


Developing Graphical User Interface (GUI) Agents faces two key challenges that hinder their effectiveness. First, existing agents lack robust reasoning capabilities, relying primarily on single-step operations and failing to incorporate reflective learning mechanisms. This usually leads to errors being repeated in the execution of complex, multi-step tasks. Most current systems rely very much on textual annotations representing GUI data, such as accessibility trees. These lead to two types of consequences: information loss and computational inefficiency; but they also cause inconsistencies among platforms and reduce their flexibility in actual deployment scenarios.
The modern methods for GUI automation are multimodal large language models used together with vision encoders for understanding and interaction with GUI settings. Efforts such as ILuvUI, CogAgent, and Ferret-UI-anyres have advanced the field by enhancing GUI understanding, utilizing high-resolution vision encoders, and employing resolution-agnostic techniques. However, these methods exhibit notable drawbacks, including high computational costs, limited reliance on visual data over textual representations, and inadequate reasoning capabilities. The methodological constraints impose considerable constraints on their ability to perform real-time tasks and the complexity of executing complex sequences. This severely restricts their ability to dynamically adapt and correct errors during operational processes because of the lack of a robust mechanism for hierarchical and reflective reasoning.
Researchers from Zhejiang University, Dalian University of Technology, Reallm Labs, ByteDance Inc., and The Hong Kong Polytechnic University introduce InfiGUIAgent, a novel multimodal graphical user interface agent that addresses these limitations. The methodology is built upon the sophisticated inherent reasoning capabilities through a dual-phase supervised fine-tuning framework to be able to adapt and be effective. The training in the first phase focuses on developing the base capabilities by using diverse datasets that can improve understanding of graphical user interfaces, grounding, and task adaptability. The datasets used, such as Screen2Words, GUIEnv, and RICO SCA, cover tasks such as semantic interpretation, user interaction modeling, and question-answering-based learning, which makes the agent equipped with comprehensive functional knowledge.
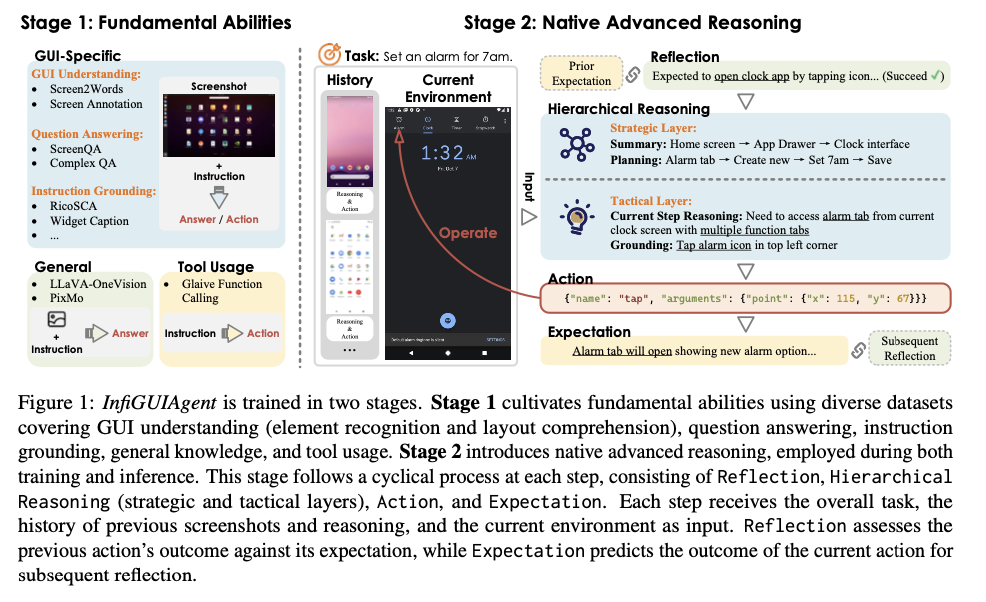
In the next phase, advanced reasoning capabilities are incorporated through synthesized trajectory information, thus supporting hierarchical and expectation-reflection reasoning processes. The hierarchical reasoning framework contains a bifurcated architecture: a strategic component focused on task decomposition and a tactical component on accurate action selection. Expectation-reflection reasoning allows the agent to adjust and self-correct through the assessment of what was expected versus what happened, thus improving performance in different and dynamic contexts. This two-stage framework enables the system to natively handle multi-step tasks without textual augmentations, hence allowing for higher robustness and computational efficiency.
