


Large language models (LLMs) and image generators face a critical challenge known as model collapse. This phenomenon occurs when the performance of these AI systems deteriorates due to the increasing presence of AI-generated data in their training datasets. As generative AI evolves, evidence suggests that retraining models on their outputs can lead to various anomalies in subsequent generations. In LLMs, this process introduces irreparable defects, resulting in the production of nonsensical or gibberish output. While recent studies have demonstrated aspects of model collapse empirically in various settings, a comprehensive theoretical understanding of this phenomenon remains elusive. Researchers are now grappling with the urgent need to address this issue to ensure the continued advancement and reliability of generative AI technologies.
Researchers have made several attempts to address the challenges of model collapse in large language models and image generators. Current LLMs and diffusion models are trained on predominantly human-generated text and web-scale image datasets, potentially exhausting all available clean data on the internet. As synthetic data generated by these models becomes increasingly prevalent, recent works have empirically demonstrated various aspects of model collapse in different settings.
Theoretical approaches to analyze the effect of iterative training on self-generated or mixed data have emerged. These include studies on bias amplification in data-feedback loops, analysis of finite sampling bias and function approximation errors in Gaussian cases, and exploration of “self-consuming loops” in vision models. Some researchers have investigated scenarios involving clean and synthesized data, revealing that a sufficiently high proportion of clean data can help maintain the generator’s ability to accurately reflect the true data distribution.
It’s important to note that the model collapse phenomenon differs from self-distillation, which can improve model performance through controlled data generation processes. In contrast, model collapse occurs when there is no control over the data generation process, as it involves synthesized data from various sources on the web.
Researchers from Meta FAIR, Center for Data Science, New York University, and Courant Institute, New York University, introduce a theoretical framework to analyze model collapse in the context of high-dimensional supervised learning with kernel regression. Kernel methods, despite their simplicity, offer a powerful approach for capturing non-linear features while remaining within the domain of convex optimization. These methods have recently gained renewed attention as proxies for neural networks in various regimes, including the infinite-width limit and the lazy training regime.
The proposed theoretical framework builds upon existing research on power-law generalization errors in regularized least-squares kernel algorithms. It considers the power-decay spectrum of the kernel (capacity) and the coefficients of the target function (source), which have been shown to give rise to power-law scaling of test errors in terms of dataset size and model capacity. This approach aligns with empirically observed scaling laws in large language models and other AI systems.
By utilizing insights from Gaussian design studies and random feature models, this theoretical study aims to provide a comprehensive understanding of model collapse. The framework incorporates elements from nonparametric literature, spectral analysis, and deep neural network error scaling to create a robust foundation for investigating the mechanisms underlying model collapse in kernel regression settings.
This theoretical study on model collapse in kernel regression settings offers several key contributions:
1. An exact characterization of test error under iterative retraining on synthesized data is provided. The researchers derive an analytic formula that decomposes the test error into three components: the error from clean data training, an increase in bias due to synthetic data generation, and a scaling factor that grows with each iteration of data generation.
2. The study reveals that as the number of generations of synthetic data increases, learning becomes impossible due to the compounding effects of re-synthesizing data.
3. For power-law spectra of the covariance matrix, the researchers establish new scaling laws that quantitatively demonstrate the negative impact of training on synthetically generated data.
4. The study proposes an optimal ridge regularization parameter that corrects the value suggested in classical theory for clean data. This correction adapts to the presence of synthesized data in the training set.
5. A uniquel crossover phenomenon is identified where the appropriate tuning of the regularization parameter can mitigate the effects of training on fake data, transitioning from a fast error rate in the noiseless regime to a slower rate dependent on the amount of true data used in the initial fake data generation.
These findings provide a comprehensive theoretical framework for understanding and potentially mitigating the effects of model collapse in kernel regression settings, offering insights that could be valuable for improving the robustness of large language models and other AI systems.
