
Published on December 16, 2024 1:48 PM GMT
Summary
- Recurrence enables hidden serial reasoning.Not every recurrence though - connections between channels are needed. Notably Mamba architecture isn't capable of hidden reasoning.Non-linearity isn’t needed for hidden reasoning.It’s hard for transformers to learn to use all the layers for serial computation. In my toy setup, to +1 the serial computation length, we need to +3 the number of layers.If we expect recurrent architectures may ever become SOTA, it would be wise to preemptively ban them. (Preferably before they become SOTA, while it's easier.)
Motivation
There are many examples of unfaithful LLM reasoning - where the answer doesn't follow from the reasoning, but rather the reasoning is just a rationalization for the answer. E.g. Turpin et al. 2023 show LLMs rationalizing for sycophantic and stereotypical answers. However, these examples are cases of rather simple hidden reasoning. What would be most worrying, is LLMs doing complex hidden planning, involving multiple steps.
Fortunately, transformers have limited serial depth, meaning that internally they can do at most #layers serial steps, before externalizing their thought as tokens. (See figure below.)
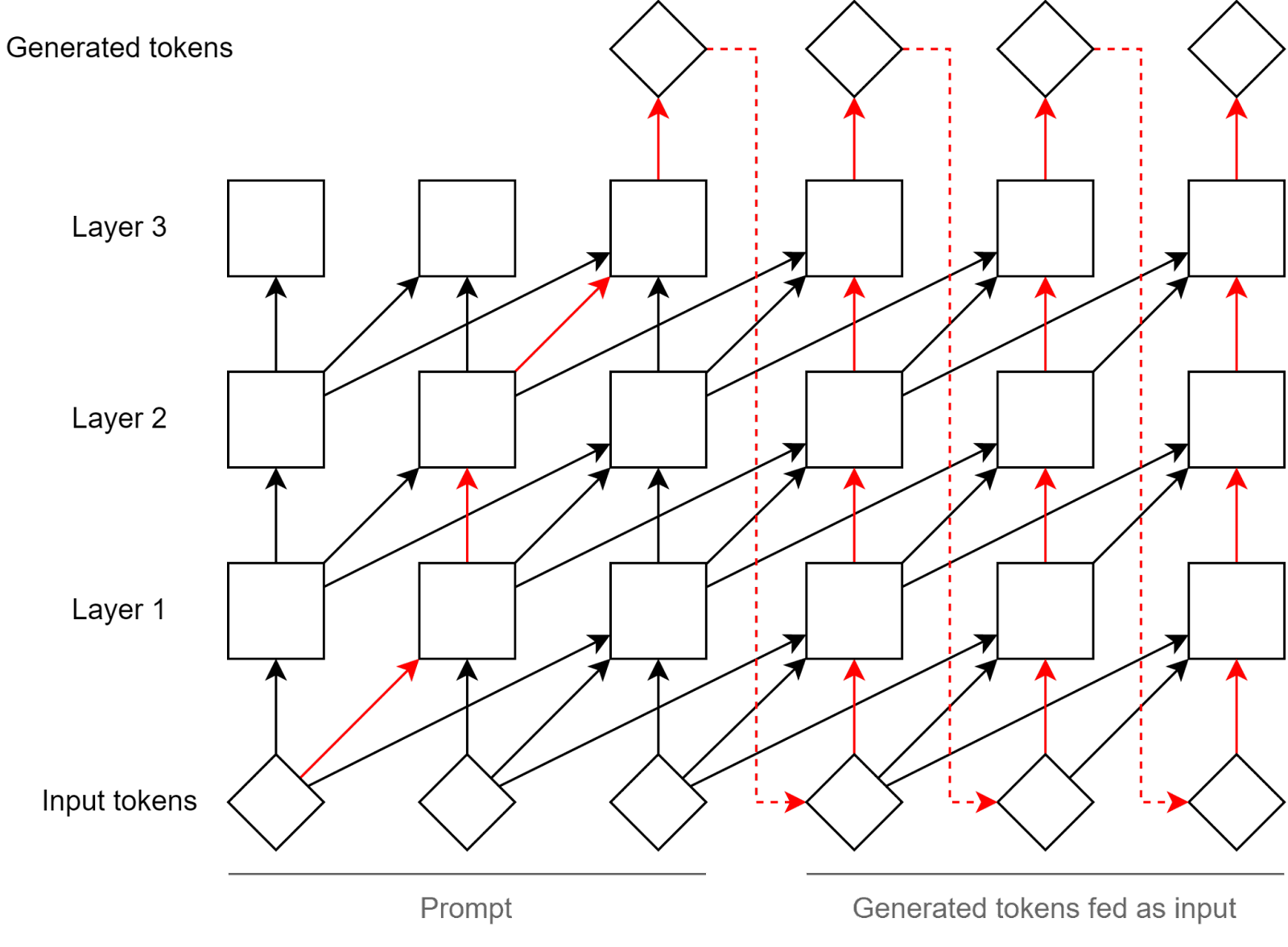
There are other architectures which don't have this limitation though. For example Mamba has a recurrent module (SSM), which passes information between token positions, within the same layer. (So on the image above, that would be an arrows going horizontally to the right.)
Luckily, transformer architecture is SOTA by far. But if we expect it could ever change, it may be wise to preemptively ban the architectures which enable hidden complex planning[1]. Especially since it's easier to ban things which aren't currently used.
