


LLM的三个层面:原子,大脑和星系
团队发现,SAE特征的概念宇宙在三个层面上都具有有趣的结构: 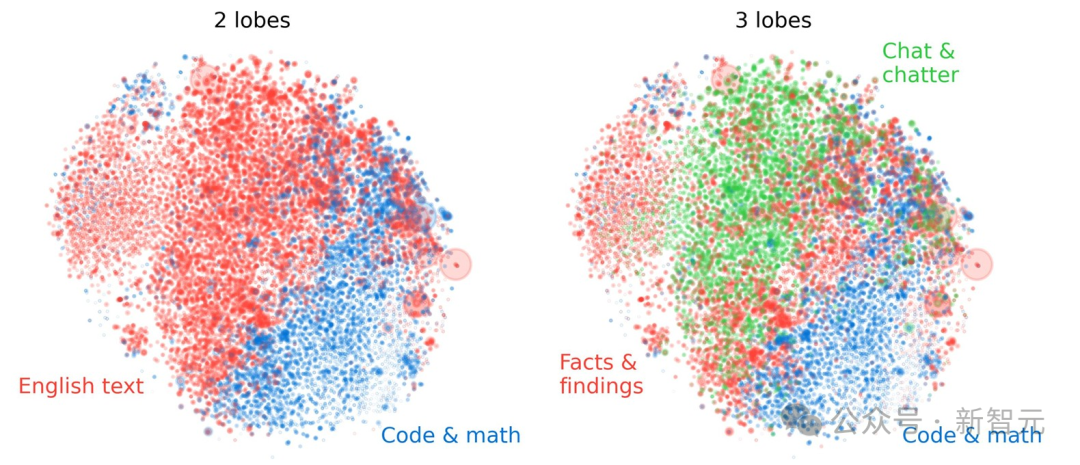
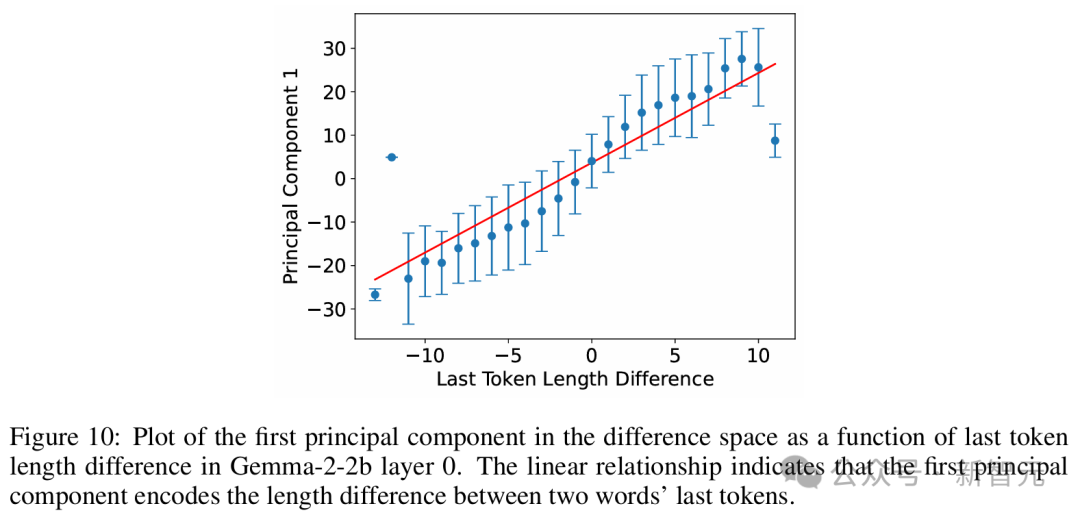
原子级的微观结构,包含面为平行四边形或梯形的「晶体」,这是对经典案例的推广(比如「男人-女人-国王-王后」的关系)。 他们发现,当使用线性判别分析(LDA)高效地投影出诸如词长等全局干扰方向时,这些平行四边形和相关函数向量的质量会显著提升。 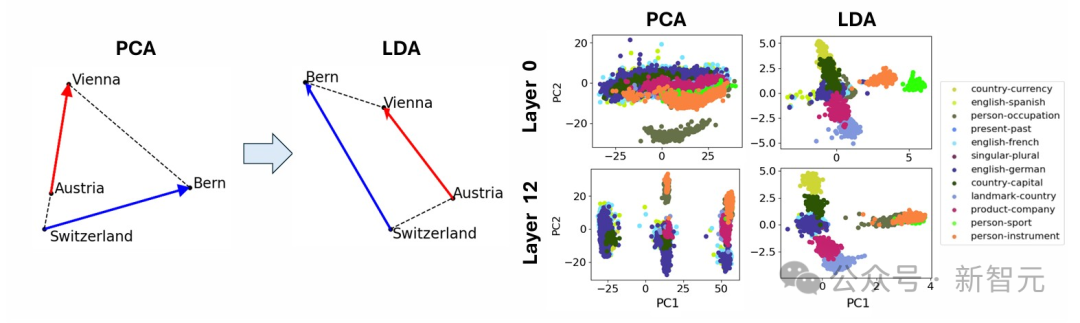
而类似「大脑」的中间尺度结构,则展现出了明显的空间模块化特征,团队将其描述为空间集群和共现集群之间的对齐。 