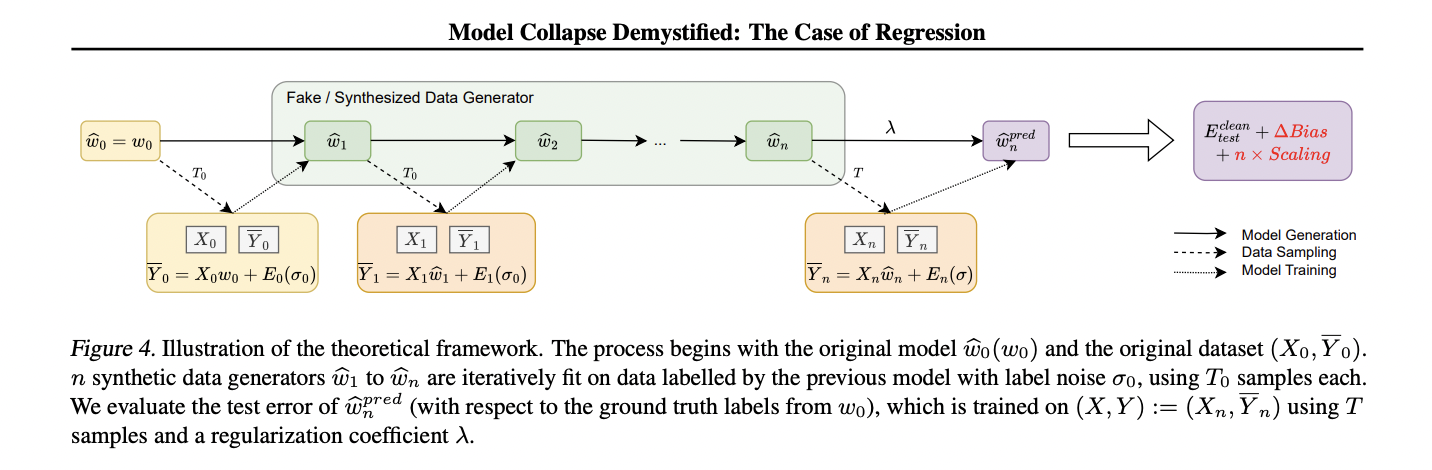
This framework for analyzing model collapse in kernel regression settings is built upon a carefully constructed setup that balances analytical tractability with the ability to exhibit a wide range of phenomena. The core of this framework is a data distribution model PΣ,w0,σ2 , where inputs x are drawn from a multivariate Gaussian distribution N(0, Σ), and labels y are generated by a linear ground truth function with added noise.
The study introduces a fake data generation process that iteratively creates new models. Starting from the original distribution PΣ,w0,σ2
0, each subsequent generation PΣ,wbn,σ2
n is created by fitting a model on data sampled from the previous generation. This process simulates the effect of training on increasingly synthetic data.
The downstream model, which is the focus of the analysis, is a ridge regression predictor wb
pred n. This predictor is trained on data from the nth generation of the fake data distribution but evaluated on the true data distribution. The researchers examine the dynamics of the test error Etest(wb
pred n) as the number of generations n increases.
While the framework is presented in terms of linear regression for clarity, the authors note that it can be extended to kernel methods. This extension involves replacing the input x with a feature map induced by a kernel K, allowing the framework to capture non-linear relationships in the data.


This theoretical framework developed in this study yields several important results that shed light on the dynamics of model collapse in kernel regression settings:
1. For unregularized regression, the test error of the downstream model grows linearly with the number of generations of synthetic data, indicating a clear degradation in performance.
2. In the regularized case, the test error is decomposed into three components: bias, variance, and an additional term that grows with the number of generations. This decomposition provides a clear picture of how model collapse manifests in the test error.
3. The study reveals that the strength of the fake data generator, represented by the sample size T0, plays a crucial role in determining the impact on the downstream model’s performance. When T0 is sufficiently large (under-parametrized regime), only the variance term is affected. However, when T0 is small (over-parametrized regime), both bias and variance terms are negatively impacted.
4. In the absence of label noise, the study demonstrates that model collapse can still occur due to insufficient data in the synthetic data generation process. This is particularly pronounced when the fake data generators are independent across generations, leading to an exponential growth in the bias term.
5. The research provides explicit formulae for the test error in various scenarios, including isotropic and anisotropic feature covariance structures. These formulae allow for a detailed analysis of how different parameters influence the severity of model collapse.
These results collectively provide a comprehensive theoretical understanding of model collapse, offering insights into its mechanisms and potential mitigation strategies through appropriate regularization and data generation processes.