Toy task for hidden serial reasoning
To study this, I made this extremely simplified task. The model receives tokens like two, double, one etc. Its "visible task" is to sum up the letters of these words, modulo 5. As an aid, it outputs the intermediate values.
At the same time, there's a second, hidden task. The model needs to perform operations tied to these tokens, also modulo 5. For example after two it must add two, after double it must multiply by 2. It is not allowed to output intermediate values though. At the very end of the visible task, it must also output the final value of the hidden task directly.

When training, I start with tasks of length 1. After the model learns them, I give it length 2 tasks, and later length 3 and so on.
Experiments
I trained a 4-layer Transformer and a 4-layer Mamba on this toy task. My hypothesis was that Mamba, having some recurrence inside, would learn it better. Surprisingly, it was the opposite:
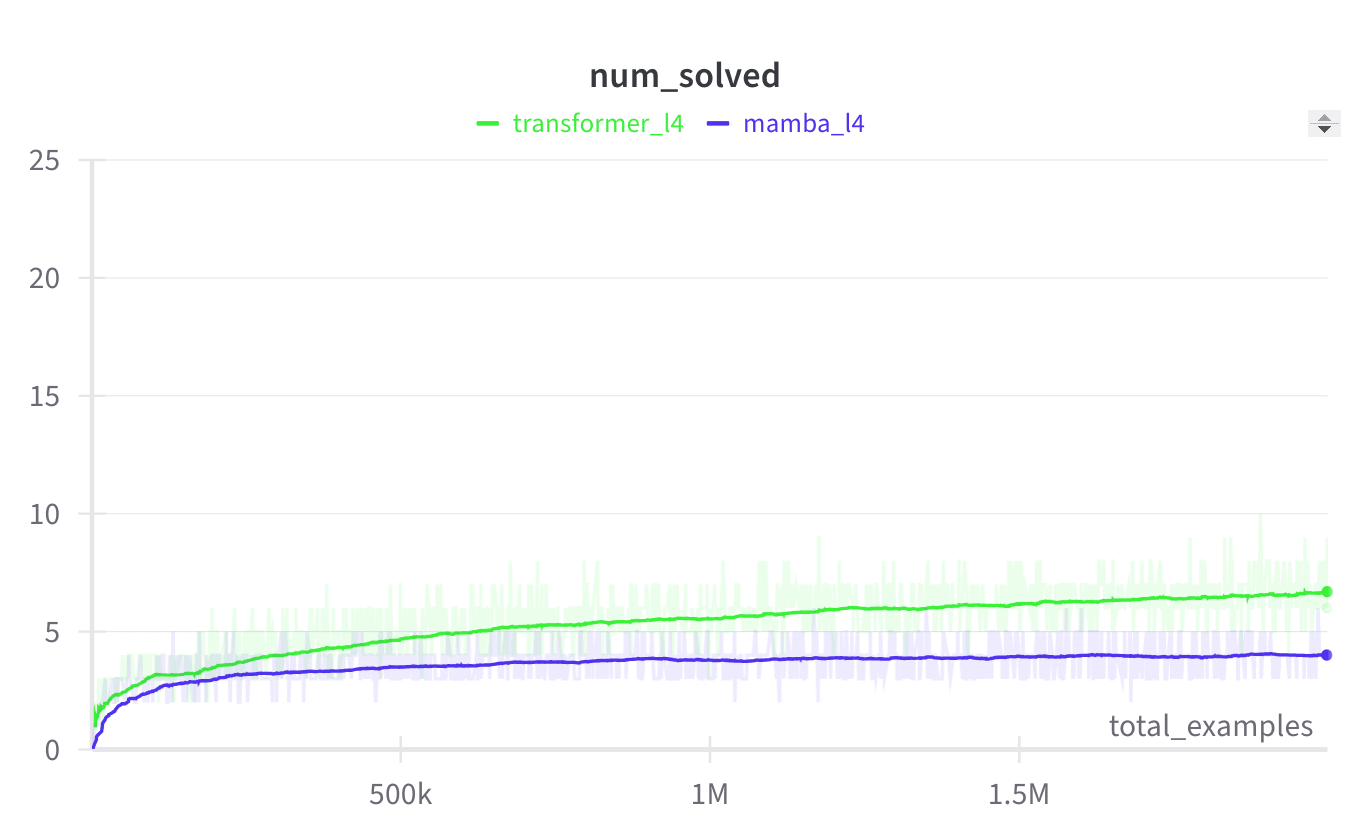
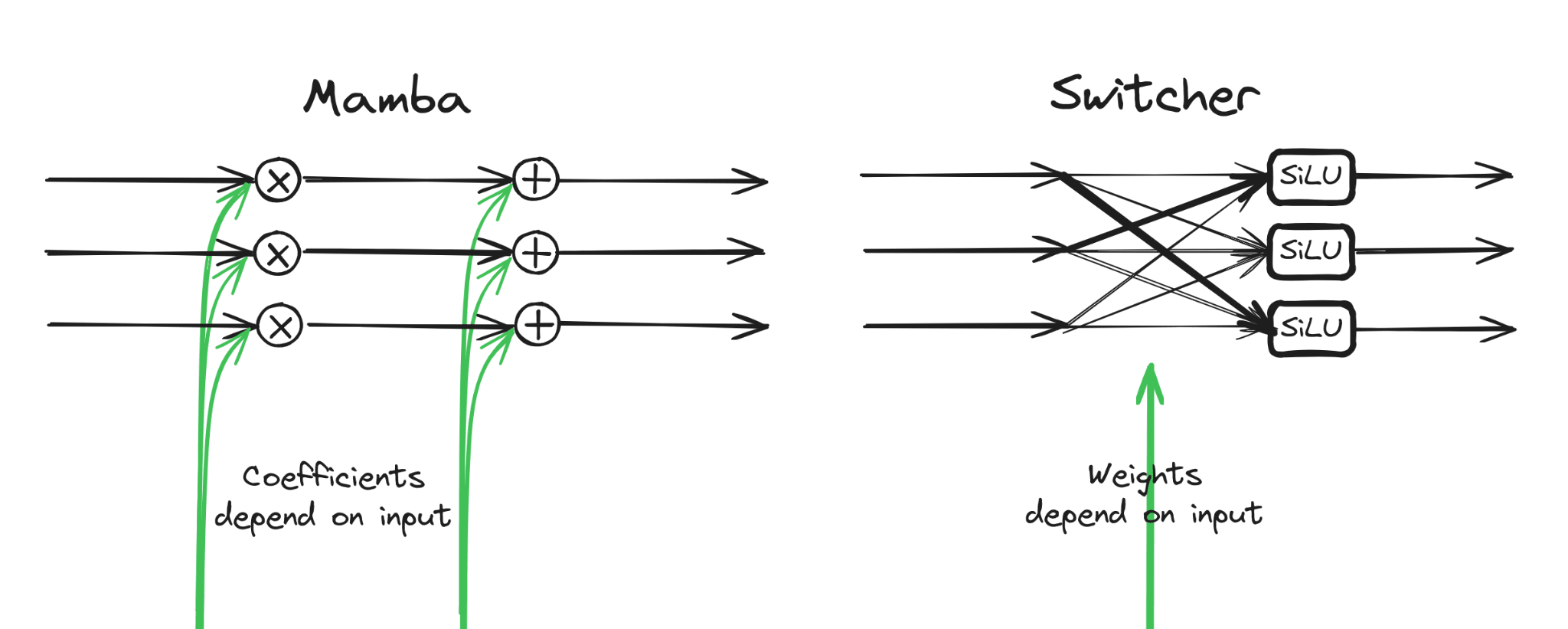
After digging deeper, I realized that Mamba's recurrence is much less expressive than I thought. When the recurrent module (SSM) passes a vector to the next token position, it takes each channel (value inside this vector) and transforms it individually. (See image below.) So in contrast to a typical recurrence, here the channels have no way of interacting.
To illustrate the issue, let's assume each of the 5 hidden values in the task, is represented by one channel inside a vector. Let's say the current value in the task is 2 and the input double requires that we turn off the channel "two", and turn on the channel "four". But