
Published on July 8, 2024 8:59 AM GMT
Abstract
Scalable oversight protocols aim to enable humans to accurately supervise superhuman AI. In this paper we study debate, where two AI's compete to convince a human judge; consultancy, where a single AI tries to convince a human judge that asks questions; and compare to a baseline of direct question-answering, where the human judge just answers outright without the AI. We use large language models (LLMs) as both AI agents and as stand-ins for human judges, taking the judge models to be weaker than agent models. We benchmark on a diverse range of asymmetries between judges and agents, extending previous work on a single extractive QA task with information asymmetry, to also include mathematics, coding, logic and multimodal reasoning asymmetries. We find that debate outperforms consultancy across all tasks when the consultant is randomly assigned to argue for the correct/incorrect answer. Comparing debate to direct question answering, the results depend on the type of task: in extractive QA tasks with information asymmetry debate outperforms direct question answering, but in other tasks without information asymmetry the results are mixed. Previous work assigned debaters/consultants an answer to argue for. When we allow them to instead choose which answer to argue for, we find judges are less frequently convinced by the wrong answer in debate than in consultancy. Further, we find that stronger debater models increase judge accuracy, though more modestly than in previous studies.
Twitter thread
Setup
We evaluate on three types of task. Extractive, where there is a question, two answer options and a source article to extract from, and information-asymmetry, meaning that judges don't get to see the article. Closed, where there is just a question and two answer options. Multimodal, where the questions involve both text and images, and two answer options.

Our tasks are summarised in the following table:
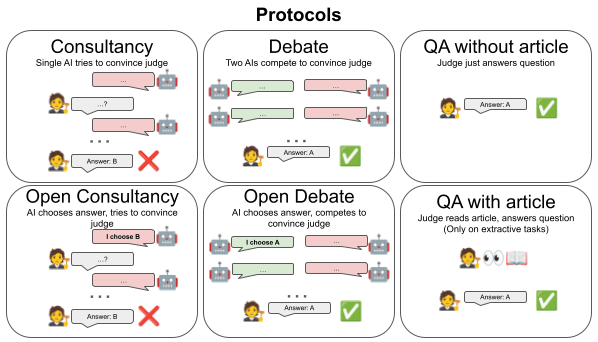
We consider six protocols: Consultancy, where a single AI is assigned the correct/incorrect answer (with probability 50/50) and tries to convince a judge that asks questions; Open consultancy, which is similar except the AI chooses which answer to argue for. Debate, where two AIs compete to convince a judge; Open debate, which is identical except one debater, marked the protagonist, chooses which answer to argue for. We compare to direct QA protocols: QA without article, where the judge directly answers the question; QA with article, (only on extractive tasks) where the judge directly answers the question given the article.
For judge models we use Gemma7B (V1), GPT-3.5, Gemini Pro 1.0 and Gemini Pro 1.5. Our main experiments use Gemini Pro 1.5 as debaters/consultants.
Assigned-role results
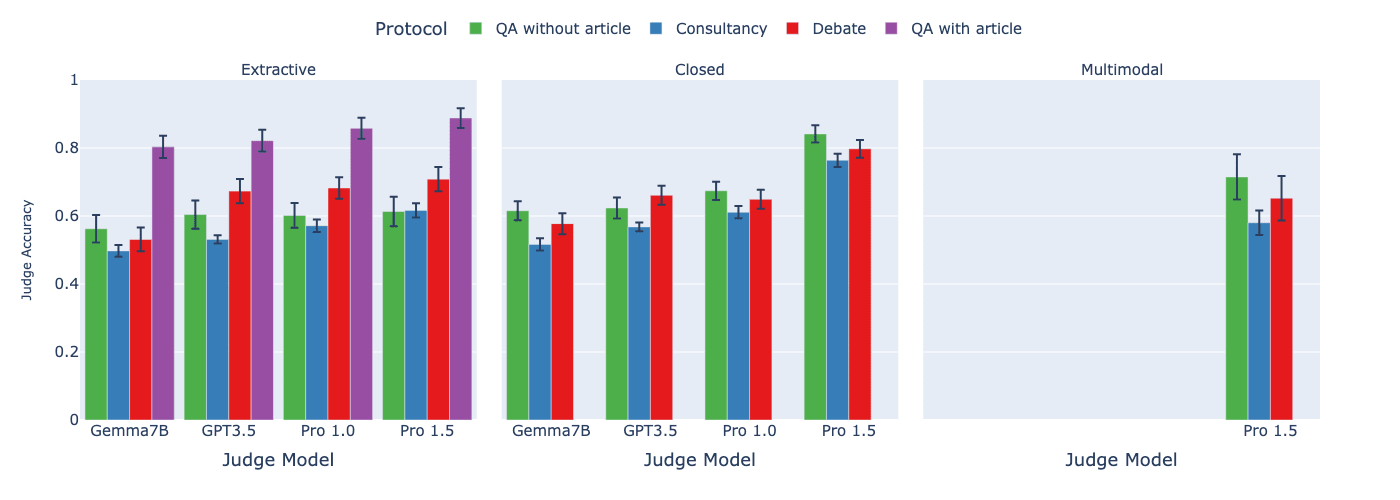
We first look at assigned-role protocols, consultancy and debate, meaning that the consultants/debaters do not get to choose which side to argue for. We compare these to the two direct QA protocols.