比如,数学和代码特征形成了一个「脑叶」,跟神经功能磁共振图像中观察到的人类大脑功能分区相似。 团队运用多个指标,对这些功能区的空间局部性进行了量化分析,发现在足够粗略的尺度上,共同出现的特征簇在空间上的聚集程度远超过特征几何随机分布情况下的预期值。 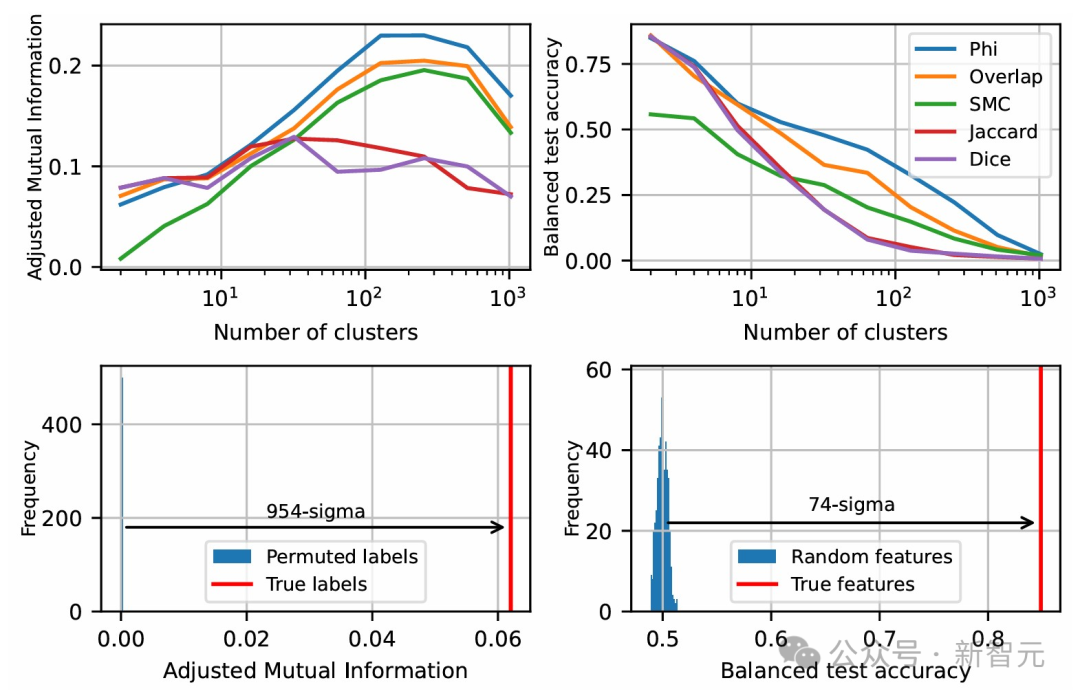
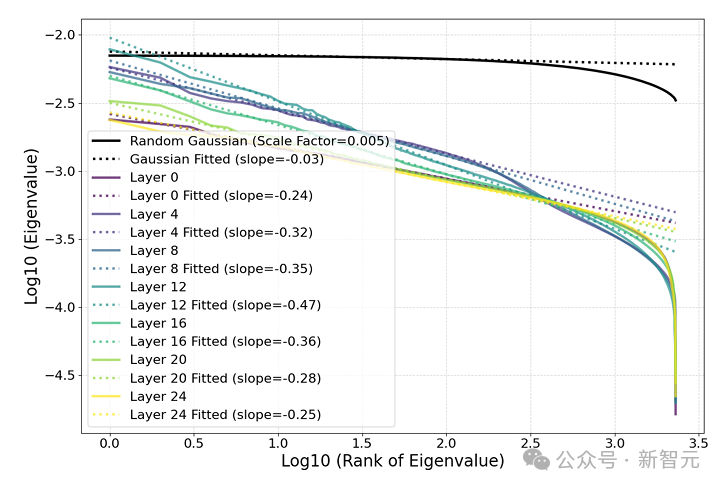
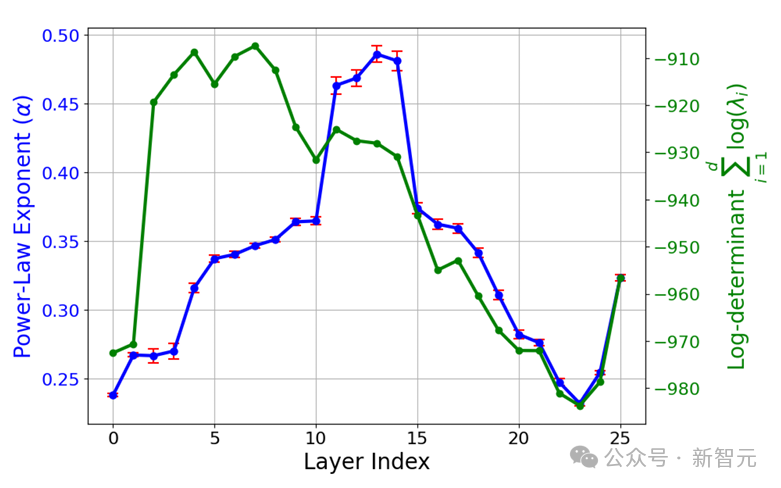
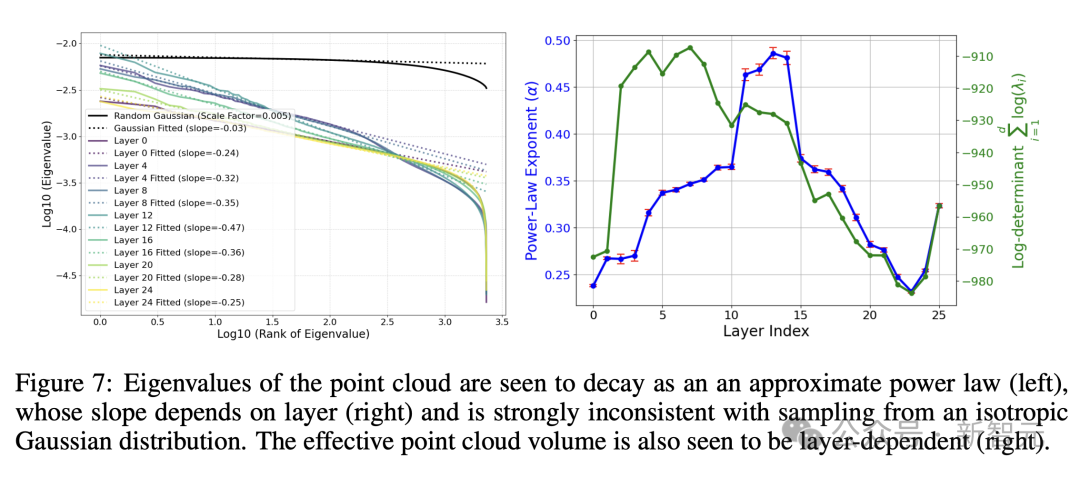
而在「星系」的大尺度结构上,特征点云并非呈各向同性(各个方向性质相同),而是表现出特征值幂律分布,中间层的斜率最抖。 而聚类熵也在中间层周围达到峰值! 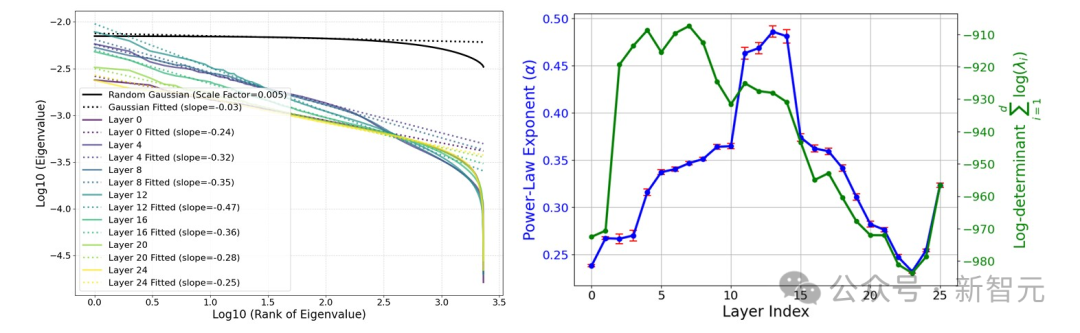
