


Retrieval-augmented generation (RAG) has become a key technique in enhancing the capabilities of LLMs by incorporating external knowledge into their outputs. RAG methods enable LLMs to access additional information from external sources, such as web-based databases, scientific literature, or domain-specific corpora, which improves their performance in knowledge-intensive tasks. RAG systems can generate more contextually accurate responses using internal model knowledge and retrieved external data. Despite its advantages, RAG systems often need help consolidating the retrieved information with internal knowledge, leading to potential conflicts and decreased reliability in model outputs.
When RAG systems retrieve external data, there is always the risk of pulling in irrelevant, outdated, or malicious information. A major challenge associated with RAG is the issue of imperfect retrieval. This issue can lead to inconsistencies and incorrect outputs when the LLM attempts to merge its internal knowledge with flawed external content. For example, studies have shown that up to 70% of retrieved passages in real-world scenarios do not directly contain true answers, resulting in degraded performance of LLMs with RAG augmentation. The problem is exacerbated when LLMs are faced with complex queries or domains where the reliability of external sources is uncertain. To tackle this, the researchers focused on creating a system that can effectively manage and mitigate these conflicts through improved consolidation mechanisms.
Traditional approaches to RAG have included various strategies to enhance retrieval quality and robustness, such as filtering irrelevant data, using multi-agent systems to critique retrieved passages or employing query rewriting techniques. While these methods have shown some effectiveness in improving initial retrieval, they are limited by their inability to handle the inherent conflicts between internal and external information in the post-retrieval stage. As a result, they need to catch up when the quality of retrieved data could be better and consistent, leading to incorrect responses. The research team sought to address this gap by developing a method that filters and selects high-quality data and consolidates conflicting knowledge sources to ensure the final output’s reliability.
Researchers from Google Cloud AI Research and the University of Southern California developed Astute RAG, which introduces a unique approach to tackle the imperfections of retrieval augmentation. The researchers implemented an adaptive framework that dynamically adjusts how internal and external knowledge is utilized. Astute RAG initially elicits information from LLMs’ internal knowledge, which is a complementary source to external data. It then performs source-aware consolidation by comparing internal knowledge with retrieved passages. This process identifies and resolves knowledge conflicts through an iterative refinement of information sources. The final response is determined based on the reliability of consistent data, ensuring that the output is not influenced by incorrect or misleading information.
The experimental results showcased the effectiveness of Astute RAG in diverse datasets such as TriviaQA, BioASQ, and PopQA. On average, the new approach achieved a 6.85% improvement in overall accuracy compared to traditional RAG systems. When the researchers tested Astute RAG under the worst-case scenario, where all retrieved passages were unhelpful or misleading, the method still outperformed other systems by a considerable margin. For instance, while other RAG methods failed to produce accurate outputs in such conditions, Astute RAG reached performance levels close to using only internal model knowledge. This result indicates that Astute RAG effectively overcomes the inherent limitations of existing retrieval-based approaches.
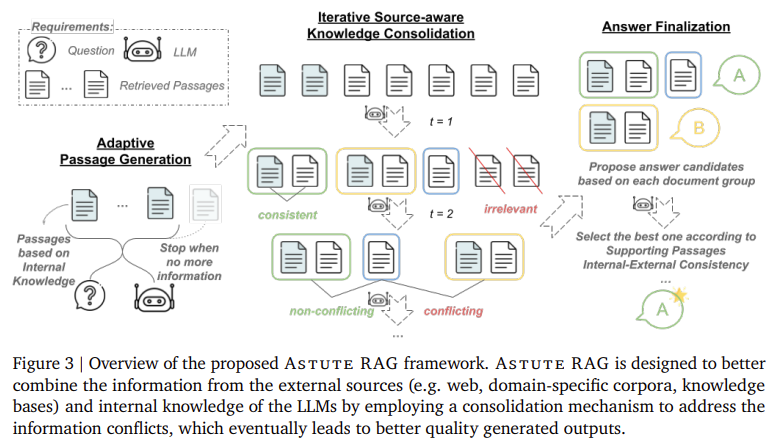
The research’s key takeaways can be summarized as follows:
- Imperfect Retrieval as a Bottleneck: The research identifies imperfect retrieval as a significant cause of failure in existing RAG systems. It highlights that 70% of retrieved passages in their study did not contain direct answers.Knowledge Conflicts: The study reveals that 19.2% of instances showed knowledge conflicts between internal and external sources, with 47.4% of conflicts resolved correctly by internal knowledge alone.Performance in Various Datasets: After three iterations of consolidation, Astute RAG achieved an accuracy of 84.45% in TriviaQA and 62.24% in BioASQ, surpassing the best-performing baseline RAG methods.Robustness under Worst-Case Conditions: The method maintained high performance even when all external data were misleading, demonstrating its robustness and ability to handle extreme cases of knowledge conflict.Iterative Knowledge Consolidation: Astute RAG successfully filtered out irrelevant or harmful data by refining information through multiple iterations, ensuring that the LLM generated reliable and accurate responses.


In conclusion, Astute RAG addresses the critical challenge of knowledge conflicts in retrieval-augmented generation by introducing an adaptive framework that effectively consolidates internal and external information. This approach mitigates the negative effects of imperfect retrieval and enhances the robustness and reliability of LLM responses in real-world applications. The experimental results indicate that Astute RAG is a solution for tackling the limitations of existing RAG systems, particularly in challenging scenarios with unreliable external sources.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – The GenAI Data Retrieval Conference (Promoted)
The post Google AI Researchers Propose Astute RAG: A Novel RAG Approach to Deal with the Imperfect Retrieval Augmentation and Knowledge Conflicts of LLMs appeared first on MarkTechPost.
