
今年 5 月,OpenAI 发布了多模态大模型 GPT-4o,其能够从文本、音频和图像等多方面感知并理解输入信息,就像拥有了一整套感官。
今天,在 CNCC2024 大会上,智谱也推出了他们在多模态领域的最新成果——端到端语音模型 GLM-4-Voice,让人和机器的交流能够以自然聊天的状态进行。
据介绍,GLM-4-Voice 能够直接理解和生成中英文语音,进行实时语音对话,在情绪感知、情感共鸣、情绪表达、多语言、多方言等方面实现突破,且延时更低,可随时打断。
整体而言,GLM-4-Voice 具备以下优势和特点:
情感表达和情感共鸣:模拟不同的情感和语调,如高兴、悲伤、生气、害怕等情绪,用合适的情绪语气进行回复。传统 TTS 通常在情感表达上比较僵硬,声音缺少起伏和细腻的变化。
调节语速:在同一轮对话中,可以要求 TA 快点说 or 慢点说。
随时打断,灵活输入指令:根据实时的用户指令,调整语音输出的内容、风格和情感,支持更灵活的对话互动。例如,你可以随时打断 TA,让 TA 输出新的内容,更加符合日常对话情境。
多语言、多方言支持:目前 GLM-4-Voice 尤其擅长北京话、重庆话和粤语。
结合视频通话,能看也能说:即将上线视频通话功能,打造真正能看又能说的语音助理。
同时,GLM-4-Voice 发布即开源,这也是智谱首个开源的端到端多模态模型。
代码仓库:
https://github.com/THUDM/GLM-4-Voice
与传统的 ASR + LLM + TTS 的级联方案相比,端到端模型以音频 token 的形式直接建模语音,在一个模型里面同时完成语音的理解和生成,避免了级联方案“语音转文字再转语音” 的中间过程中带来的信息损失,也解锁了更高的能力上限。
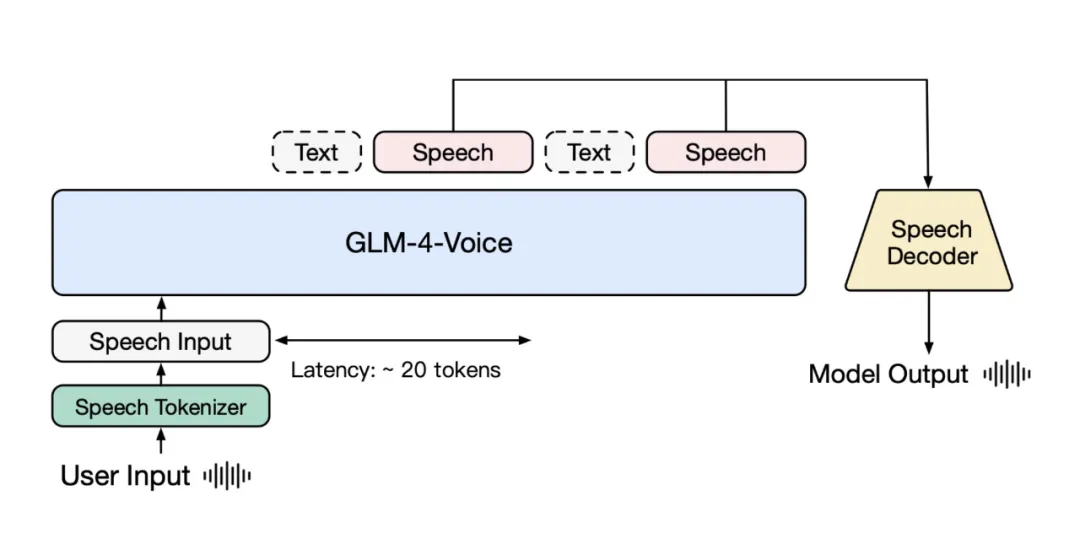
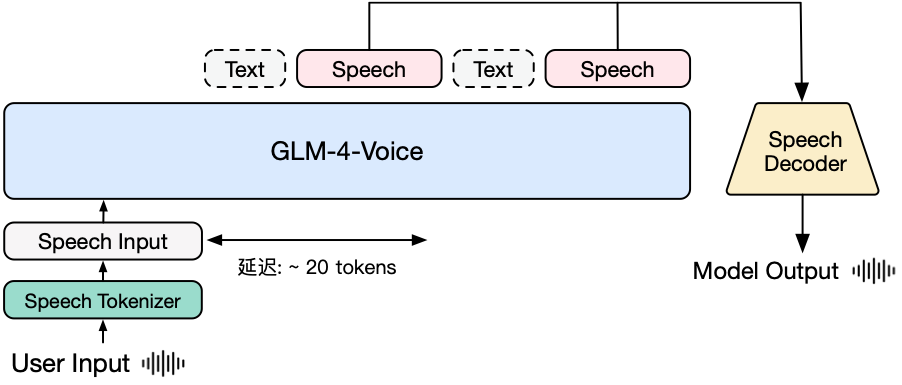
图|GLM-4-Voice 模型架构图
GLM-4-Voice 由三个部分组成:
GLM-4-Voice-Tokenizer: 通过在 Whisper 的 Encoder 部分增加 Vector Quantization 训练,通过在 ASR 数据上有监督训练的方式得到,将连续的语音输入转化为离散的 token,每秒音频转化为 12.5 个离散 token。
GLM-4-Voice-9B: 在 GLM-4-9B 的基础上进行语音模态的预训练和对齐,从而能够理解和生成离散化的语音。
GLM-4-Voice-Decoder: 基于 CosyVoice 的 Flow Matching 模型结构训练的支持流式推理的语音解码器,将离散化的语音 token 转化为连续的语音输出。最少只需要 10 个音频 token 即可开始生成,降低端到端对话延迟。
