


Proteins, vital macromolecules, are characterized by their amino acid sequences, which dictate their three-dimensional structures and functions in living organisms. Effective generative protein modeling requires a multimodal approach to simultaneously understand and generate sequences and structures. Current methods often rely on separate models for each modality, limiting their effectiveness. While advancements like diffusion models and protein language models have shown promise, there is a critical need for models that integrate both modalities. Recent efforts like Multiflow highlight this challenge, demonstrating the limitations in sequence understanding and structure generation, underscoring the potential of combining evolutionary knowledge with sequence-based generative models.
There is increasing interest in developing protein LMs that operate on an evolutionary scale, including ESM, TAPE, ProtTrans, and others, which excel in various downstream tasks by capturing evolutionary information from sequences. These models have shown promise in predicting protein structures and the effects of sequence variations. Concurrently, diffusion models have gained traction in structural biology for protein generation, with various approaches focusing on different aspects, such as protein backbone and residue orientations. Models like RFDiffusion and ProteinSGM demonstrate the ability to design proteins for specific functions, while Multiflow integrates structure-sequence co-generation.
Researchers from Nanjing University and ByteDance Research have introduced DPLM-2, a multimodal protein foundation model that expands the discrete diffusion protein language model to include both sequences and structures. DPLM-2 learns the joint distribution of sequences and structures from experimental and synthetic data using a lookup-free quantization tokenizer. The model addresses challenges like enabling structural learning and exposure bias in sequence generation. DPLM-2 effectively co-generates compatible amino acid sequences and 3D structures, outperforming existing methods in various conditional generation tasks while providing structure-aware representations beneficial for predictive applications.
DPLM-2 is a multimodal diffusion protein language model that integrates protein sequences and their 3D structures using a discrete diffusion probabilistic framework. It employs a token-based representation to convert the protein backbone’s 3D coordinates into discrete structure tokens, ensuring alignment with corresponding amino acid sequences. Training DPLM-2 involves a high-quality dataset, focusing on denoising across various noise levels to generate both protein structures and sequences simultaneously. Additionally, DPLM-2 utilizes a Lookup-Free Quantizer (LFQ) for efficient structure tokenization, achieving high reconstruction accuracy and strong correlations with secondary structures like alpha helices and beta sheets.
The study assesses DPLM-2 across various generative and understanding tasks, focusing on unconditional protein generation (structure, sequence, and co-generation) and several conditional tasks like folding inverse folding, and motif scaffolding. For unconditional protein generation, we evaluate the model’s ability to produce 3D structures and amino acid sequences simultaneously. The quality, novelty, and diversity of the generated proteins are analyzed using metrics such as designability and foldability alongside comparisons to existing models. DPLM-2 demonstrates strong performance in generating diverse, high-quality proteins and exhibits significant advantages over baseline models.
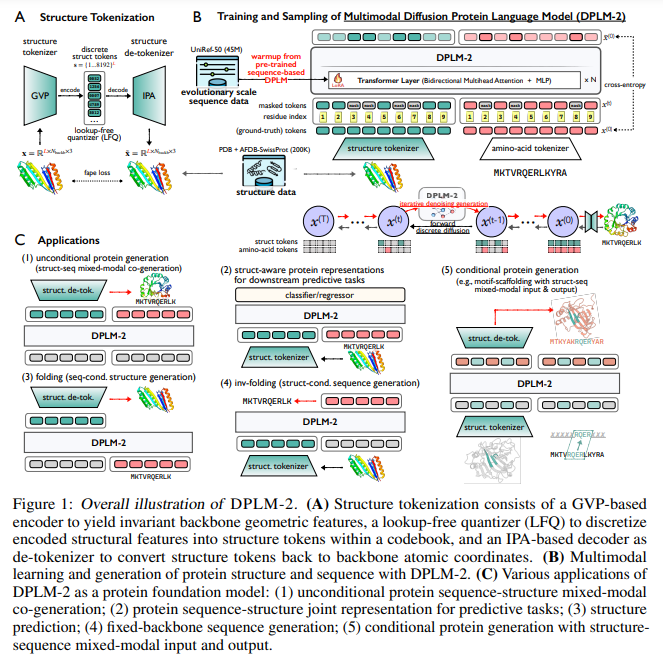
DPLM-2 is a multimodal diffusion protein language model designed to understand, generate, and reason about protein sequences and structures. Although it performs well in protein co-generation, folding, inverse folding, and motif scaffolding tasks, several limitations persist. The limited structural data hinders DPLM-2’s capacity to learn robust representations, particularly for longer protein chains. Additionally, while tokenizing structures into discrete symbols aids multimodal modeling, it may result in a loss of detailed structural information. Future research should integrate strengths from both sequence-based and structure-based models to enhance protein generation capabilities.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
The post DPLM-2: A Multimodal Protein Language Model Integrating Sequence and Structural Data appeared first on MarkTechPost.