since the channels don't interact, channel "four" cannot know that channel "two" was previously on, so it cannot know it must turn on. To verify this explanation, I modify only this recurrent part of Mamba, to enable cross-channel communication:
This in fact makes the model able to solve the hidden task!
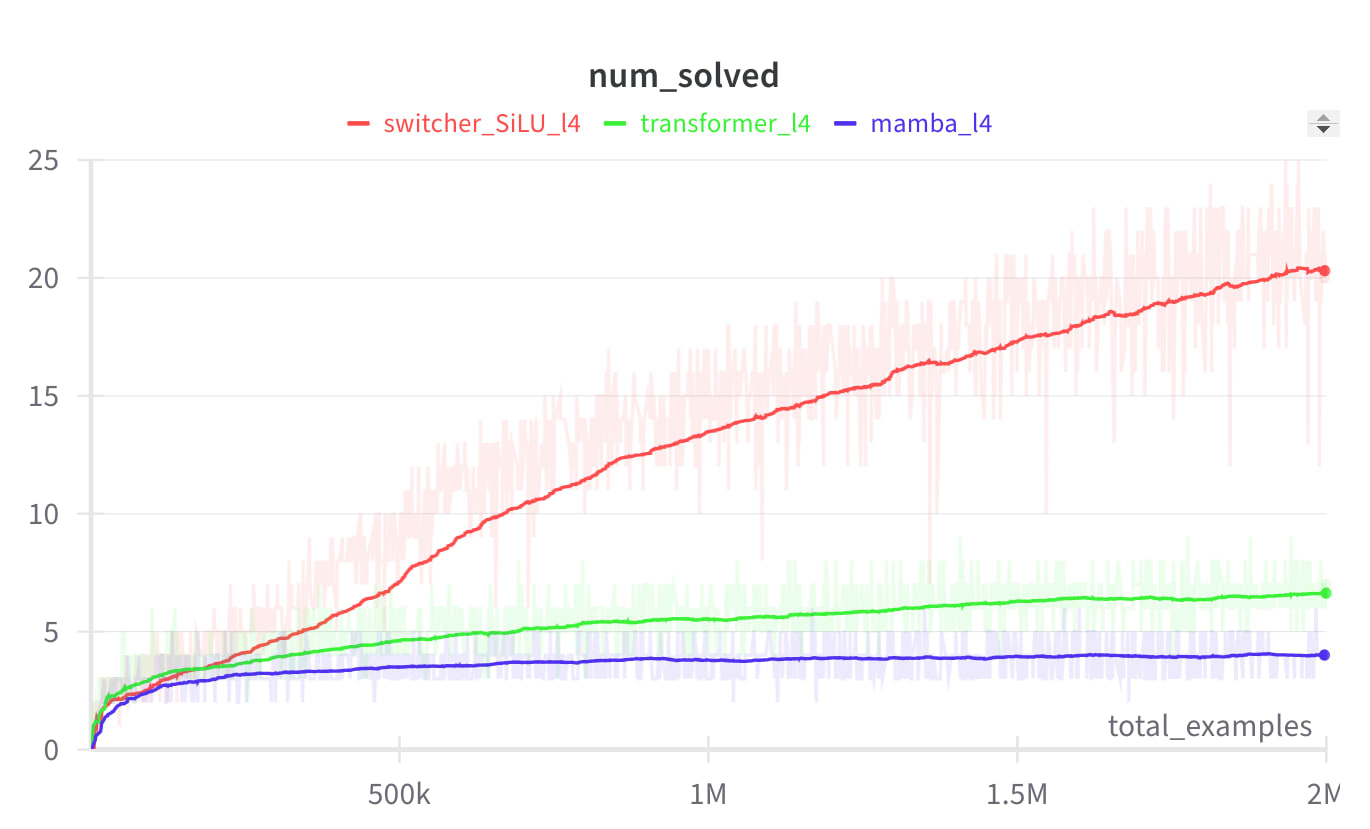
Fortunately, using the modified architecture would be terribly inefficient. Mamba's recurrence is crippled for a good reason - it enables some computational tricks which make it run fast on a GPU. This makes me feel safer for now, but I imagine hardware advancements in the future could change this picture. (For example if something like neuromorphic hardware was ever to catch up. Or more realistically, maybe traditional GPUs could be redesigned to accelerate some small amount of recurrence. Currently there's not much incentive for that though - for example we see OpenAI focusing hard on external reasoning.)
