


Text-to-image (T2I) models have seen rapid progress in recent years, allowing the generation of complex images based on natural language inputs. However, even state-of-the-art T2I models need help accurately capture and reflect all the semantics in given prompts, leading to images that may miss crucial details, such as multiple subjects or specific spatial relationships. For instance, generating a composition like “a cat with wings flying over a field of donuts” poses challenges and hurdles due to the inherent complexity and specificity of the prompt. As these models attempt to understand and replicate the nuances of text descriptions, their limitations become apparent. Moreover, enhancing these models is often hindered by the need for high-quality, large-scale annotated datasets, making it both resource-intensive and laborious. The result is a bottleneck in achieving models that can generate consistently faithful and semantically accurate images across diverse scenarios.
A key problem addressed by researchers is the need for help to create images that are truly faithful to complex textual descriptions. This misalignment often results in missing objects, incorrect spatial arrangements, or inconsistent rendering of multiple elements. For example, when asked to generate an image of a park scene featuring a bench, a bird, and a tree, T2I models might need to maintain the correct spatial relationships between these entities, leading to unrealistic images. Current solutions attempt to improve this faithfulness through supervised fine-tuning with annotated data or re-captioned text prompts. Although these methods show improvement, they rely heavily on the availability of extensive human-annotated data. This reliance introduces high training costs and complexity. Thus, there is a pressing need for a solution that can enhance image faithfulness without depending on manual data annotation, which is both costly and time-consuming.
Many existing solutions have attempted to address these challenges. One popular approach is supervised fine-tuning methods, where T2I models are trained using high-quality image-text pairs or manually curated datasets. Another line of research focuses on aligning T2I models with human preference data through reinforcement learning. This involves ranking and scoring images based on how well they match textual descriptions and using these scores to fine-tune the models further. Although these methods have shown promise in improving alignment, they depend on extensive manual annotations and high-quality data. Moreover, integrating additional components, such as bounding boxes or object layouts, to guide image generation has been explored. However, these techniques often require significant human effort and data curation, making them impractical at scale.
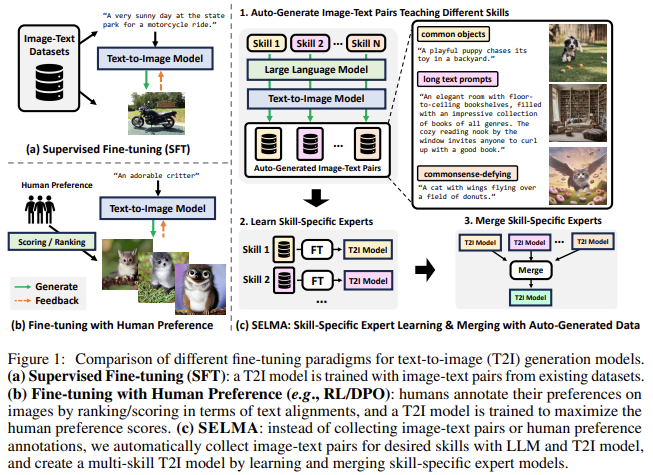
Researchers from the University of North Carolina at Chapel Hill have introduced SELMA: Skill-Specific Expert Learning and Merging with Auto-Generated Data. SELMA presents a novel approach to enhance T2I models without relying on human-annotated data. This method leverages the capabilities of Large Language Models (LLMs) to generate skill-specific text prompts automatically. The T2I models then use these prompts to produce corresponding images, creating a rich dataset without human intervention. The researchers employ a method known as Low-Rank Adaptation (LoRA) to fine-tune the T2I models on these skill-specific datasets, resulting in multiple skill-specific expert models. By merging these expert models, SELMA creates a unified multi-skill T2I model that can generate high-quality images with improved faithfulness and semantic alignment.
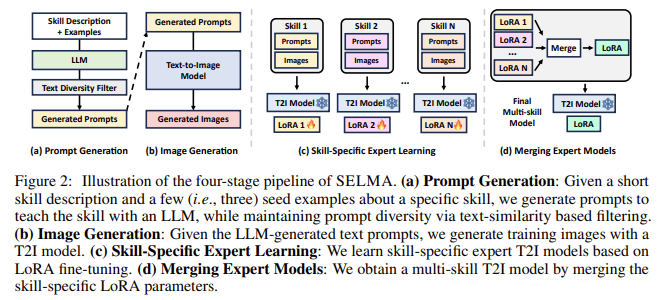
SELMA operates through a four-stage pipeline. First, skill-specific prompts are generated using LLMs, which helps ensure diversity in the dataset. The second stage involves generating corresponding images based on these prompts using T2I models. Next, the model is fine-tuned using LoRA modules to specialize in each skill. Finally, these skill-specific experts are merged to produce a robust T2I model capable of handling diverse prompts. This merging process effectively reduces knowledge conflicts between different skills, resulting in a model that can generate more accurate images than traditional multi-skill models. On average, SELMA showed a +2.1% improvement in the TIFA text-image alignment benchmark and a +6.9% enhancement in the DSG benchmark, indicating its effectiveness in improving faithfulness.
The performance of SELMA was validated against state-of-the-art T2I models, such as Stable Diffusion v1.4, v2, and XL. Empirical results demonstrated that SELMA improved text faithfulness and human preference metrics across multiple benchmarks, including PickScore, ImageReward, and Human Preference Score (HPS). For example, fine-tuning with SELMA improved HPS by 3.7 points and human preference metrics by 0.4 on PickScore and 0.39 on ImageReward. Notably, fine-tuning with auto-generated datasets performed comparable to fine-tuning with ground-truth data. The results suggest that SELMA is a cost-effective alternative without extensive manual annotation. The researchers found that fine-tuning a strong T2I model, such as SDXL, using images generated by a weaker model, such as SD v2, led to performance gains, suggesting the potential for weak-to-strong generalization in T2I models.
Key Takeaways from the SELMA Research:
- Performance Improvement: SELMA enhanced T2I models by +2.1% on TIFA and +6.9% on DSG benchmarks.Cost-Effective Data Generation: Auto-generated datasets achieved comparable performance to human-annotated datasets.Human Preference Metrics: Improved HPS by 3.7 points and increased PickScore and ImageReward by 0.4 and 0.39, respectively.Weak-to-Strong Generalization: Fine-tuning with images from a weaker model improved the performance of a stronger T2I model.Reduced Dependency on Human Annotation: SELMA demonstrated that high-quality T2I models could be developed without extensive manual data annotation.

In conclusion, SELMA offers a robust and efficient approach to enhance the faithfulness and semantic alignment of T2I models. By leveraging auto-generated data and a novel merging mechanism for skill-specific experts, SELMA eliminates the need for costly human-annotated data. This method addresses the key limitations of current T2I models and sets the stage for future advancements in text-to-image generation.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
The post SELMA: A Novel AI Approach to Enhance Text-to-Image Generation Models Using Auto-Generated Data and Skill-Specific Learning Techniques appeared first on MarkTechPost.