看完这个研究,有网友给出了这样的评价—— 「如果这项研究出自Max Tegmark之外的任何人,我都会觉得他是疯子。但Tegmark是我们这个时代最优秀的科学家之一。当我说意识是一种数学模式、一种物质状态时,我引用的是他。」 
LLM学习概念中,惊人的三层几何结构
LLM学习概念中,惊人的三层几何结构
去年,AI圈在理解LLM如何工作上取得了突破,稀疏自编码器在其激活空间中,发现了大量可以解释为概念的点(「特征」)。 稀疏自编码器作为在无监督情况下发现可解释语言模型特征的方法,受到了很多关注,而检查SAE特征结构的工作则较少。 这类SAE点云最近已经公开,MIT团队认为,是时候研究它们在不同尺度上的结构了。
「原子」尺度:晶体结构
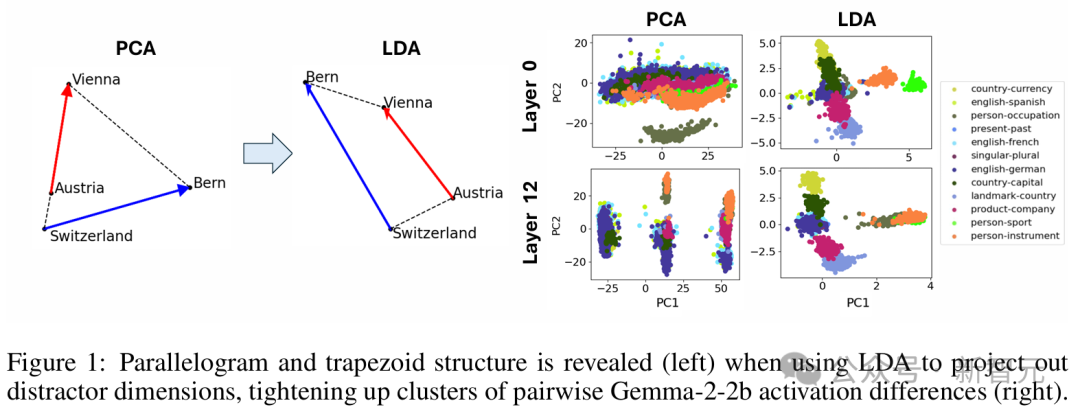
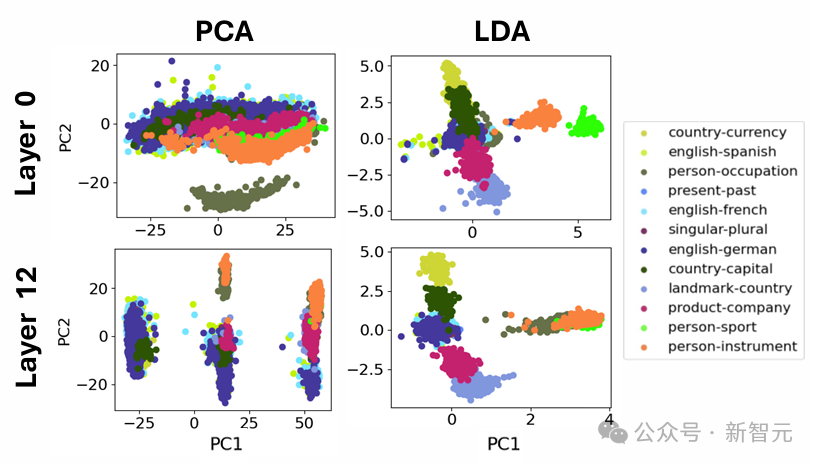
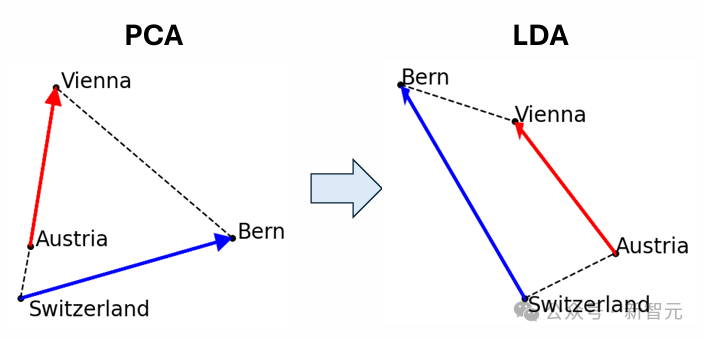
「大脑」尺度:中等尺度的模块结构
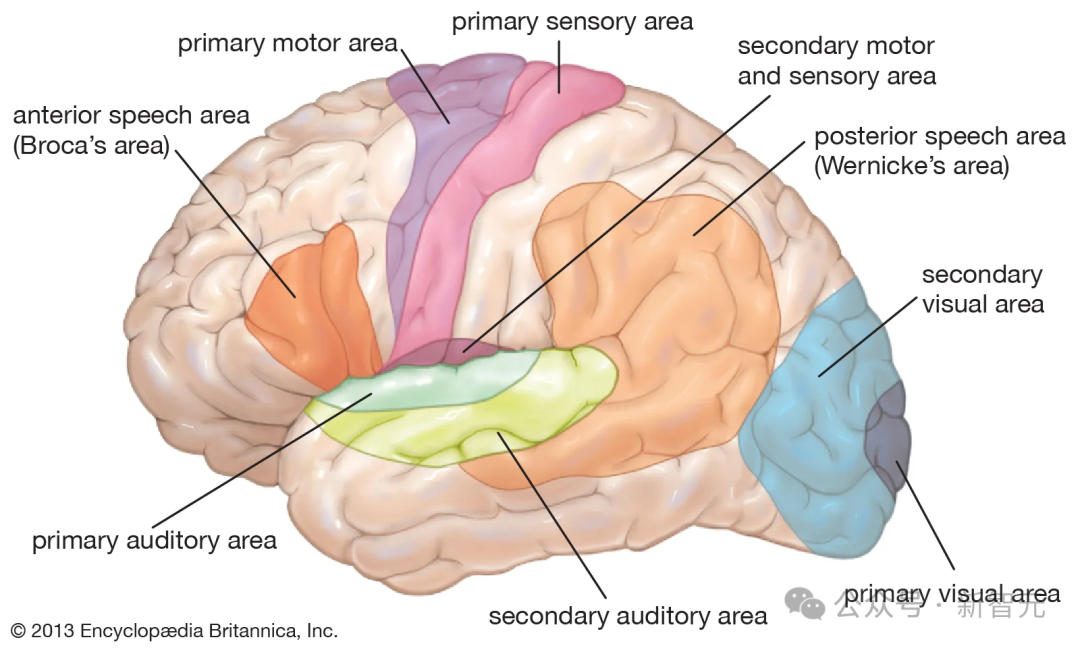


在SAE点云中识别出的特征倾向于在文档中一起激活,同时也在几何上共同定位于功能「脑叶」中,左侧的2脑叶划分将点云大致分为两部分,分别在代码/数学文档和英文文档上激活。右侧的3脑叶划分主要将英文脑叶细分为一个包含简短消息和对话的部分,以及一个主要包含长篇科学论文的部分
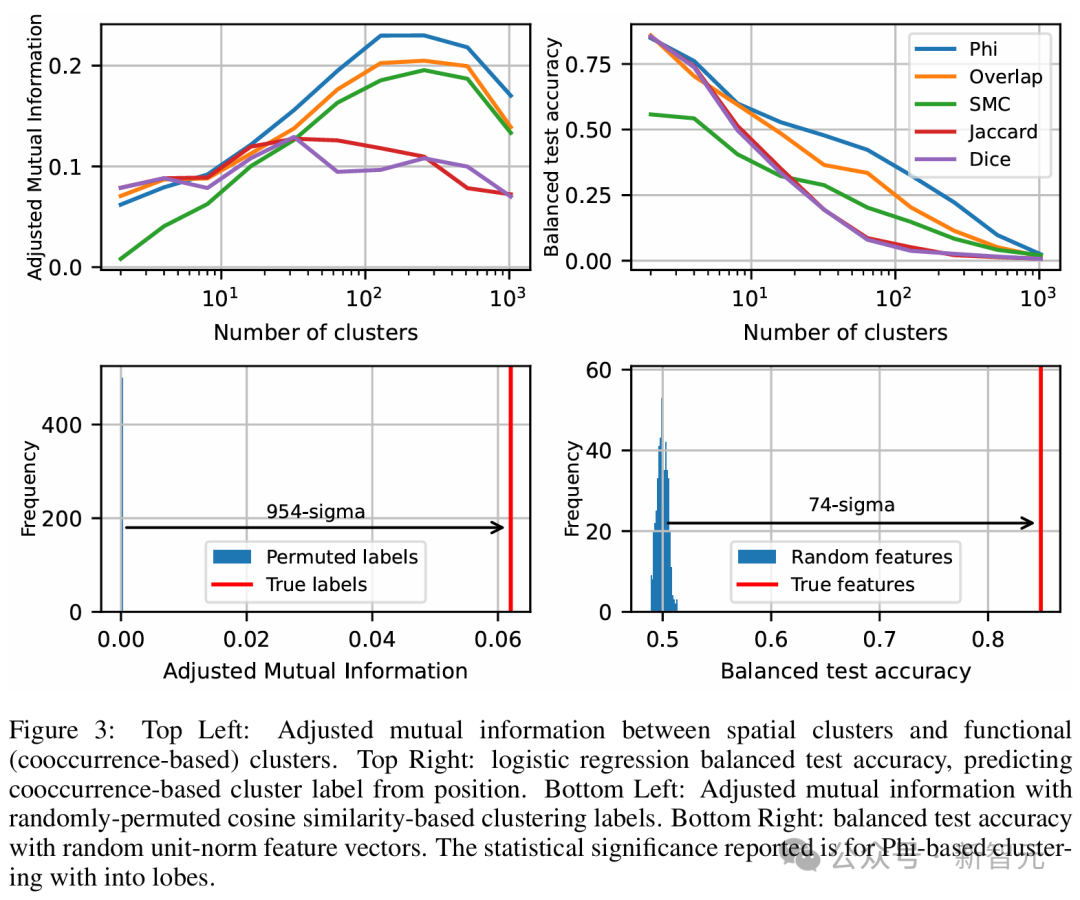