GLM-4-Voice 以离散 token 的方式表示音频,实现了音频的输入和输出的端到端建模。具体来说,智谱团队在大规模基于语音数据集上识别(ASR)模型以有监督的方式训练语了音频 Tokenizer,可做到能够在单码表 12.5Hz(12.5 个音频 token)单码表的超低码率下对人声中的准确保留语义和信息,并包含语速,情感的准确建模等副语言信息。
语音合成方面,他们采用 Flow Matching 模型流式从音频 token 合成音频,最低只需要 10 个 token 合成语音,最大限度降低对话延迟。
预训练方面,为了攻克模型在语音模态下的智商和合成表现力两个难关,他们将 Speech2Speech 任务解耦合为 Speech2Text(根据用户音频做出文本回复) 和 Text2Speech(根据文本回复和用户语音合成回复语音)两个任务,并设计两种预训练目标适配这两种任务形式:
Speech2Text:从文本数据中,随机选取文本句子转换为音频 token
Text2Speech:从音频数据中,随机选取音频句子加入文本 transcription
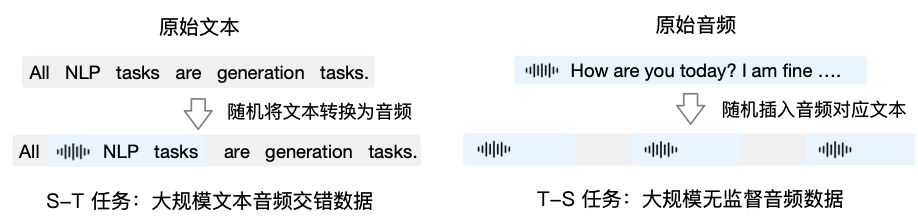
图|GLM-4-Voice 预训练数据构造
GLM-4-Voice 在 GLM-4-9B 的基座模型基础之上,经过了数百万小时音频和数千亿 token 的音频文本交错数据预训练,拥有很强的音频理解和建模能力。为了支持高质量的语音对话,他们设计了一套流式思考架构:输入用户语音,GLM-4-Voice 可以流式交替输出文本和语音两个模态的内容,其中语音模态以文本作为参照保证回复内容的高质量,并根据用户的语音指令变化做出相应的声音变化,在保证智商的情况下仍然具有端到端建模 Speech2Speech 的能力,同时保证低延迟性(最低只需要输出 20 个 token 便可以合成语音)。
图|GLM-4-Voice 模型架构图
除了同步开源,GLM-4-Voice 也即刻上线清言 app,这让清言成为国内首个具有端到端高级语音(超拟人语音)能力的大模型产品。
TA 不仅可以说出快语速的绕口令、正念冥想时的轻柔语音,还可以在自我介绍时表现出如人类般的喜怒哀乐,以及讲鬼故事、说相声、角色扮演等。TA 可以化身为一个如真人般的对话伙伴,能听懂你的情绪、并且像人一样做出回应。
人和机器的交流,应该以自然聊天的状态进行。从解决文本、到视觉、再到语音,GLM-4-Voice 的出现是智谱在迈向 AGI 的道路上迈出的最新一步。
