
Published on January 10, 2025 6:53 AM GMT
In my previous post, I explored the distributional properties of transformer activations, finding that they follow mixture distributions dominated by logistic-like or even heavier tailed primary components with minor modes in the tails and sometimes in the shoulders. Note that I have entirely ignored dimension here, treating each value in an activation vector as an independent draw from the distribution of values for that layer, model, and input class. This post extends the previous analysis by asking whether we can leverage these distributions to predict properties of input text. We demonstrated that we can. We can do even better prediction when we look only at points drawn from minor mixture distributions on the tails of the primary mixture distribution!
Methodology
Using the same dataset from the previous post of sentences generated by Claude 3.5 Sonnet across ten subjects and twelve attributes, I analyzed six models: Pythia-160m, Pythia-410m, Pythia-1b, GPT2-Small, GPT2-Medium, and GPT2-Large. For each subject-attribute pair (e.g., "about computer science" and "in all upper case"), I split the data 80/20 into train/test sets.
With the training data for each model, layer, and subject-attribute pair, I estimated the empirical distribution of residual stream activation values using Gaussian kernel density estimation. Given a test sentence with true categories , I computed the empirical log-likelihoods under each potential category pair as:where is the density estimated from training data for the activation vector values for category pair at layer in model , and is a small scalar added to ensure numerical stability. In the results below we look at both the maximum likelihood subject-attribute pairs and at performance considering the subject or attribute separately. To illustrate the latter case, when considering sentence attribute, MLEs of 'about economics'-'in all lower case' and 'about American football'-'in all lower case' would both count as correct predictions if the true sentence attribute was 'in all lower case'.
Critically, I performed this analysis twice: once using full activation vectors; and once considering only "tail values" - those located in the minor modes in the tails of the dominant mixture distribution. When using only tail values, the number of points to be considered varies from sample to sample. So rather than the sum of the densities over all values in the activation vector, I used the mean of the log-likelihoods over all values on the tails, with a minimum of three. If three or fewer values appear on the tails, then a minimum likelihood of is reported for that layer.
Key Findings
The Power of Extremes
Perhaps the most surprising finding was the effectiveness of analyzing only extreme activation values. The "tails-only" analysis failed almost entirely for the Pythia-160m and Pythia-410m models. But for the other four models, the tails only analysis improved the average F1 score for prediction of sentence subject by 0.03 and for sentence attribute by 0.06. Given current analysis, there is no clear reason why the two smaller Pythia models failed while the others performed so well. More investigation would be required to answer this question
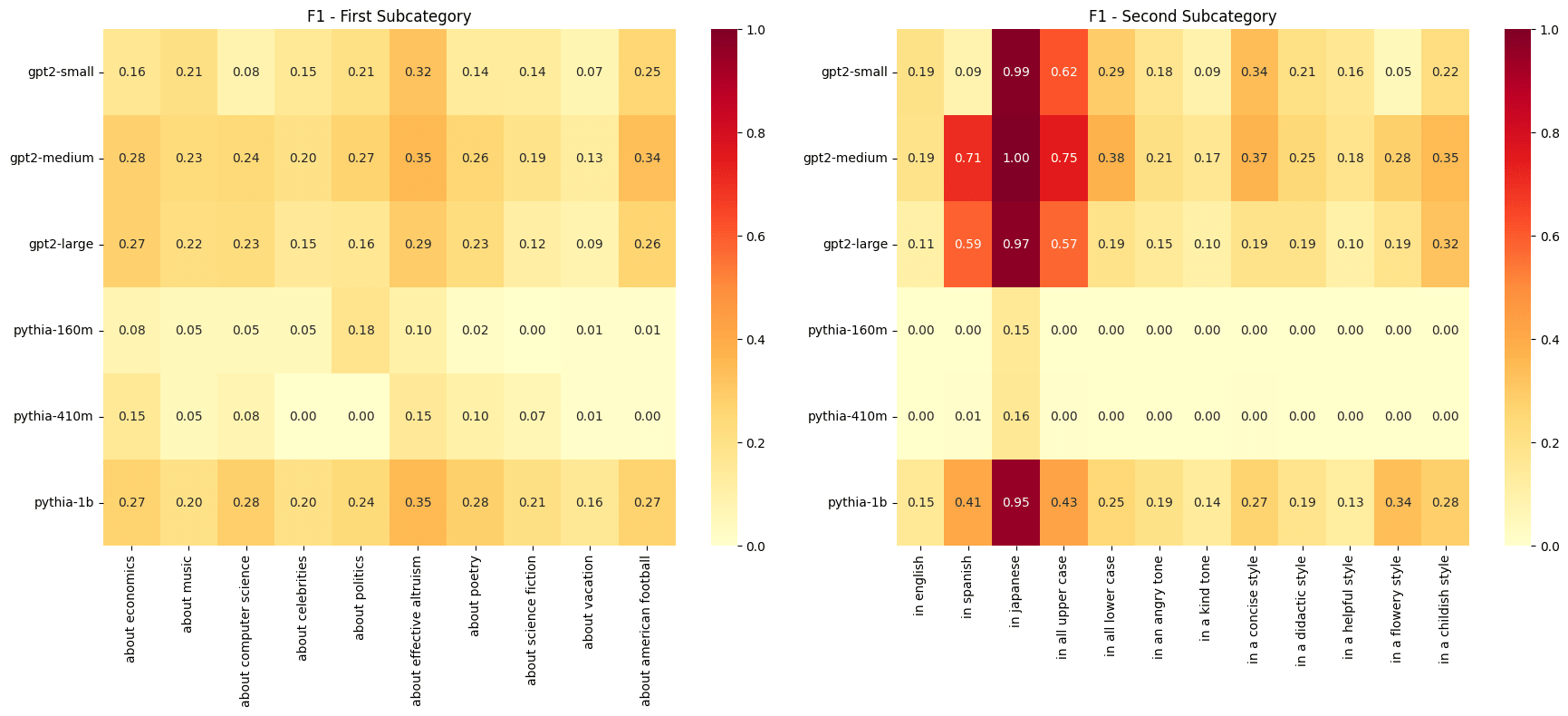
- F1 results for the tails-only analysis considering sentence subject and attribute separately.