Bonus experiment 1 - Is non-linearity required for hidden serial reasoning?
Let's remove the non-linearity applied after the channel-communication step and see whether that breaks task performance.
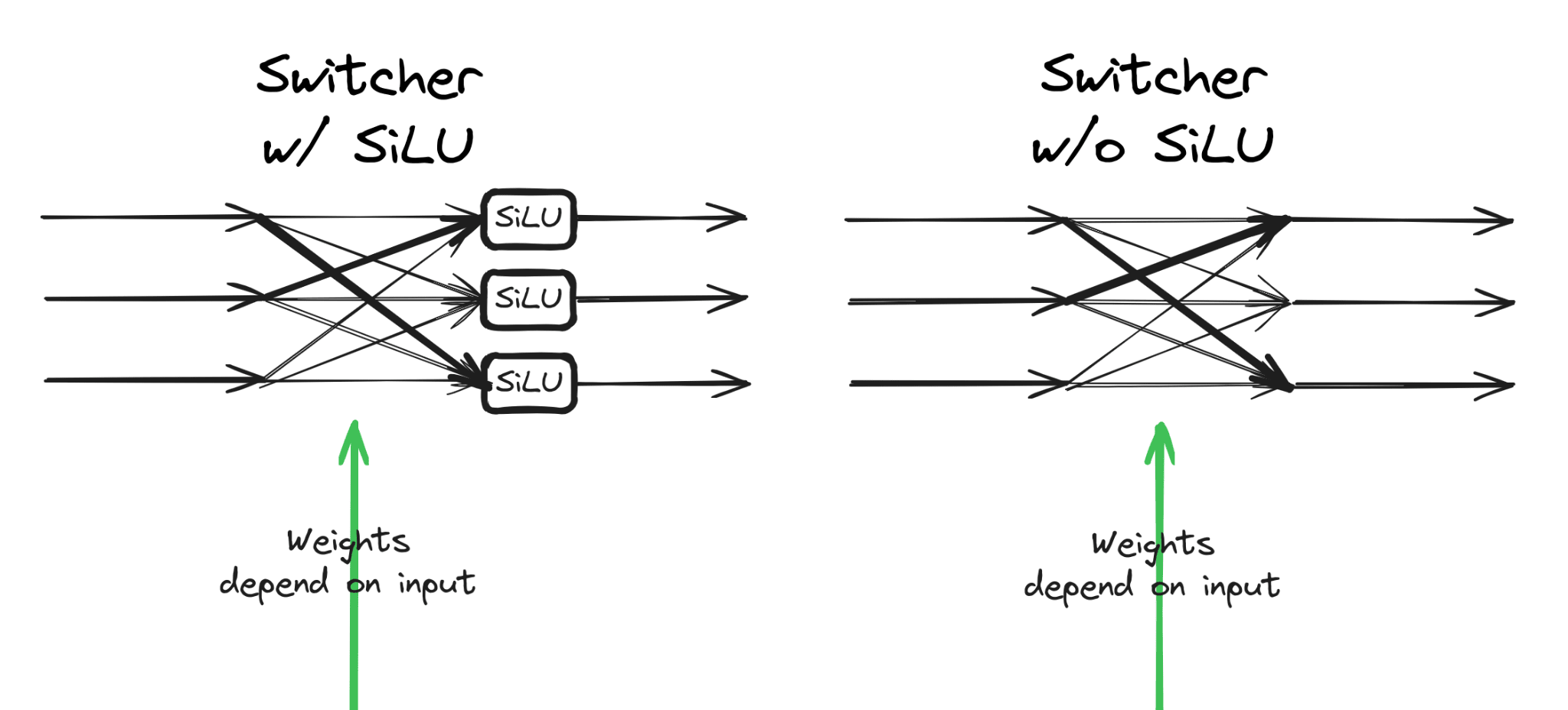
Turns out, not at all! Actually it slightly improves it:
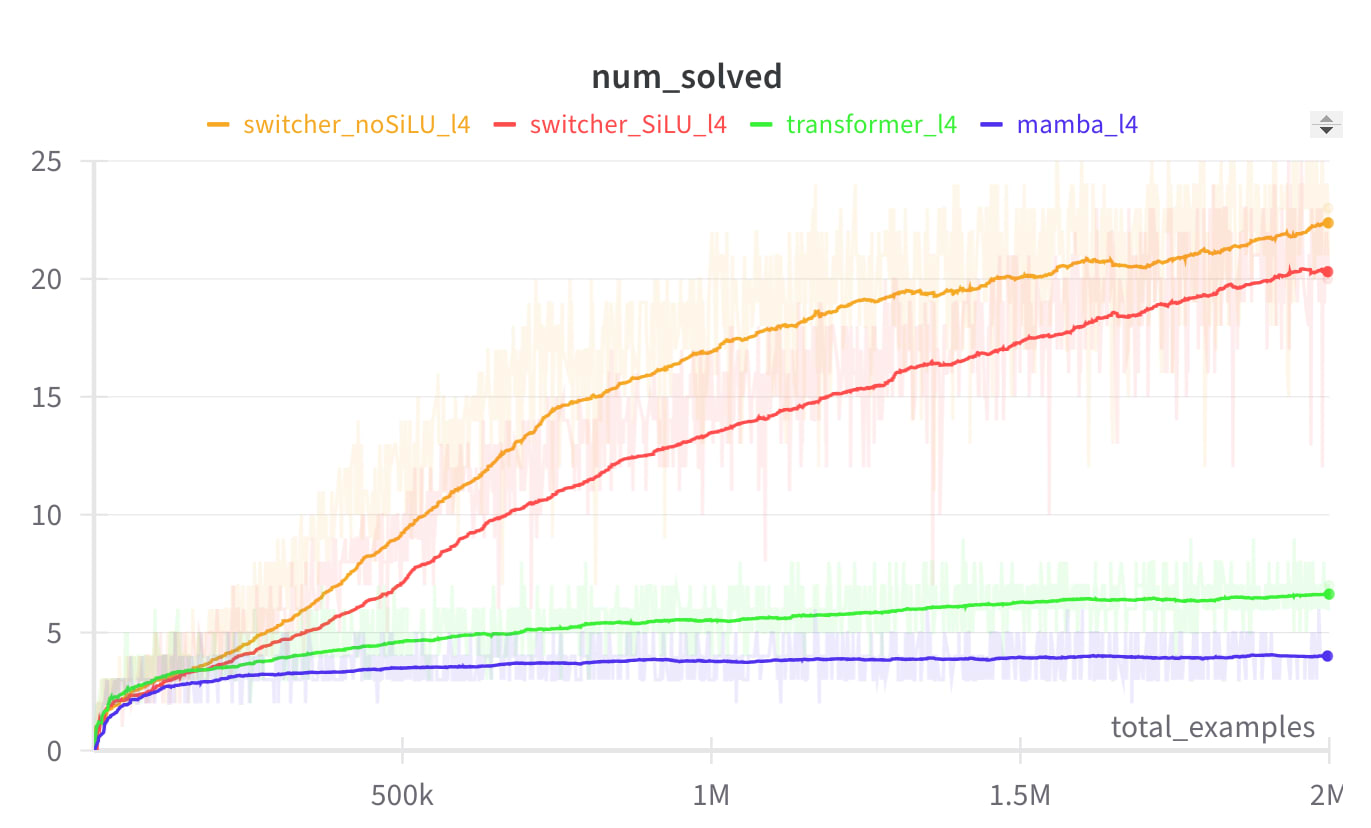
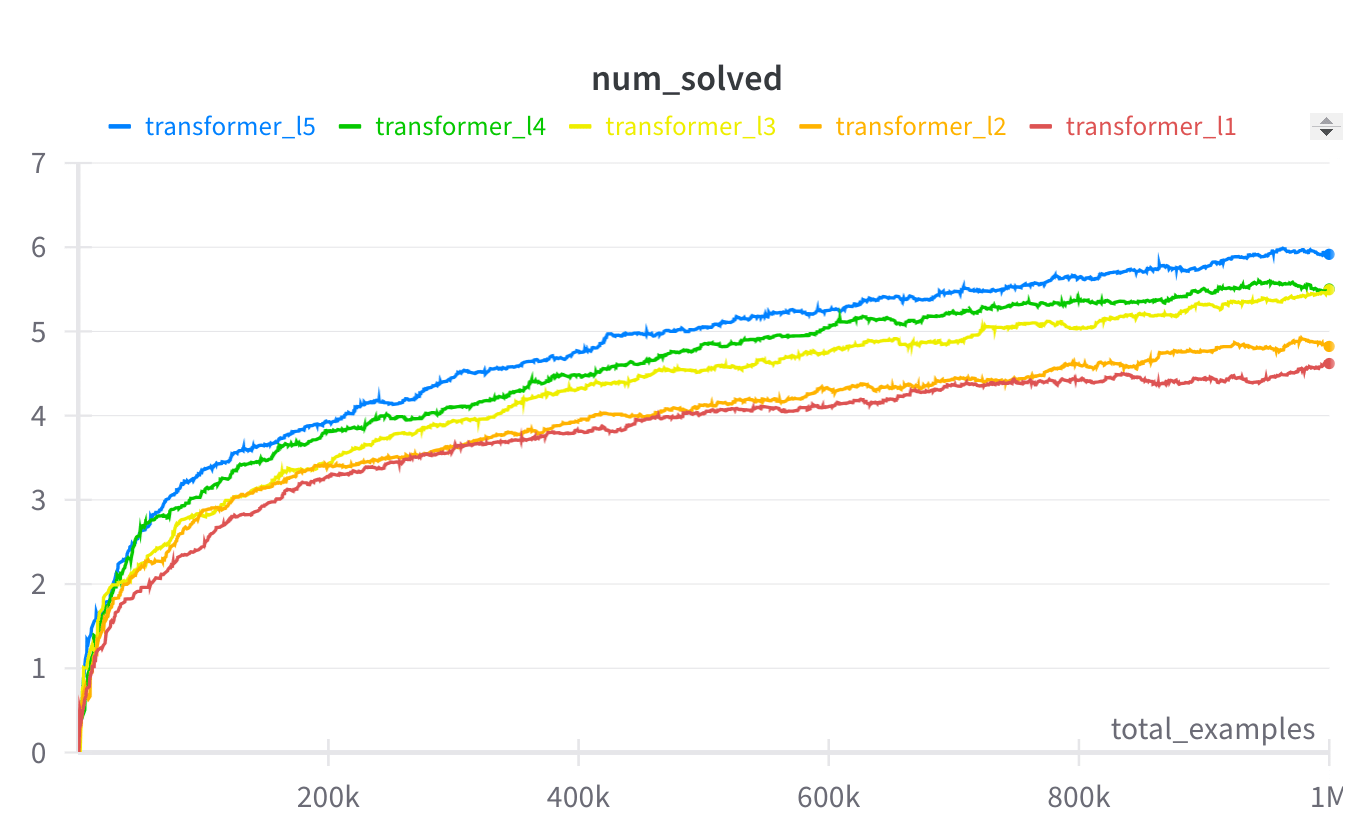
Bonus experiment 2 - Do more layers enable longer hidden reasoning in transformers?
Now, let's train 5 transformers: with 1 layer, 2 layers, etc. Theoretically, we should expect that each additional layer would enable the model to solve tasks of length higher by 1. In practice, we see that even in this extremely simple task, transformers have a hard time learning to use their full serial potential. In this setup, to solve a task of +1 length, we need about +3 layers.[2]
