


In today’s world, CLIP is one of the most important multimodal foundational models. It combines visual and textual signals into a shared feature space using a simple contrastive learning loss on large-scale image-text pairs. As a retriever, CLIP supports many tasks, including zero-shot classification, detection, segmentation, and image-text retrieval. Also, as a feature extractor, it has become dominant in virtually all cross-modal representation tasks, such as image understanding, video understanding, and text-to-image/video generation. Its strength mainly comes from its ability to connect images with natural language and capture human knowledge as it is trained on large web data with detailed text descriptions, unlike vision encoders. As the large language models (LLMs) are developing rapidly, the boundaries of language comprehension and generation are continually being pushed. LLMs’ strong text skills can help CLIP better handle long, complex captions, a weakness of the original CLIP. LLMs also have broad knowledge of large text datasets, making training more effective. LLMs have strong understanding skills, but their way of generating text hides abilities that make their outputs unclear.
Current developments have extended CLIP to handle other modalities, and its influence in the field is growing. New models like Llama3 have been used to extend CLIP’s caption length and improve its performance by leveraging the open-world knowledge of LLMs. However, incorporating LLMs with CLIP takes work due to the limitations of its text encoder. In multiple experiments, it was found that directly integrating LLMs into CLIP leads to reduced performance. Thus, certain challenges exist to overcome to explore the potential benefits of incorporating LLMs into CLIP.

Tongji University and Microsoft Corporation researchers conducted detailed research and proposed the LLM2CLIP approach for enhancing visual representation learning by integrating large language models (LLMs). This method takes a straightforward step by replacing the original CLIP text encoder and enhances the CLIP visual encoder with extensive knowledge of LLMs. It identifies key obstacles associated with this innovative idea and suggests a cost-effective fine-tuning strategy to overcome them. This method boldly replaces the original CLIP text encoder. It recognizes the challenges of this approach and suggests an affordable way to fine-tune the model to address them.
The LLM2CLIP method effectively improved the CLIP model by integrating large language models (LLMs) like Llama. Initially, LLMs struggled as text encoders for CLIP due to their inability to clearly distinguish image captions. Researchers introduced the caption contrastive fine-tuning technique to address this, greatly improving the LLM’s ability to separate captions. This fine-tuning led to a substantial performance boost, surpassing existing state-of-the-art models. The LLM2CLIP framework combined the improved LLM with the pretrained CLIP visual encoder, creating a powerful cross-modal model. The method used large LLMs but remained computationally efficient with minimal added costs.
The experiments mainly focused on fine-tuning models for better image-text matching using datasets like CC-3M. For LLM2CLIP fine-tuning, three dataset sizes were tested: small (CC-3M), medium (CC-3M and CC-12M), and large (CC-3M, CC-12M, YFCC-15M, and Recaption-1B). Training with augmented captions improved performance, while using an untrained language model for CLIP worsened it. Models trained with LLM2CLIP outperformed standard CLIP and EVA in tasks like image-to-text and text-to-image retrieval, highlighting the advantage of integrating large language models with image-text models.
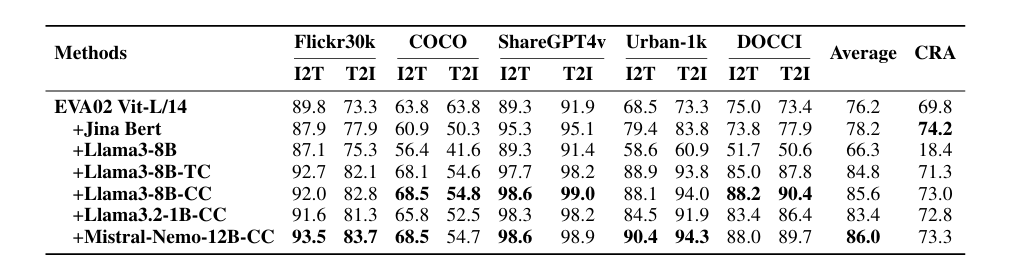
The method directly boosted the performance of the previous SOTA EVA02 model by 16.5% on both long-text and short-text retrieval tasks, transforming a CLIP model trained solely on English data into a state-of-the-art cross-lingual model. After integrating multimodal training with models like Llava 1.5, it performed better than CLIP on almost all benchmarks, showing significant overall improvements in performance.

In conclusion, the proposed method allows LLMs to assist in CLIP training. By adjusting parameters such as data distribution, length, or categories, the LLM can be modified to fix CLIP’s limitations. It allows LLM to act as a more comprehensive teacher for various tasks. In the proposed work, the LLM gradients were frozen during fine-tuning to maintain a large batch size for CLIP training. In future works, the LLM2CLIP can be trained from scratch on datasets like Laion-2Band and Recaption-1B for better results and performance. This work can be used as a baseline for future research in CLIP training and its wide range of applications!
Check out the Paper, Code, and Model on Hugging Face. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Intelligent Document Processing with GenAI in Financial Services and Real Estate Transactions
The post Microsoft Released LLM2CLIP: A New AI Technique in which a LLM Acts as a Teacher for CLIP’s Visual Encoder appeared first on MarkTechPost.