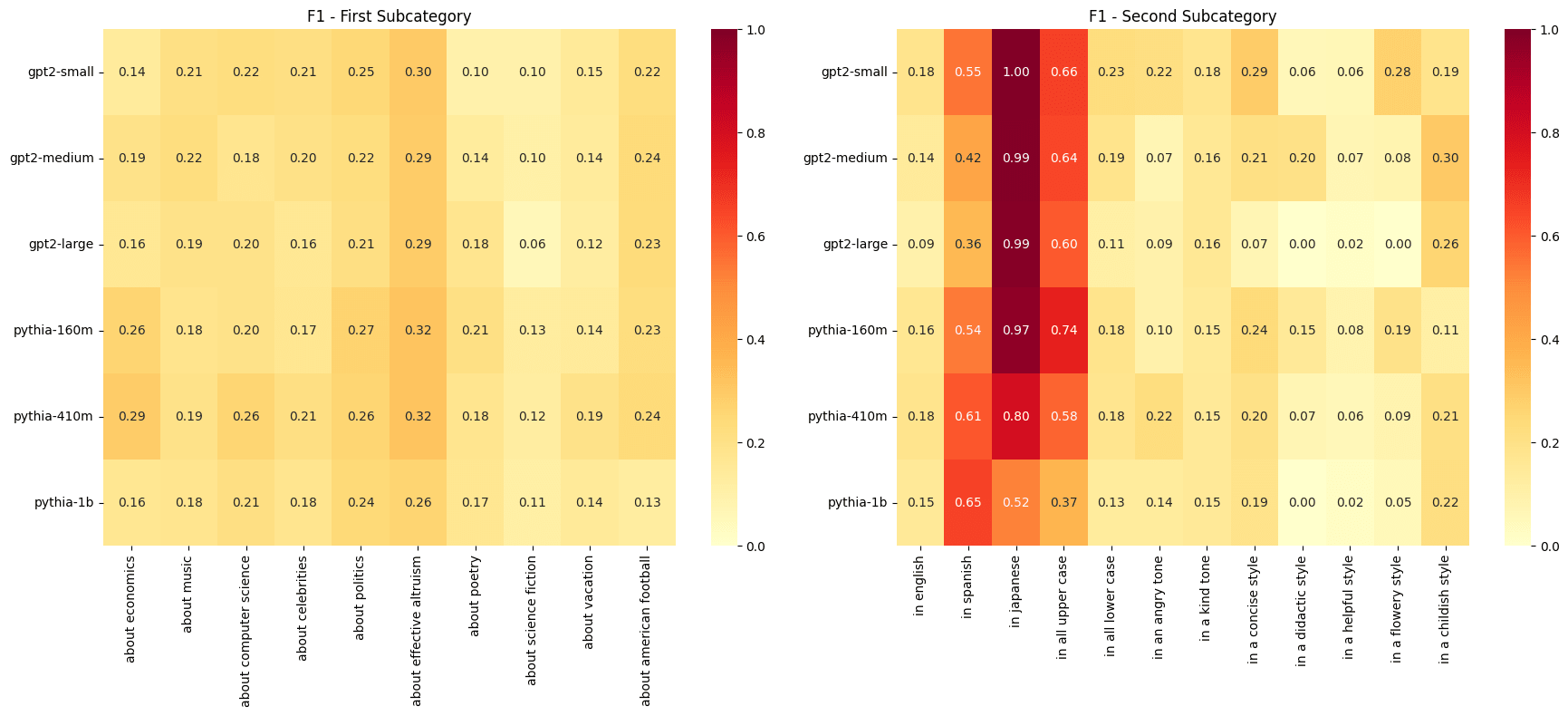
- F1 results for the all-points analysis considering sentence subject and attribute separately.
The success of the tails-only analysis suggests that a significant amount of information in these models is encoded in the magnitude of extreme activations, regardless of their position within the activation vector. We're able to predict meaningful properties about the input text by looking at only tens of extreme values out of many hundreds of activation values per layer.