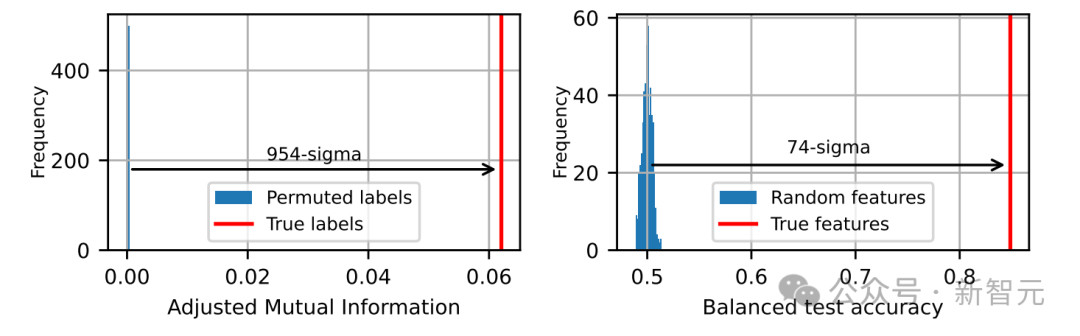
左上:空间聚类与功能聚类之间的调整互信息。右上:逻辑回归的平衡测试准确率,用位置预测基于共现的聚类标签。左下:随机置换余弦相似度聚类标签后的调整互信息。右下:随机单位范数特征向量的平衡测试准确率。报告的统计显著性基于Phi系数的脑叶聚类

每个脑叶都具有最高比例的激活特征上下文分数。脑叶2通常在代码和数学文档上不成比例地被激活,脑叶0在包含文本(聊天记录、会议记录)的文档上激活更多,脑叶1在科学论文上激活更多

「星系」尺度:「大规模」点云结构

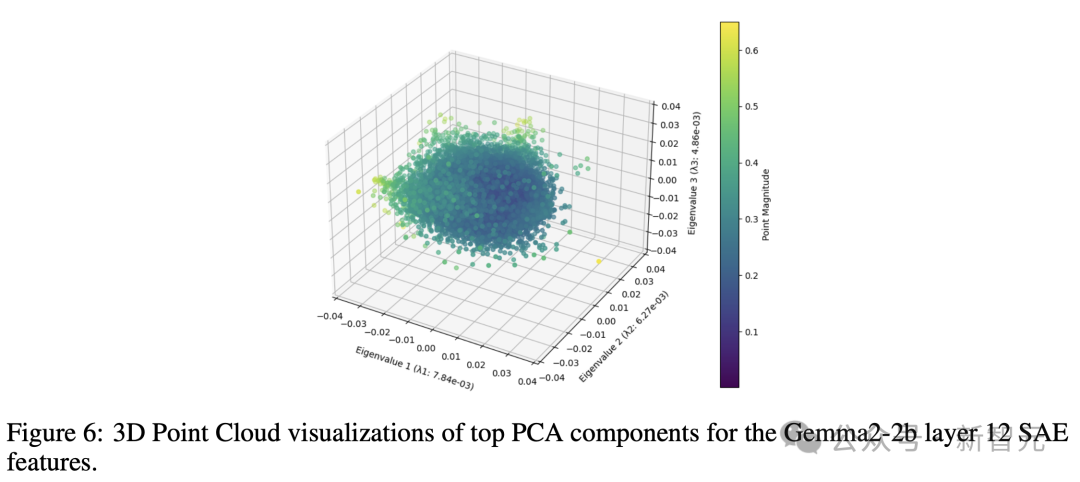
形状分析
从多元高斯分布中抽取的N个随机向量的协方差矩阵遵循Wishart分布
聚类分析
