建可见表面,同时依赖点云生成背面表面。
为了验证这一假设,作者设计了一个实验,特意使用与输入图像冲突的点云。
在图8中,将一只松鼠的输入图像和一匹马的点云输入网格模型。

图8:正面看像松鼠,侧面看像马。
如图所示,重建的网格在可见表面上与松鼠图像很好地对齐,而背面表面则主要遵循点云。这一结果验证了假设。
在图像和点云冲突的情况下,模型根据图像重建可见表面,同时根据点云生成背面表面。
作者介绍

Zixuan Huang,伊利诺伊大学香槟分校在读博士,在Stable AI主导了此次工作。
之前,在威斯康星大学麦迪逊分校获得计算机科学硕士学位,在中国科学技术大学获得学士学位。
https://x.com/StabilityAI/status/1877079954267189664
https://stability.ai/news/stable-point-aware-3d?utm_source=x&utm_medium=social&utm_campaign=SPAR3D
https://arxiv.org/pdf/2501.04689



内容中包含的图片若涉及版权问题,请及时与我们联系删除
