


Small language models (SLMs) have become a focal point in natural language processing (NLP) due to their potential to bring high-quality machine intelligence to everyday devices. Unlike large language models (LLMs) that operate within cloud data centers and demand significant computational resources, SLMs aim to democratize artificial intelligence by making it accessible on smaller, resource-constrained devices such as smartphones, tablets, and wearables. These models typically range from 100 million to 5 billion parameters, a fraction of what LLMs use. Despite their smaller size, they are designed to perform complex language tasks efficiently, addressing the growing need for real-time, on-device intelligence. The research into SLMs is crucial, as it represents the future of accessible, efficient AI that can operate without reliance on extensive cloud infrastructure.
One of the critical challenges in modern NLP is optimizing AI models for devices with limited computational resources. LLMs, while powerful, are resource-intensive, often requiring hundreds of thousands of GPUs to operate effectively. This computational demand restricts their deployment to centralized data centers, limiting their ability to function on portable devices that require real-time responses. The development of SLMs addresses this problem by creating efficient models to run directly on the device while maintaining high performance across various language tasks. Researchers have recognized the importance of balancing performance with efficiency, aiming to create models that require fewer resources but still perform tasks like commonsense reasoning, in-context learning, and mathematical problem-solving.
Researchers have explored methods to reduce the complexity of large models without compromising their ability to perform well on key tasks. Methods like model pruning, knowledge distillation, and quantization have been commonly used. Pruning removes less important neurons from a model to reduce its size and computational load. Knowledge distillation transfers knowledge from a larger model to a smaller one, allowing the smaller model to replicate the behavior of its larger counterpart. Quantization reduces the precision of calculations, which helps in speeding up the model and lowering its memory usage. Also, innovations like parameter sharing and layer-wise scaling have further optimized models to perform well on devices like smartphones and tablets. While these methods have helped improve the efficiency of SLMs, they are often not enough to achieve the same level of performance as LLMs without further refinement.
The research from the Beijing University of Posts and Telecommunications (BUPT), Peng Cheng Laboratory, Helixon Research, and the University of Cambridge introduces new architectural designs aimed at advancing SLMs. Their work focuses on transformer-based, decoder-only models, allowing more efficient on-device processing. To minimize computational demands, they introduced innovations such as multi-query attention mechanisms and gated feed-forward neural networks (FFNs). For instance, multi-query attention reduces the memory overhead typically associated with the attention mechanism in transformer models. At the same time, the gated FFN structure allows the model to route information through the network, improving efficiency dynamically. These advancements enable smaller models to perform tasks effectively, from language comprehension to reasoning and problem-solving, while consuming fewer computational resources.