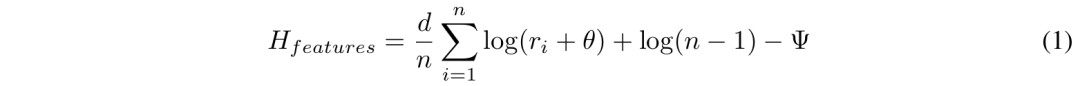
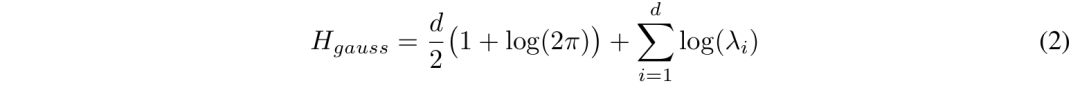
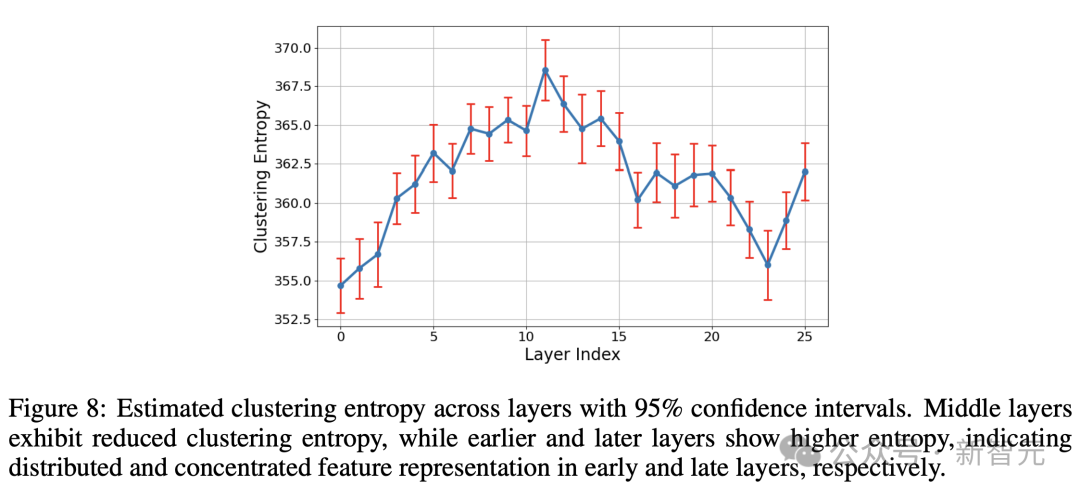
破解LLM运作机制黑箱,人类再近一步
总而言之,MIT团队这项最新研究中,揭示了SAE点云概念空间具有三层有趣的结构: 原子尺度的晶体结构;大脑尺度的模块结构;星系尺度的点云结构。 正如网友所言,亲眼目睹了人类硅基孩子在我面前成长,既令人敬畏又令人恐惧。 
Max Tegmark出品,必属精品。 此前就有人发现,仅在下一个token预测上训练的序列模型中,存在线性表征的类似证据。 23年2月,哈佛、MIT的研究人员发表了一项新研究Othello-GPT,在简单的棋盘游戏中验证了内部表征的有效性。 