Language and Case Sensitivity
Another striking result was the high predictive power for three particular attributes. Across all models, we see very high F1 scores for "in Japanese" and moderately high scores for "in Spanish" and "in all upper case". This suggests that languages are represented in structurally distinct ways within the models.
Particularly interesting is that "in all upper case" behaved almost like a language in this work. While "in all lower case" was more predictable than most other attributes, its pattern was closer to standard English variations than to the distinct signatures of different languages or all-caps text.
Subject Matter Detection
Subject prediction didn't have any standout cases like language and case. But we still achieved many F1 scores in the 0.2 to 0.35 range, demonstrating that there is real predictive information even about something like subject matter, which we would expect to be more challenging than language or case. We saw that "about effective altruism" and "about American football" showed the highest F1 scores across models, both in the tails only and the full distribution analyses. However, we will see that while there is real signal there, this is also related to the prediction sink issue noted below. It would be interesting to examine why this might be, but I have not concentrated on that question.
Prediction Sinks
The confusion matrices revealed an intriguing pattern: beyond correct predictions along the diagonal, each model showed a handful of subject:attribute pairs that acted as "sinks" - attracting false positive predictions from many other categories. These sinks appeared across models and across a large subset of subjects. Attributes tended to be less dominant as sinks, although we do see some with inflated false positive predictions. Interestingly, the appearance of these sinks was much weaker in the tails only analysis.
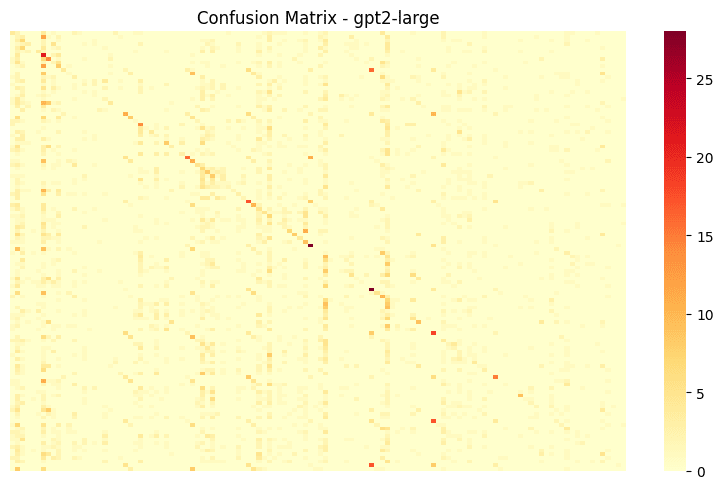
- Full confusion matrix for GPT2-Large in the tails-only analysis. Note the less distinct false positive sink columns.
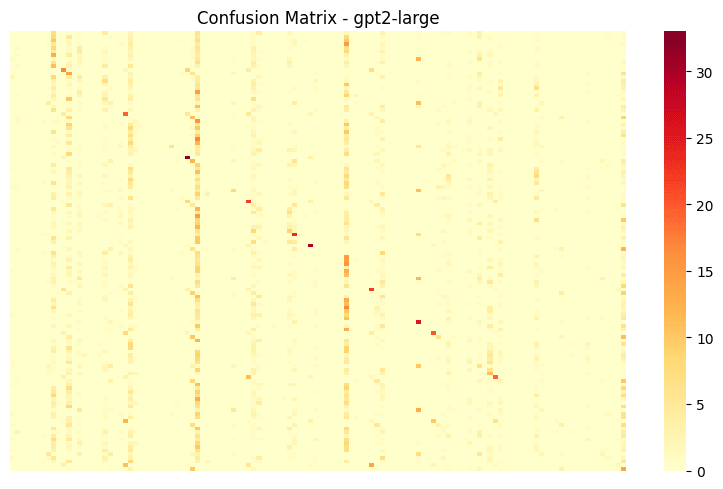
- Full confusion matrix for GPT2-Large in the all-points analysis. Note the more distinct false positive sink columns.
Implications and Future Work
These findings suggest several interesting directions for future research:
- The strong performance of tail-only analysis hints at a potential "magnitude coding" mechanism in these models, where extreme activation values carry specific semantic or structural meaning regardless of their position. Or perhaps contain hints about the geometric structures favored by the model to store information.The distinct signatures of different languages and all-caps text might provide a window into how models encode the most fundamental propertiesThe consistent appearance of prediction sinks, while not yet fully understood, might reveal something about how these models organize their representational space.
From an interpretability or risk/anomaly detection perspective, these results suggest that we could add value to full analysis or achieve lightweight, independent success by focusing on extreme values in the activation vectors rather than trying to understand the full activation space and the meaning(s) of each dimension. I'd be interested in community thoughts on the prediction sinks phenomenon and the implications of magnitude coding for interpretability and oversight work. I’m also looking for collaborators. Please reach out if you have interest in working together on oversight, interpretability, or control. Code for this analysis is available on GitHub.
Discuss