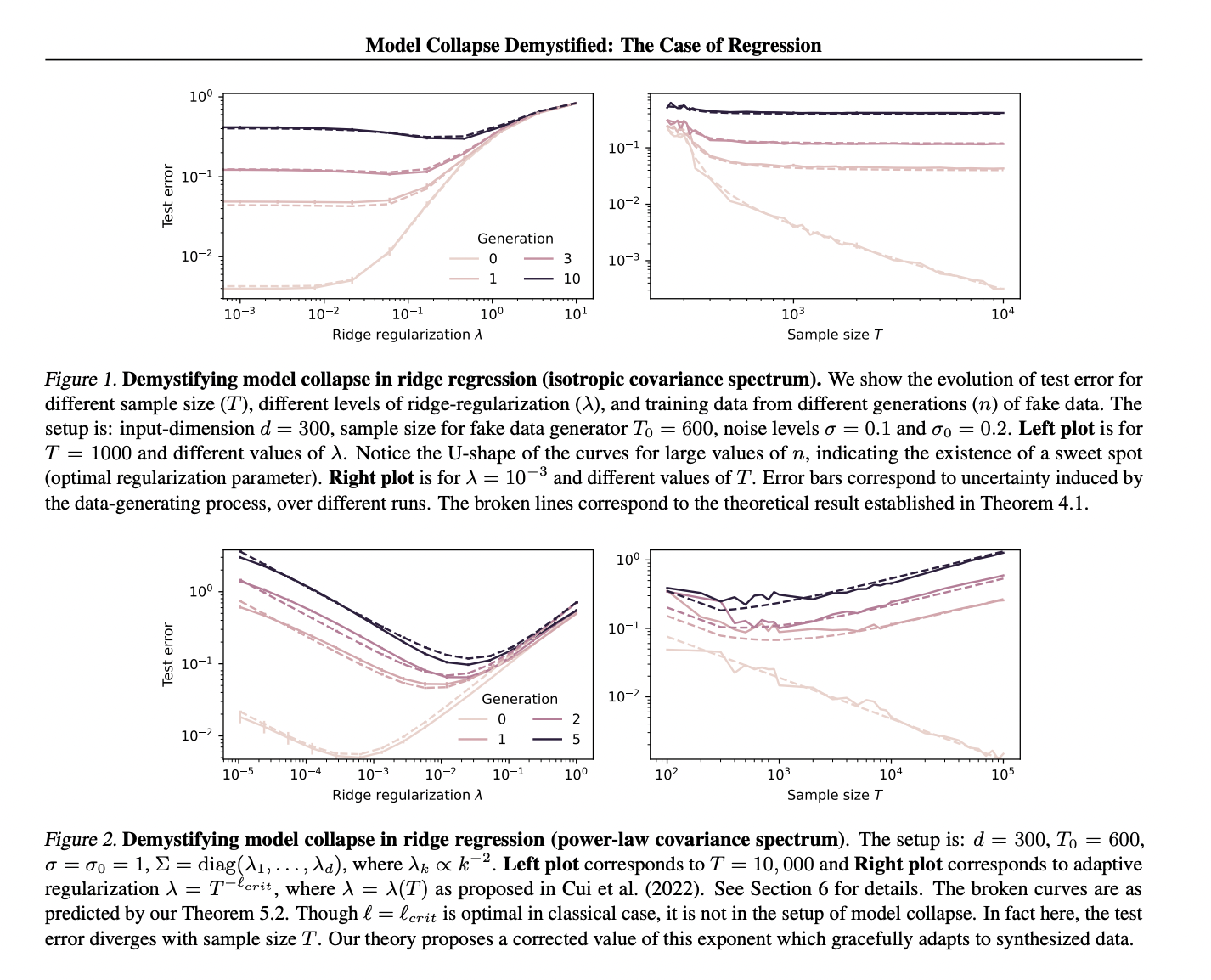
The results reveal that model collapse represents a modification of typical scaling laws when induced by fake data. For clearer presentation, the findings assume a condition where the initial sample size is greater than or equal to the dimensionality plus two. The study examines fake-data generation with multiple iterations, focusing on a ridge predictor based on a fake data sample. This predictor uses an adaptively tuned regularization parameter. The test error for this predictor follows a specific scaling law under certain mathematical limits. These results offer important insights into how models trained on fake data behave and perform, particularly in terms of their error rates and how these rates scale with different parameters.