在没有任何奥赛罗规则先验知识的情况下,研究人员发现模型能够以非常高的准确率预测出合法的移动操作,捕捉棋盘的状态。他们认为语言模型的内部确实建立了一个世界模型,而不只是单纯的记忆或是统计,不过其能力来源还不清楚。 吴恩达对该研究表示了高度认可。 
受此启发,Max Tegmark团队发现,Llama-2-70B竟然能够描绘出研究人员真实世界的文字地图,还能预测每个地方真实的纬度和经度;而在时间表征上,模型成功预测了名人的死亡年份、歌曲电影书籍的发布日期和新闻的出版日期。 总之,这项研究在LLM中发现了「经度神经元」,在学界引起了巨大反响。 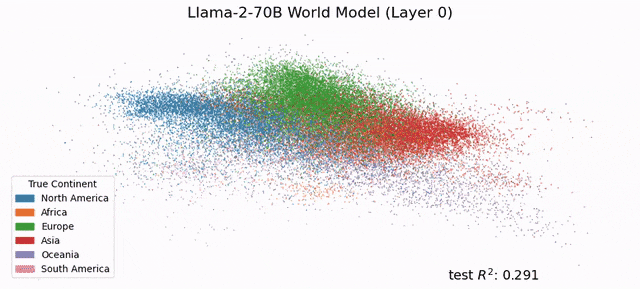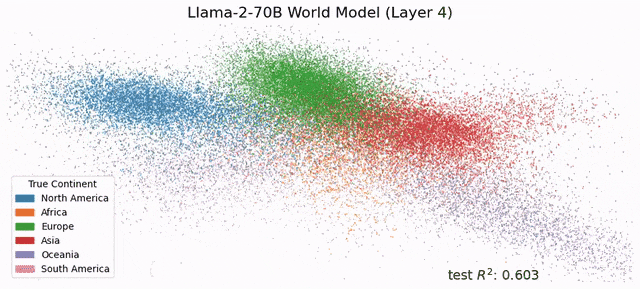