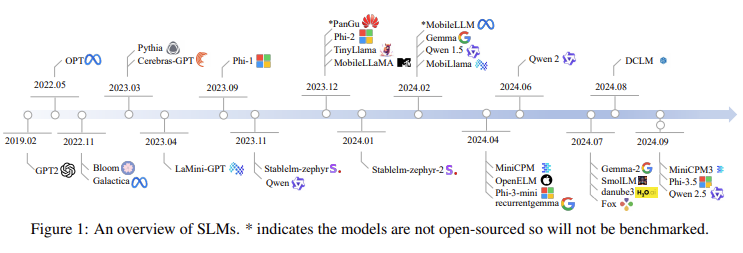
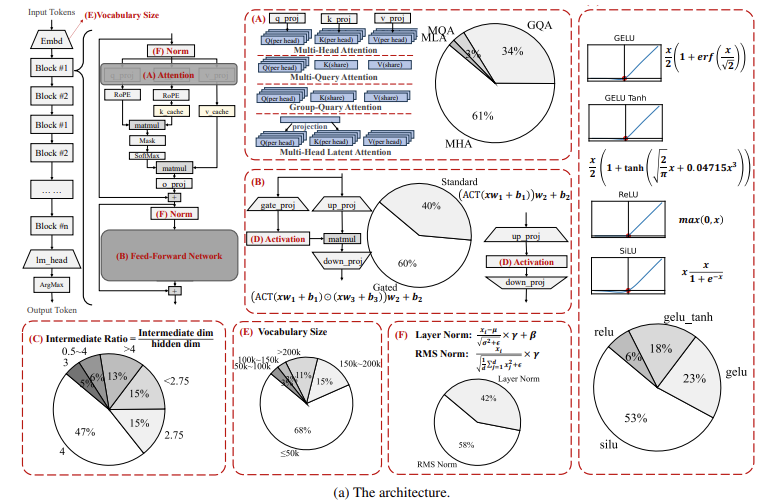
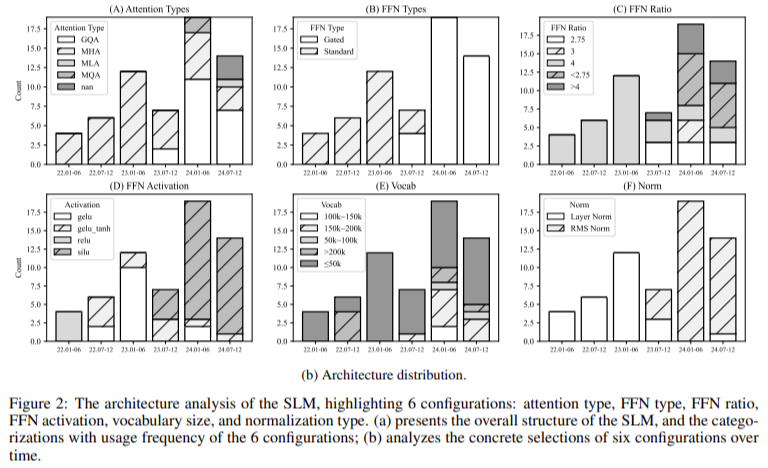
The architecture proposed by the researchers revolves around optimizing memory usage and processing speed. The introduction of group-query attention allows the model to reduce the number of query groups while preserving attention diversity. This mechanism has proven particularly effective in reducing memory usage. They use SiLU (Sigmoid Linear Unit) as the activation function, showing marked improvements in handling language tasks compared to more conventional functions like ReLU. Also, the researchers introduced nonlinearity compensation to address common issues with small models, such as the feature collapse problem, which impairs a model’s ability to process complex data. This compensation is achieved by integrating advanced mathematical shortcuts into the transformer architecture, ensuring the model remains robust even when scaled down. Moreover, parameter-sharing techniques were implemented, which allow the model to reuse weights across different layers, further reducing memory consumption and improving inference times, making it suitable for devices with limited computational capacity.
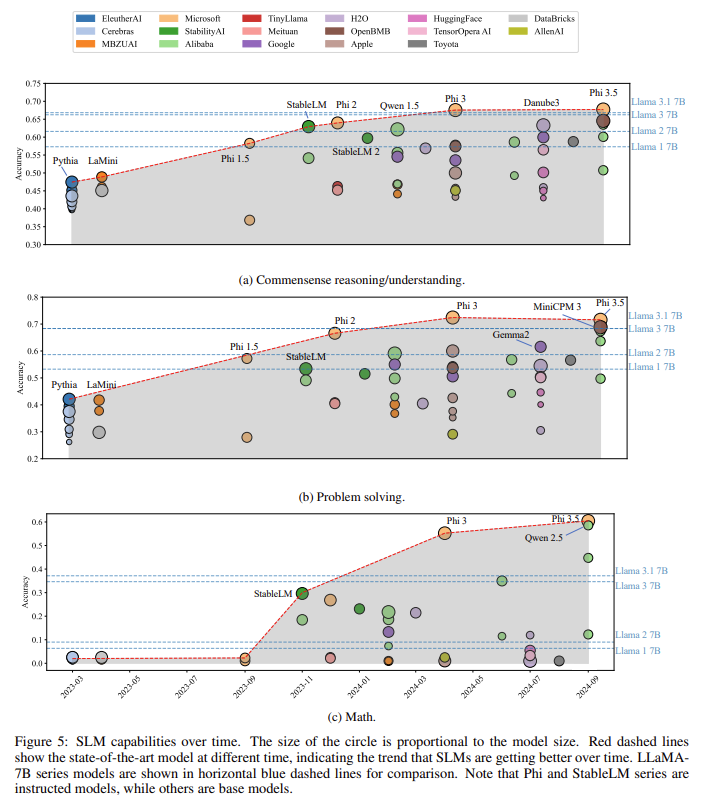
The results of this study demonstrate substantial improvements in both performance and efficiency. One of the standout models, Phi-3 mini, achieved a 14.5% higher accuracy in mathematical reasoning tasks than the state-of-the-art LLaMA 3.1, a large language model with 7 billion parameters. Furthermore, in commonsense reasoning tasks, the Phi family of models outperformed several leading models, including LLaMA, by achieving a 67.6% accuracy score. Similarly, the Phi-3 model posted an accuracy of 72.4% in problem-solving tasks, placing it among the top-performing SLMs. These results highlight the success of the new architecture in maintaining high performance while reducing the computational demands typically associated with larger models. The research also showed that these models are efficient and scalable, offering consistent performance across various tasks, from simple reasoning to more complex mathematical problems.
Regarding deployment, the models were tested on various edge devices, including the Jetson Orin NX and high-end smartphones. The models demonstrated significant reductions in both inference latency and memory usage. For example, the Qwen-2 1.5B model reduced inference latency by over 50%, making it one of the most efficient models tested. Memory usage was notably optimized in models like the OpenELM-3B, which used up to 30% less memory than other models with a similar parameter count. These results are promising for the future of SLMs, as they demonstrate that achieving high performance on resource-constrained devices is possible, opening the door for real-time AI applications on mobile and wearable technologies.