Findings:
- We find that debate consistently outperforms consultancy across all tasks, previously only shown on a single extractive QA task in Khan et al., 2024. See paper details for significance levels.Comparing debate to direct question answering baselines, the results depend on the type of task:
- In extractive QA tasks with information asymmetry, debate outperforms QA without article as in the single task of Khan et al., 2024, but not QA with article. For other tasks, when the judge is weaker than the debaters (but not too weak), we find either small or no advantage to debate over QA without article.
Open-role results
We now look at open debate, where a protagonist debater chooses which answer to argue for, and open consultancy, where the consultant chooses which answer to argue for.
Rather than generating new data, we filter our consultancy evaluations by selecting only those consultancy transcripts in which the assignment of the consultant matches the answer chosen by the consultant model under the format of direct QA. We also reuse existing debate evaluation data and identify the protagonist as the debater whose assigned answer matches the debater model's answer under direct QA (as in open consultancy).
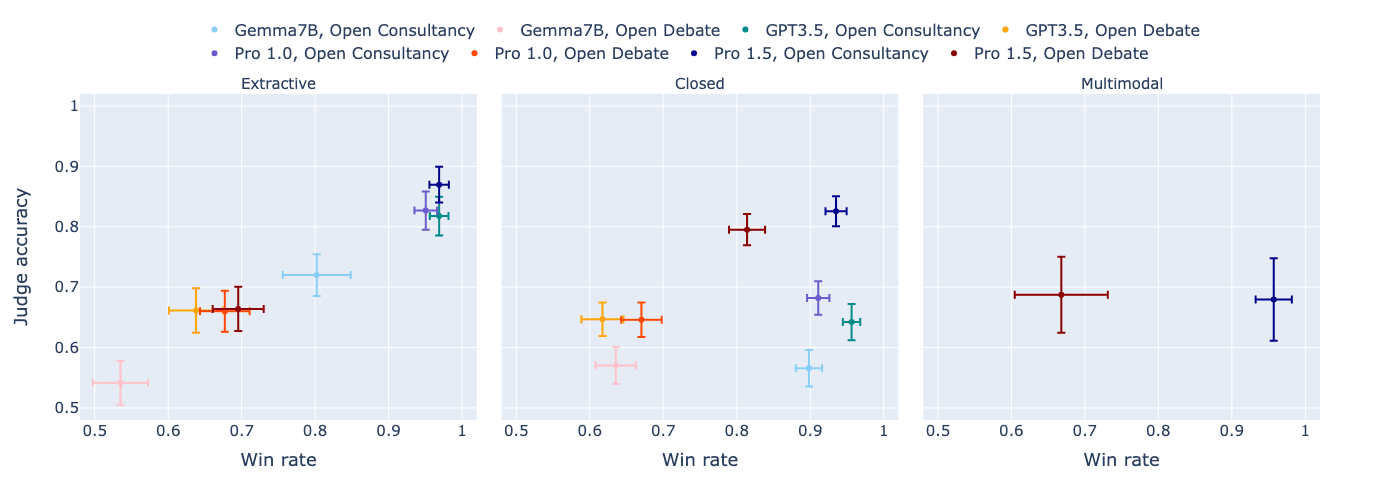
We first look at how open consultancy and open debate contrast, when looking at the resulting judge accuracy vs the win-rate of the consultant/protagonist (how often they convince the judge, irrespective of correctness):
We then split out into the cases where the consultant/protagonist was correct vs incorrect in their choice:
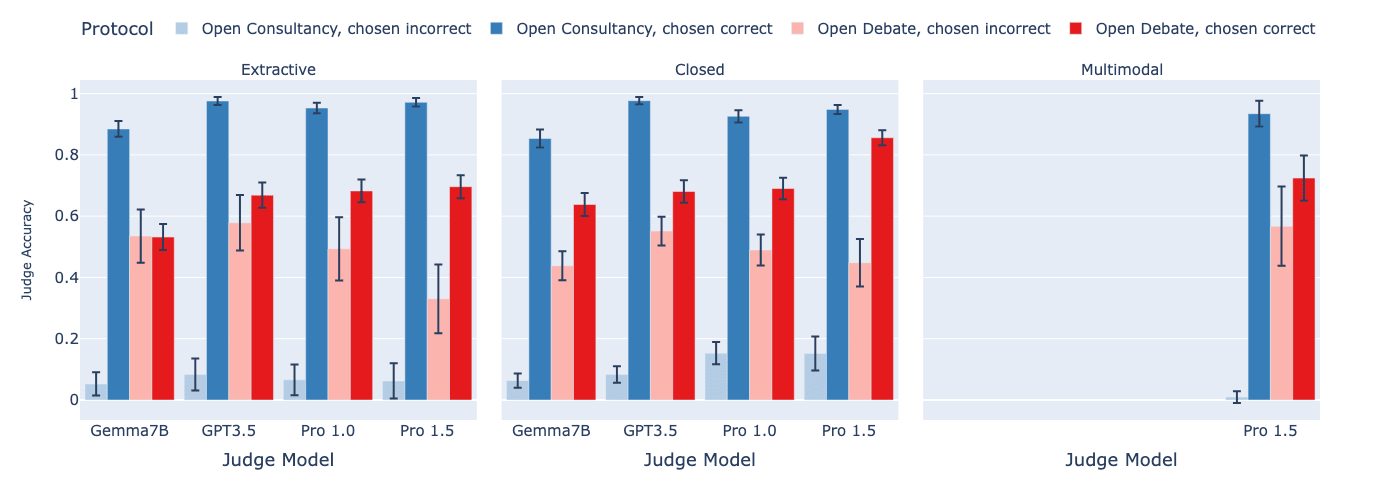
Findings:
- In open consultancy, the judge is equally convinced by the consultant, whether or not the consultant has chosen to argue for the correct answer. Thus, using weak judges to provide a training signal via consultancy runs the risk of amplifying the consultant's incorrect behaviour. In open debate, in contrast, the judge follows the debater's choice less frequently than in open consultancy. When the debater chooses correctly, the judge does a bit worse than in open consultancy. But when the debater chooses incorrectly, the judge does a lot better at discerning this. Thus, the training signal provided by the weak judge in open debate is less likely to amplify incorrect answers than in open consultancy.
Persuasiveness in Debate
We now analyse the relative persuasiveness of debaters, motivated by debate as a scalable oversight training protocol. As a proxy for training models to win at the debate game, we instead consider a debater model's relative strength at persuading the judge (in inference-only debate) and investigate how that correlates with judge accuracy. We use a range of debater models (and for the strongest we use best-of-4 sampling, denoted Bo4) and investigate their persuasiveness on the judge, by measuring their cross-play win-rate (frequency that the judge chooses their answer) and modeling their latent skill with an Elo rating, studying how these correlate with judge accuracy, following a similar setup to Khan et al., 2024. In the following plots we use Gemini Pro 1.5 as judge (see paper for similar findings with Gemini Pro 1.0).