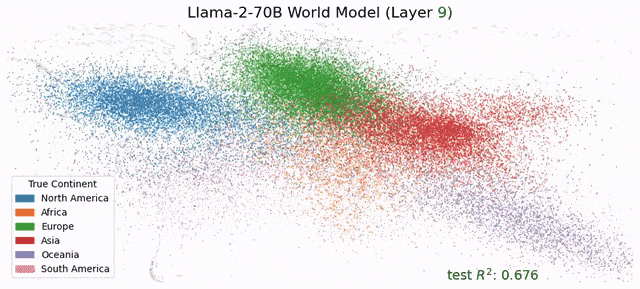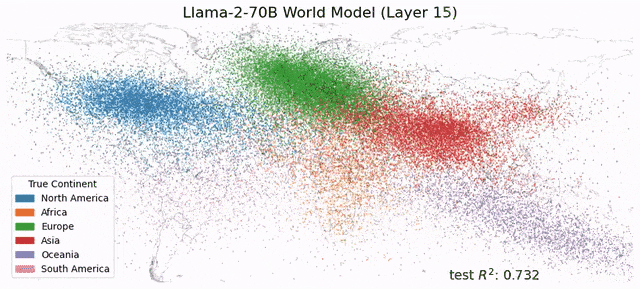
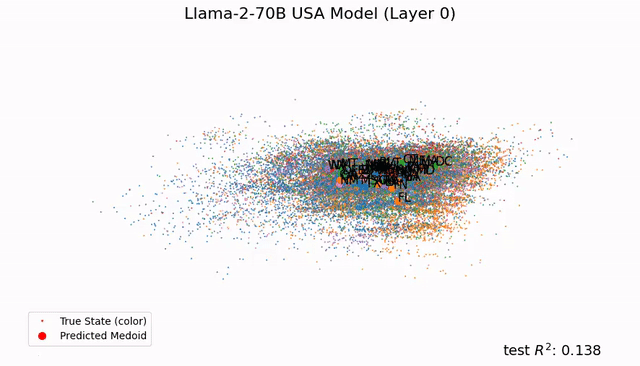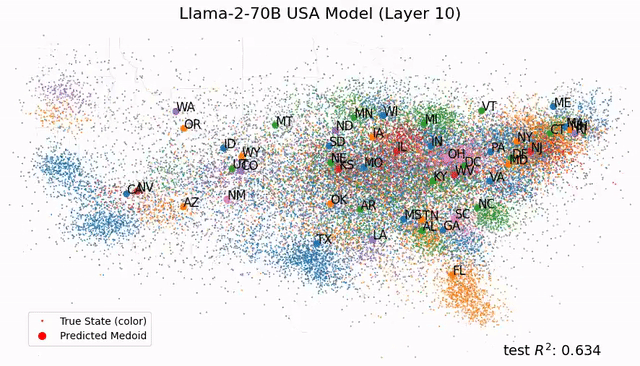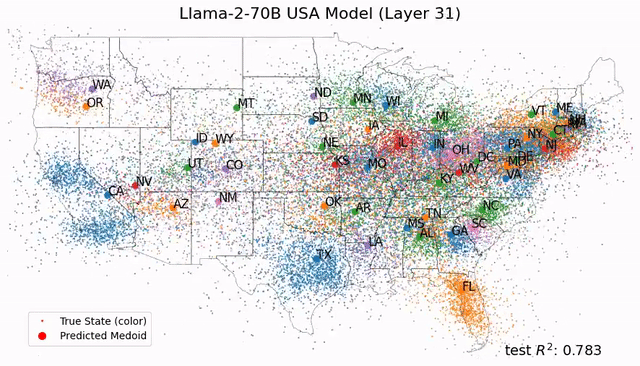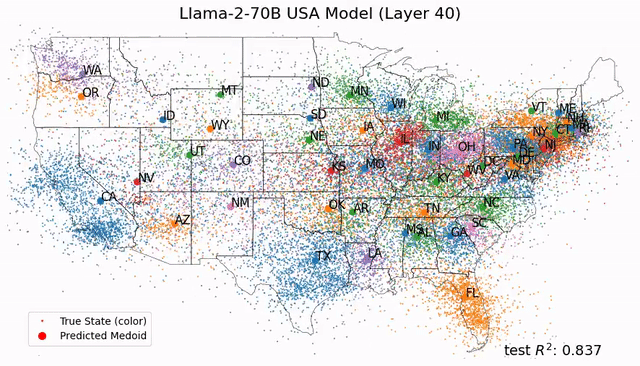
如今,Tegmark团队又再进一步,帮我们从更微观的角度剖析LLM的大脑。人类离解释LLM运作机制的黑箱,又近了一步。 参考资料: https://arxiv.org/abs/2410.19750