Key takeaways from the research can be summarized as follows:
- Group-query attention and gated feed-forward networks (FFNs): These innovations significantly reduce memory usage and processing time without sacrificing performance. Group-query attention reduces the number of queries without losing attention diversity, making the model more efficient.High-quality pre-training datasets: The research underscores the importance of high-quality, open-source datasets, such as FineWeb-Edu and DCLM. The data quality often outweighs the quantity, allowing for better generalization and reasoning capabilities.Parameter sharing and nonlinearity compensation: These techniques play a crucial role in improving the runtime performance of the models. Parameter sharing reduces the redundancy in the model layers, while nonlinearity compensation addresses the feature collapse issue, ensuring the model remains robust in real-time applications.Model scalability: Despite their smaller size, the Phi family of models consistently outperformed larger models like LLaMA in tasks requiring mathematical reasoning and commonsense understanding, proving that SLMs can rival LLMs when designed correctly.Efficient edge deployment: The significant reduction in latency and memory usage demonstrates that these models are well-suited for deployment on resource-constrained devices like smartphones and tablets. Models like the Qwen-2 1.5B achieved over 50% latency reduction, confirming their practical applications in real-time scenarios.Architecture innovations with real-world impact: The introduction of techniques such as group-query attention, gated FFNs, and parameter sharing proves that innovations at the architectural level can yield substantial performance improvements without increasing computational costs, making these models practical for widespread adoption in everyday technology.
In conclusion, the research into small language models offers a path forward for creating highly efficient AI that can operate on various devices without reliance on cloud-based infrastructure. The problem of balancing performance with computational efficiency has been addressed through innovative architectural designs such as group-query attention and gated FFNs, which enable SLMs to deliver results comparable to those of LLMs despite having a fraction of the parameters. The research shows that with the right dataset, architecture, and deployment strategies, SLMs can be scaled to handle various tasks, from reasoning to problem-solving, while running efficiently on resource-constrained devices. This represents a significant advancement in making AI more accessible and functional for real-world applications, ensuring that the benefits of machine intelligence can reach users across different platforms.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 52k+ ML SubReddit
The post A Comprehensive Survey of Small Language Models: Architectures, Datasets, and Training Algorithms appeared first on MarkTechPost.