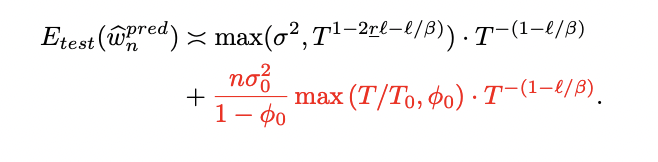
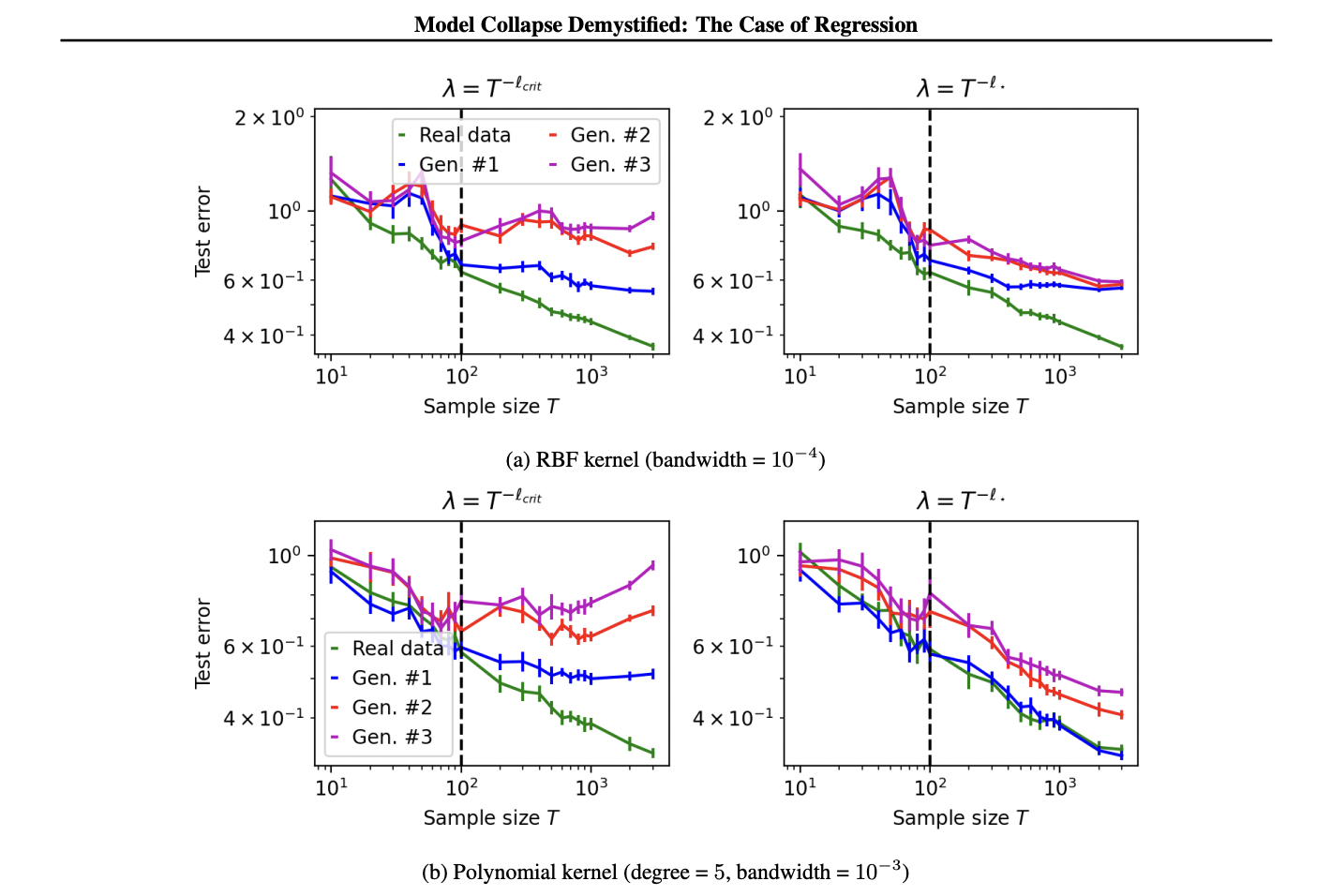
The study conducts experiments using both simulated and real data to empirically validate the theoretical results. For simulated data, ordinary linear ridge regression is performed in a 300-dimensional space, exploring different structures for the input covariance matrix. The fake data generator is constructed according to a specific process, and downstream ridge models are fitted for various sample sizes. Test sets consist of clean data pairs from the true distribution, with experiments repeated to generate error bars.
Real data experiments focus on kernel ridge regression using the MNIST dataset, a popular benchmark in machine learning. The classification problem is converted to regression by modifying labels with added noise. Fake training data is generated using kernel ridge regression with RBF and polynomial kernels. The researchers examine different sample sizes and fit downstream kernel ridge models. These experiments are also repeated multiple times to account for variations in label noise.
Results are presented through several figures, illustrating the model’s performance under different conditions, including isotropic and power-law settings, as well as over-parameterized scenarios. The findings from both simulated and real data experiments provide empirical support for the theoretical predictions made earlier in the study.
This study marks a significant shift in understanding test error rates as the world enters the “synthetic data age.” It provides analytical insights into the model collapse phenomenon, revealing it as a modification of usual scaling laws induced by synthetic training data. The findings suggest that the proliferation of AI-generated content could potentially hinder future learning processes, potentially increasing the value of non-AI-generated data. Practically, the research indicates that AI-generated data alters optimal regularization for downstream models, suggesting that models trained on mixed data may initially improve but later decline in performance. This necessitates a reevaluation of current training approaches in the era of synthetic data.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 52k+ ML SubReddit.
We are inviting startups, companies, and research institutions who are working on small language models to participate in this upcoming ‘Small Language Models’ Magazine/Report by Marketchpost.com. This Magazine/Report will be released in late October/early November 2024. Click here to set up a call!
The post Model Collapse in the Synthetic Data Era: Analytical Insights and Mitigation Strategies appeared first on MarkTechPost.
