


LLMs, characterized by their massive parameter sizes, often lead to inefficiencies in deployment due to high memory and computational demands. One practical solution is semi-structured pruning, particularly the N: M sparsity pattern, which enhances efficiency by maintaining N non-zero values among M parameters. While hardware-friendly, such as for GPUs, this approach faces challenges due to the vast parameter space in LLMs. Methods like SparseGPT and Wanda use small calibration sets and importance criteria to select redundant parameters. Still, these are limited in scope, hindering generalization and introducing errors in representing model quality across diverse domains.
Researchers from NVIDIA and the National University of Singapore introduced MaskLLM, a learnable pruning method that applies N: M sparsity to LLMs, reducing computational overhead during inference. Unlike traditional methods, MaskLLM uses Gumbel Softmax sampling to model sparsity as a learnable distribution, enabling efficient end-to-end training on large datasets. This approach enhances mask accuracy and transferability, allowing the learned sparsity patterns to be applied across different tasks or domains. Experiments on models like LLaMA-2 and GPT-3 show significant performance improvements, with MaskLLM achieving a perplexity of 6.72 compared to 10.42 in SparseGPT.
Pruning methods are effective in compressing LLMs by removing redundant parameters. These methods can be categorized into structured, unstructured, and semi-structured pruning. Structured pruning eliminates substructures like attention heads, while unstructured pruning zeros out individual parameters, offering more flexibility but less acceleration efficiency. Semi-structured pruning, such as N: M sparsity, strikes a balance by combining structured patterns with fine-grained sparsity to enhance efficiency and flexibility. Recently, learnable sparsity methods have gained attention, particularly in vision models, and this work pioneers the application of learnable N: M masks in frozen LLMs, addressing the challenge of large-scale parameters.
The MaskLLM framework introduces N: M sparsity to optimize LLMs by selecting binary masks for parameter blocks, ensuring efficient pruning without significantly degrading model performance. Focusing on 2:4 sparsity, it selects masks where two out of four values remain non-zero. The challenge of non-differentiable mask selection is tackled through Gumbel Softmax, enabling differentiable sampling and mask optimization via gradient descent. MaskLLM learns masks from large-scale data, transferring them to downstream tasks. Sparse weight regularization maintains post-pruning quality, and prior masks improve the learning process, ensuring efficient and effective model compression.
The researchers evaluated MaskLLM on multiple LLMs (LLaMA-2, Nemotron-4, GPT-3 multilingual) ranging from 843M to 15B parameters. MaskLLM learns 2:4 sparsity masks through end-to-end training, outperforming baselines like SparseGPT and Wanda in accuracy and perplexity. The method improves mask quality with large datasets and shows robustness in low-resource settings. Transfer learning using pre-computed masks accelerates training while maintaining large remaining weights enhances downstream task performance. MaskLLM’s stochastic exploration ensures high-quality mask discovery, with results surpassing SparseGPT in perplexity after training with 1280 samples.
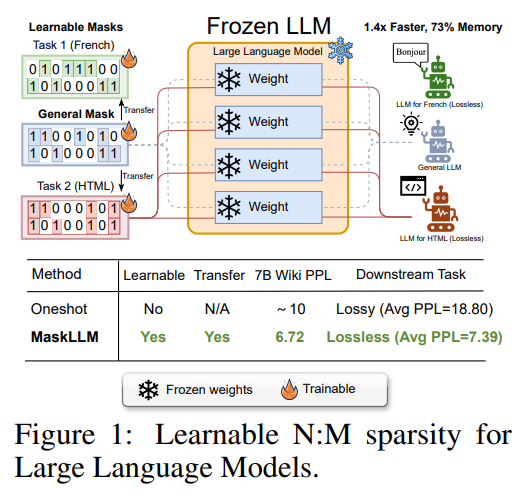
MaskLLM introduces a learnable pruning method for applying N: M sparsity in LLMs to reduce computational costs during inference. Instead of using a predefined importance criterion, it models N: M sparsity patterns through Gumbel Softmax sampling, enabling end-to-end training on large datasets. MaskLLM offers high-quality mask learning and transferability across domains. Tested on LLaMA-2, Nemotron-4, and GPT-3, with sizes ranging from 843M to 15B parameters, MaskLLM outperformed state-of-the-art methods in perplexity and efficiency. Its masks can be customized for lossless downstream task performance.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 50k+ ML SubReddit.
Subscribe to the fastest-growing ML Newsletter with over 26k+ subscribers.
The post MaskLLM: A Learnable AI Method that Facilitates End-to End Training of LLM Sparsity on Large-Scale Datasets appeared first on MarkTechPost.
