


LLMs show great promise as advanced information access engines thanks to their ability to generate long-form, natural language responses. Their large-scale pre-training on vast datasets allows them to answer various questions. Techniques like instruction tuning and reinforcement learning from human feedback further improve the coherence and detail of their responses. However, LLMs need help with hallucinations and generating inaccurate content, particularly in long-form responses, where ensuring factual accuracy is difficult. Despite improvements in reasoning and helpfulness, the issue of factuality remains a key obstacle to their real-world adoption.
Researchers from National Taiwan University have developed FACTALIGN, a framework designed to enhance the factual accuracy of LLMs while preserving their helpfulness. FACTALIGN introduces fKTO, a fine-grained, sentence-level alignment algorithm based on the Kahneman-Tversky Optimization method. By leveraging recent advancements in automatic factuality evaluation, FACTALIGN aligns LLM responses with fine-grained factual assessments. Experiments on open-domain and information-seeking prompts show that FACTALIGN significantly improves factual accuracy without sacrificing helpfulness, boosting the factual F1 score. The study’s key contributions include the fKTO algorithm and the FACTALIGN framework for improving LLM reliability.
Recent research on language model alignment focuses on aligning models with human values. InstructGPT and LLaMA-2 demonstrated improved instruction-following using reinforcement learning from human feedback (RLHF). Fine-grained RLHF and methods like Constitutional AI introduced AI-based feedback to reduce human annotation needs. Alternatives like DPO and KTO offer simpler alignment objectives without RL, with fKTO extending KTO to sentence-level alignment using factuality evaluators. Factuality challenges, such as hallucination, have been addressed through techniques like retrieval-augmented generation and self-checking models like SelfCheckGPT. Recent methods like FactTune and FLAME focus on improving factuality using factuality evaluators and alignment strategies, which fKTO enhances further.
The FACTALIGN framework includes a pipeline for assessing long-form factuality and an alignment process to improve factual accuracy and helpfulness in LMs. It utilizes atomic statements from sentences to create a sentence-level loss, allowing for more effective alignment than algorithms requiring pairwise preference labels. The overall loss function combines response-level and sentence-level losses, assigning a weight to the latter. The framework employs iterative optimization to address discrepancies between offline response assessments and the model’s training data. This involves periodically sampling new responses, assessing their factuality, and incorporating these into the training dataset for continuous improvement.
The experiments demonstrate the effectiveness of the FACTALIGN framework compared to various models, including GPT-4-Turbo and LLaMA-2-70B-Chat. FACTALIGN significantly enhances the factuality and helpfulness of the baseline Gemma-2B model, achieving improvements of 40.1% in f1@100 and 29.2% in MT-Bench scores. The findings indicate that FACTALIGN primarily boosts factual recall, increasing factual claims from 66.8 to 135.1 while slightly improving factual precision. An ablation study shows the necessity of iterative optimization and highlights the positive impact of both the fKTO loss and general-domain data on overall model performance.
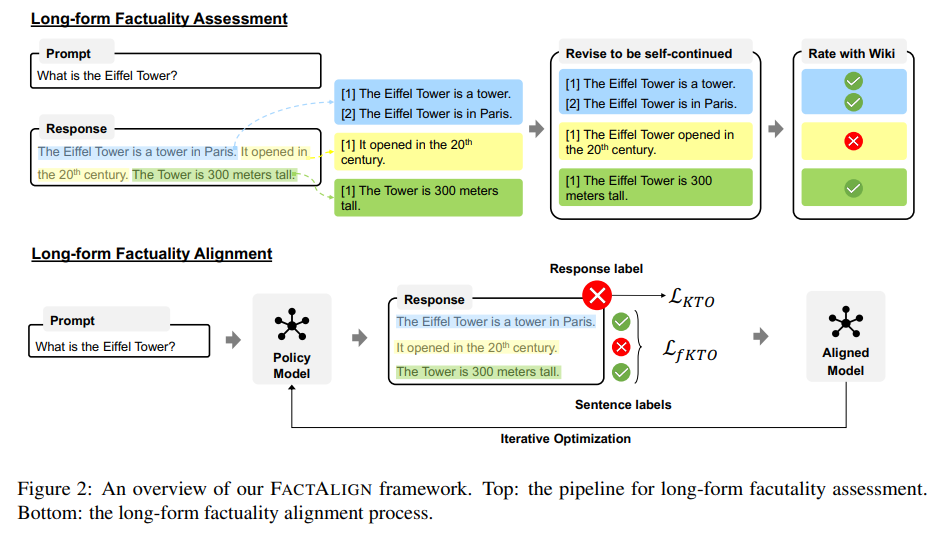
In conclusion, the study introduces FACTALIGN, a framework to improve the factual accuracy of long-form responses generated by LLMs. The framework integrates a data construction process and a fine-grained alignment algorithm called fKTO, enhancing the factuality and helpfulness of LLM outputs. The analysis shows that FACTALIGN allows precise control over factual precision and recall levels. By addressing issues like hallucination and non-factual content, FACTALIGN demonstrates a significant improvement in the accuracy of LLM responses to open-domain and information-seeking prompts, enabling LLMs to provide richer information while maintaining factual integrity.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
Interested in promoting your company, product, service, or event to over 1 Million AI developers and researchers? Let’s collaborate!
The post FactAlign: A Novel Alignment AI Framework Designed to Enhance the Factuality of LLMs’ Long-Form Responses While Maintaining Their Helpfulness appeared first on MarkTechPost.