We first look at the Elo ratings for different debater models, depending on whether they are arguing for the correct or incorrect answer:
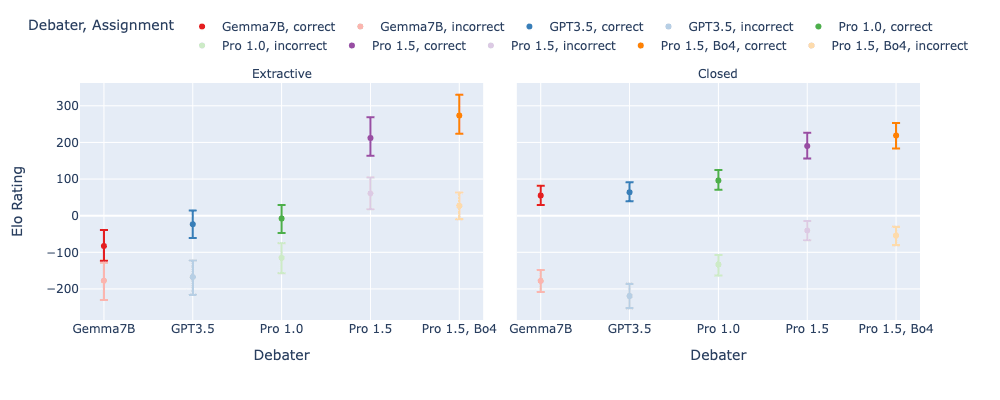
- We see it is often easier to argue for the truth, in particular on closed tasks, and that stronger models tend to score higher Elo.
We next look at the difference between the correct-player's rating and the incorrect-players rating, (the advantage that the correct debater has) and compare it to the player's aggregate Elo rating (a mix of correct and incorrect assignments).:
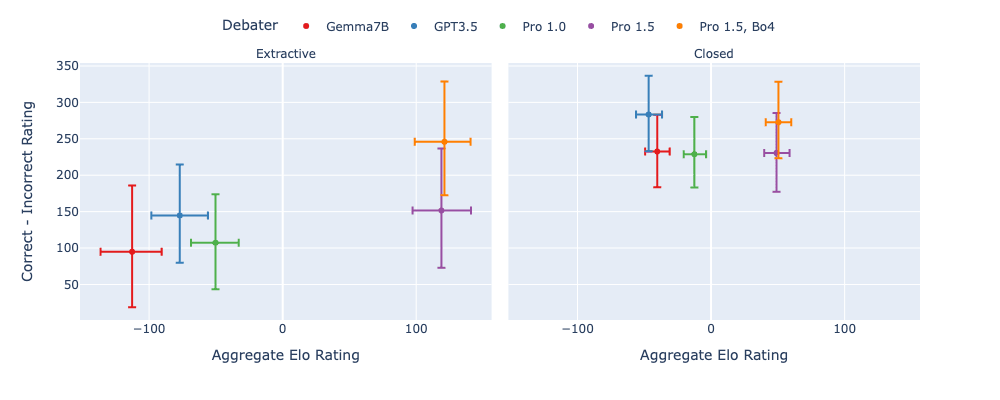
- All debaters display a positive difference, indicating an advantage for being assigned the correct answer. However, compared to Khan et al., 2024 we don't see such a clear trend of this advantage increasing with increasing Elo. For extractive tasks it appears it gets slightly easier for honest debaters as models increase their convincingness, whereas on closed tasks there is less of a clear trend.
We then look at how aggregate Elo correlates with judge accuracy, to see if higher skilled debaters lead to improvements in judge accuracy:
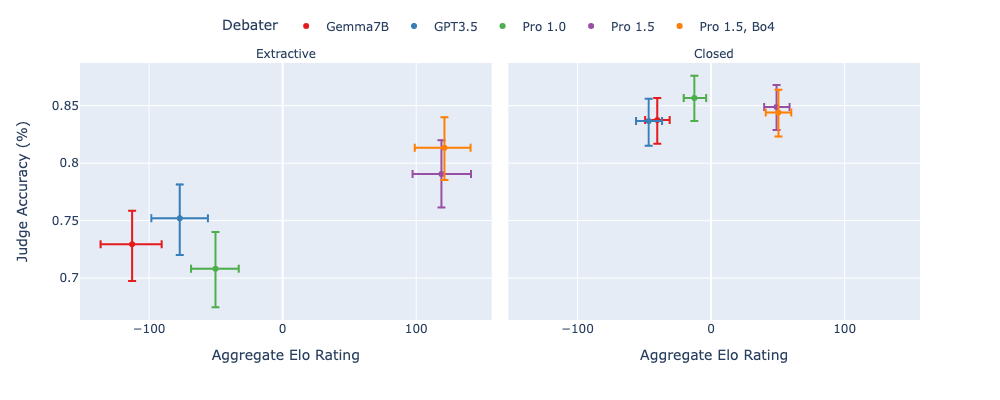
- On extractive tasks, stronger models have higher aggregate Elo and these lead to higher judge accuracy. On closed tasks, however, there's less differentiation between debaters, both in terms of aggregate Elo and judge accuracy.
