


Machine Learning ML offers significant potential for accelerating the solution of partial differential equations (PDEs), a critical area in computational physics. The aim is to generate accurate PDE solutions faster than traditional numerical methods. While ML shows promise, concerns about reproducibility in ML-based science are growing. Issues like data leakage, weak baselines, and insufficient validation undermine performance claims in many fields, including medical ML. Despite these challenges, interest in using ML to improve or replace conventional PDE solvers continues, with potential benefits for optimization, inverse problems, and reducing computational time in various applications.
Princeton University researchers reviewed the machine learning ML literature for solving fluid-related PDEs and found overoptimistic claims. Their analysis revealed that 79% of studies compared ML models with weak baselines, leading to exaggerated performance results. Additionally, widespread reporting biases, including outcome and publication biases, further skewed findings by under-reporting negative results. Although ML-based PDE solvers, such as physics-informed neural networks (PINNs), have shown potential, they often fail regarding speed, accuracy, and stability. The study concludes that the current scientific literature does not provide a reliable evaluation of ML’s success in PDE solving.
Machine-learning-based solvers for PDEs often compare their performance against standard numerical methods, but many comparisons suffer from weak baselines, leading to exaggerated claims. Two major pitfalls include comparing methods with different accuracy levels and using less efficient numerical methods as baselines. In a review of 82 articles on ML for PDE solving, 79% compared weak baselines. Additionally, reporting biases were prevalent, with positive results often highlighted while negative outcomes were under-reported or concealed. These biases contribute to an overly optimistic view of the effectiveness of ML-based PDE solvers.
The analysis employs a systematic review methodology to investigate the frequency with which the ML literature in PDE solving compares its performance against weak baselines. The study specifically focuses on articles utilizing ML to derive approximate solutions for various fluid-related PDEs, including Navier–Stokes and Burgers’ equations. Inclusion criteria emphasize the necessity of quantitative speed or computational cost comparisons while excluding a range of non-fluid-related PDEs, qualitative comparisons without supporting evidence, and articles lacking relevant baselines. The search process involved compiling a comprehensive list of authors in the field and utilizing Google Scholar to identify pertinent publications from 2016 onwards, including 82 articles that met the defined criteria.
The study establishes essential conditions to ensure fair comparisons, such as comparing ML solvers with efficient numerical methods at equal accuracy or runtime. Recommendations are provided to enhance the reliability of comparisons, including cautious interpretation of results from specialized ML algorithms versus general-purpose numerical libraries and justification of hardware choices used in evaluations. The review thoroughly highlights the need to evaluate baselines in ML-for-PDE applications, noting the predominance of neural networks in the selected articles. Ultimately, the systematic review seeks to illuminate existing shortcomings in the current literature while encouraging future studies to adopt more rigorous comparative methodologies.
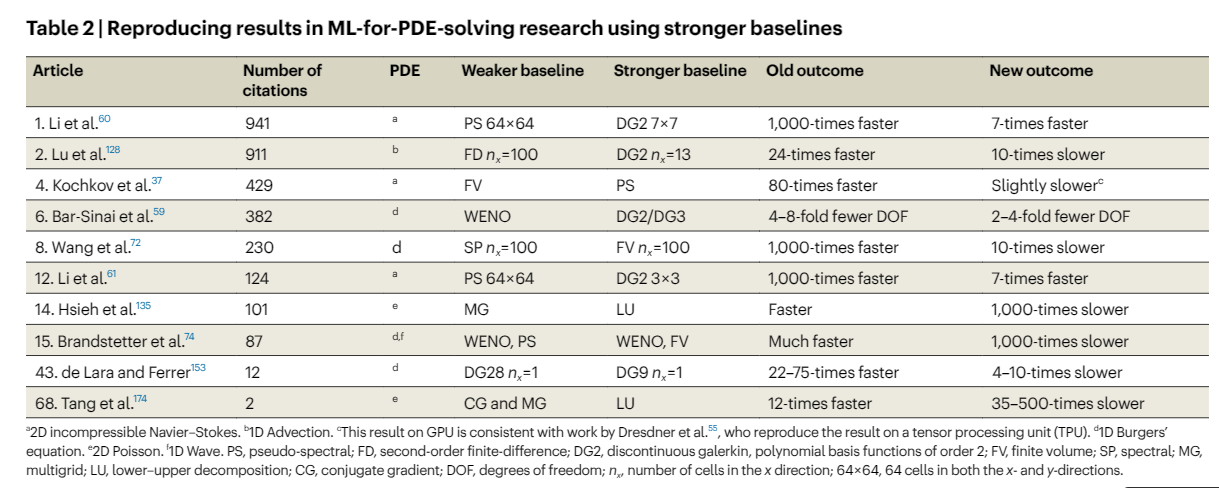
Weak baselines in machine learning for PDE solving often stem from a lack of ML community expertise, limited numerical analysis benchmarking, and insufficient awareness of the importance of strong baselines. To mitigate reproducibility issues, it is recommended that ML studies compare results against both standard numerical methods and other ML solvers. Researchers should also justify their choice of baselines and follow established rules for fair comparisons. Additionally, addressing biases in reporting and fostering a culture of transparency and accountability will enhance the reliability of ML research in PDE applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
The post Evaluating the Efficacy of Machine Learning in Solving Partial Differential Equations: Addressing Weak Baselines and Reporting Biases appeared first on MarkTechPost.
