


Artificial intelligence (AI) and machine learning (ML) revolve around building models capable of learning from data to perform tasks like language processing, image recognition, and making predictions. A significant aspect of AI research focuses on neural networks, particularly transformers. These models use attention mechanisms to process data sequences more effectively. By allowing the model to focus on the most relevant parts of the data, transformers can perform complex tasks that require understanding and prediction across various domains.
One major issue in AI model development is understanding how internal components, such as attention heads in transformers, evolve and specialize during training. While the overall performance of these models has improved, researchers still struggle to grasp how different components contribute to the model’s function. Refining model behavior or improving interpretability remains difficult without detailed insights into these processes, leading to challenges in optimizing model efficiency and transparency. This limits progress in model improvement and hinders the ability to explain how decisions are made.
Several tools have been developed to study how neural networks operate. These include techniques like ablation studies, where specific model components are disabled to observe their role, and clustering algorithms, which group similar components based on their behavior. While these methods have shown that attention heads specialize in token prediction and syntax processing tasks, they often provide static snapshots of the model at the end of training. Such approaches need insight into how the internal structures of models evolve dynamically throughout the learning process. They fail to capture the gradual changes as these models transition from basic to complex functions.

Researchers from the University of Melbourne and Timaeus have introduced the refined Local Learning Coefficient (rLLC). This new method provides a quantitative measure of model complexity by analyzing the development of internal components like attention heads. By focusing on the refined LLCs, the researchers offer a more detailed understanding of how different components within transformers specialize and differentiate over time. Their approach allows for monitoring the evolutionary changes of attention heads throughout the training process, providing clearer insights into their functional roles. This methodology helps track the progressive differentiation of attention heads, revealing how they move from a uniform state at the beginning of training to distinct roles as learning continues.
The rLLC examines how attention heads respond to data structures and the geometry of the loss landscape. During training, neural networks adjust their weights based on how well they minimize prediction errors (loss). The rLLC captures this adjustment by quantifying how different heads specialize based on their interaction with specific data structures, such as bigrams or complex patterns like induction or bracket matching. The researchers used a two-layer attention-only transformer for their experiments, focusing on how the heads in these layers evolved. Early in training, attention heads were observed to handle simpler tasks, such as processing individual tokens or smaller word groups (bigrams). As training progressed, heads diverged into more specialized roles, focusing on complex tasks like handling multigrams, which involve predicting token sequences that are not necessarily contiguous.
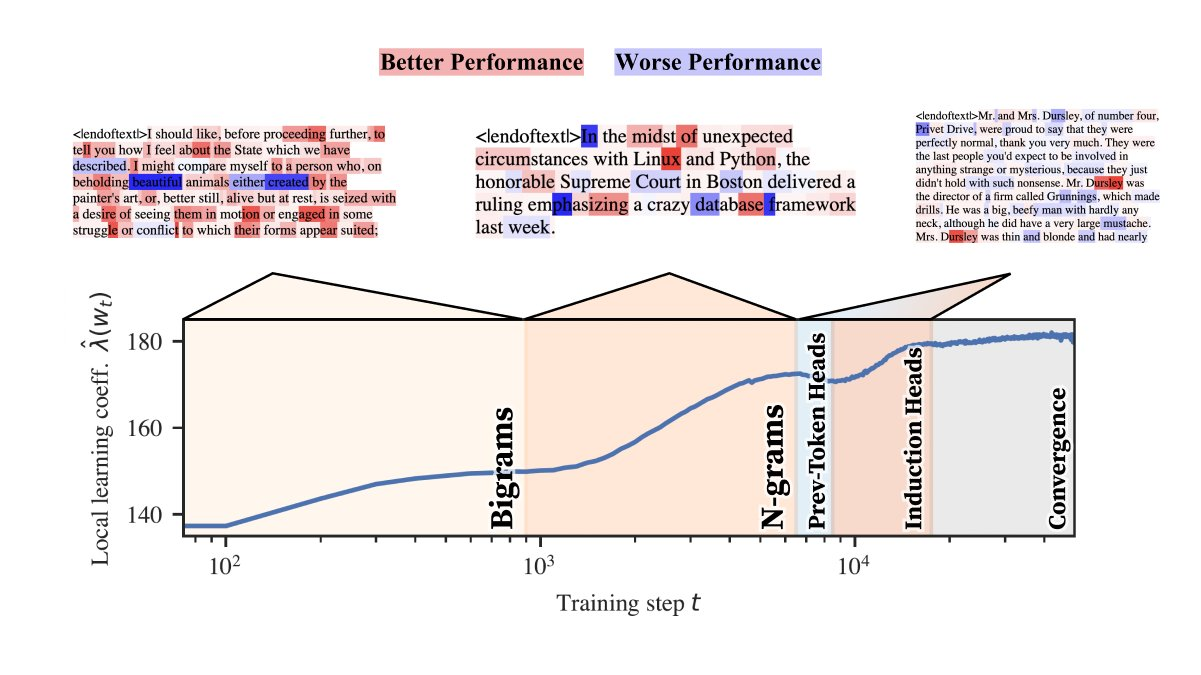
The research demonstrated several key findings. First, attention heads specialized in distinct phases. During the early stages of training, the heads learned to process simple data structures like bigrams. Over time, some heads transitioned to specialize in more complex tasks, such as handling skip n-grams (multigrams), sequences that span multiple tokens with gaps. The study found that certain heads, labeled induction heads, played crucial roles in recognizing recurring patterns, such as those seen in code and natural language processing tasks. These heads contributed to the model’s ability to predict repeated syntactic structures effectively. By tracking the rLLC over time, the researchers could observe the stages of these transitions. For example, the development of multigram prediction circuits was identified as a key component, with heads from layer 1 in the transformer model showing increased specialization toward the end of the training process.
In addition to revealing the specialization of attention heads, the study discovered a previously unknown multigram circuit. This circuit is critical for managing complex token sequences and involves coordination between different attention heads, especially in layer 1. The multigram circuit demonstrates how different heads, initially tasked with processing simple sequences, evolve to handle more intricate patterns through their coordination. The research also highlighted that heads with lower LLC values tended to rely on simple algorithms like induction, while those with higher values memorized more complex patterns. Refined LLCs allow for identifying functional roles without relying on manual or mechanistic interpretability methods, making the process more efficient and scalable.
Overall, this study contributes significant advancements in understanding the developmental process of transformers. By introducing the refined LLC, researchers offer a powerful tool to analyze how different components in a neural network specialize throughout the learning process. This developmental interpretability approach bridges the gap between understanding data distribution structures, model geometry, learning dynamics, and computational specialization. The findings pave the way for improved interpretability in transformer models, offering new opportunities to enhance their design and efficiency in real-world applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
The post Refined Local Learning Coefficients (rLLCs): A Novel Machine Learning Approach to Understanding the Development of Attention Heads in Transformers appeared first on MarkTechPost.