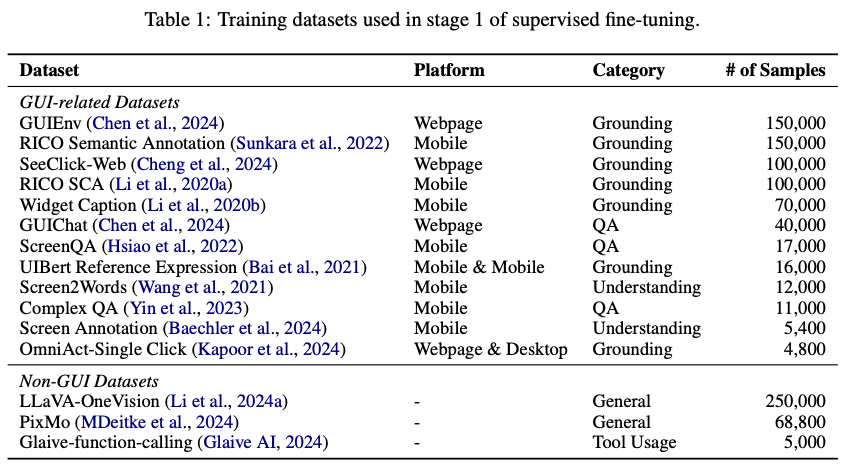
InfiGUIAgent was implemented by fine-tuning Qwen2-VL-2B using ZeRO0 technology for efficient resource management across GPUs. A reference-augmented annotation format was used to standardize and improve the quality of the dataset so that GUI elements could be precisely spatially referenced. Curating the datasets increases GUI comprehension, grounding, and QA capabilities to perform tasks such as semantic interpretation and modeling of interaction. The synthesized data was then used for reasoning to ensure that all task coverage was covered through trajectory-based annotations similar to real-world interactions with the GUI. Such modularity in action space design lets the agent respond dynamically to multiple platforms, which gives it greater flexibility and applicability.
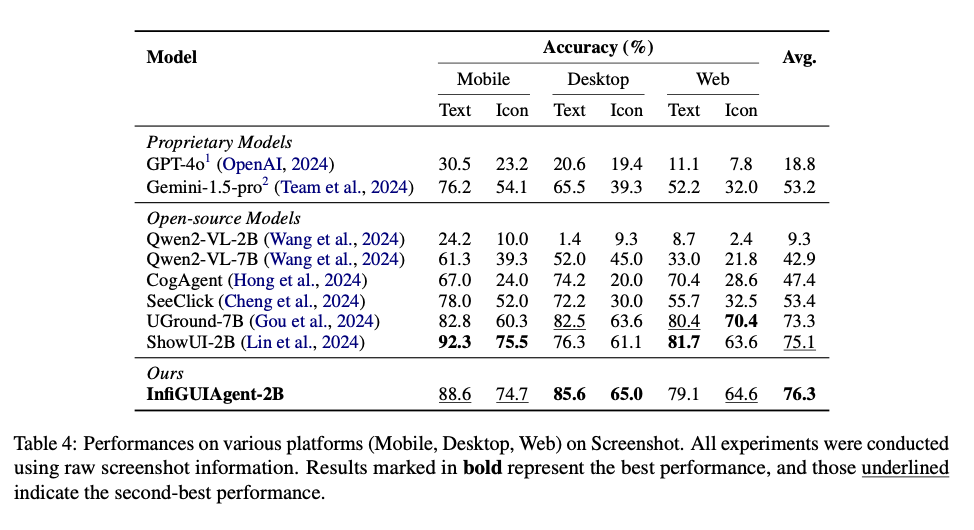
InfiGUIAgent did exceptionally well in benchmark tests, far surpassing the state-of-the-art models both in accuracy and adaptability. It managed to achieve 76.3% accuracy on the ScreenSpot benchmark, showing a higher ability to ground GUI across mobile, desktop, and web platforms. For dynamic environments such as AndroidWorld, the agent was able to have a success rate of 0.09, which is greater than other similar models with even higher parameter counts. The results confirm that the system can proficiently carry out complex, multistep tasks with precision and adaptability while underlining the effectiveness of its hierarchical and reflective reasoning models.
InfiGUIAgent represents a breakthrough in the realm of GUI automation and solves key reasons why existing tools suffer from important limitations in reasoning and adaptability. Without requiring any textual augmentations, this state-of-the-art performance is derived by integrating mechanisms for hierarchical task decomposition and reflective learning into a multimodal framework. The new benchmarking provided here forms an opening for developing the next-generation GUI agents seamlessly embeddable in real applications for efficient and robust task execution.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 65k+ ML SubReddit.
 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
The post InfiGUIAgent: A Novel Multimodal Generalist GUI Agent with Native Reasoning and Reflection appeared first on MarkTechPost.