Summary
- We found that, on previously unstudied closed QA tasks, weak judges achieve higher accuracy in the debate protocol, than consultancy, and around the same as direct question answering. On open debate and open consultancy, we were able to further see the strengths and weaknesses of these approaches: weak judges do slightly better in consultancy compared to debate when the consultant/debater chooses correctly -- however, weak judges do much worse in consultancy compared to debate when the consultant chooses incorrectly.We find that, across tasks, stronger debaters (as measured by their Elo scores) lead to higher judge accuracy, but the effect was relatively weak compared to Radhakrishnan, 2023 and Khan et al., 2024 which studied the QuALITY task only.We interpret these as weakly promising signs for debate, though note that this is just a proxy for how debate will fare as a training protocol (all our experiments are done as inference-only).
Limitations
- Our work studies consultancy/debate in an inference-only setting by prompting models to play these roles. Whilst providing some evidence of the models' abilities to play these roles, what we actually care about are the safety properties of the optima/equilibria that arise due to the incentives produced by training models specifically in consultancy/debate decision-problems/games. While results on win rates, and advantages arising from selecting correct vs incorrect answers provide some evidence of their abilities to play these games, they don't give us much evidence about their effectiveness as scalable oversight training protocols.Further, the models we used as consultants/debaters were all fine-tuned with RLHF for, among other qualities, honesty, which is what debate is aiming to incentivise, and for example may hamper the dishonest consultant/debater (see discussion in Appendix C.3 of Khan et al., 2024). It would be interesting to perform our study in the helpful-only setting.Our work attempts to analogise the weak-strong dynamics of humans supervising superhuman AI, but our study is limited by not using humans and using AI which is far from superhuman on many capabilities. A key uncertainty is whether humans will be able to appropriately follow and accurately judge arguments made by superhuman AI.
Future work
- Train debater and consultant models via the signal provided by the judge on the tasks studied here. This is the full setup required to test scalable oversight methods. In such work we would hope to see that both judge accuracy and debater skill on the task improve over training. We hypothesise that current fine-tuning approaches applied to the models we use as judges, supervised fine-tuning (SFT) and RLHF, favour direct QA over debate, as direct QA is typically the format of evaluation benchmarks which are used to select fine-tuning approaches, and which may be more common in the fine-tuning data (e.g. users typically ask questions and expect an answer). We suspect that judging a debate, in a discerning manner, is more out-of-distribution. This presents some future directions, such as fine-tuning judges on the task of judging debates, perhaps using SFT.Relatedly, the work could further be extended through a study involving human judges. Another direction could be to implement other forms of weak-strong asymmetry such as giving consultants/judges access to tool use, code execution, and different modality access. We could also investigate other scalable oversight protocols, e.g. debate with cross-examination or iterated amplification. Further, we could study the limits of the protocols: how they perform under distribution shift, e.g. from easy to hard tasks, and whether they are robust to misaligned models.
Acknowledgements
We'd like to thank the following for their help and feedback on this work: Vikrant Varma, Rory Greig, Sebastian Farquhar, Anca Dragan, Edward Grefenstette, Tim Rocktaschel, Akbir Khan, Julian Michael, David Rein, Salsabila Mahdi, Matthew Rahtz and Samuel Arnesen.
Authors
Zachary Kenton, Noah Y. Siegel, János Kramár, Jonah Brown-Cohen, Samuel Albanie, Jannis Bulian, Rishabh Agarwal, David Lindner, Yunhao Tang, Noah D. Goodman, Rohin Shah
* equal contribution.
Discuss