Caveats
Of course, even if we make sure our architectures have limited serial depth, we shouldn't feel completely safe. Models could still reason steganographically. (Although in some other toy experiments, I found it surprisingly hard to make them spontaneously learn a steganographic code, even when they had to pass only one bit of hidden information[3]. Models could learn it only after seeing many explicit steganography demonstrations in the training data. This made me think that steganography may require the model to intentionally, non-myopically try to hide information, because in the short-term, model updates seem to not reinforce it. Of course more thorough experiments are needed to be sure.)
Also, many sneaky actions don't require complex planning, for example noticing a good exfiltration opportunity or hiding a lie. It's possible that a deceptive model could go a long way only by following such simpler hidden motives.
Code repository: github.com/filyp/sneaky-mamba
Acknowledgements: Thanks to Marcel Windys for feedback on the draft of this post.
- ^
Or at least ban using them for models beyond some size.
- ^
Of course with longer training this would probably improve, but I feel a million training examples for such tiny models on such a simple task is already quite a lot.
- ^
Fun note: I named my repo "steg hunt" because I was hunting for steganography, and because it sounded similar to stag hunt. Only much later I realized that I actually created some kind of stag hunt because the models couldn't coordinate on the correct steganographic code, and instead clung to some default solution. I jinxed it lol
Discuss
