


The demand for customizable, open models that can run efficiently on various hardware platforms has grown, and Meta is at the forefront of catering to this demand. Meta open-sourced the release of Llama 3.2, featuring small and medium-sized vision LLMs (11B and 90B), along with lightweight, text-only models (1B and 3B) designed for edge and mobile devices, available in both pre-trained and instruction-tuned versions. Llama 3.2 addresses these needs with a suite of both lightweight and robust models, which have been optimized for various tasks, including text-only and vision-based applications. These models are specially designed for edge devices, making AI more accessible to developers and enterprises.
Model Variants Released
The Llama 3.2 released two categories of models in this iteration of the Llama Series:
- Vision LLMs (11B and 90B): These are the largest models for complex image reasoning tasks such as document-level understanding, visual grounding, and image captioning. They are competitive with other closed models in the market and surpass them in various image understanding benchmarks.Lightweight Text-only LLMs (1B and 3B): These smaller models are designed for edge AI applications. They provide robust performance for summarization, instruction following, and prompt rewriting tasks while maintaining a low computational footprint. The models also have a token context length of 128,000, significantly improving over previous versions.
Both pre-trained and instruction-tuned versions of these models are available, with support from Qualcomm, MediaTek, and Arm, ensuring that developers can deploy these models directly on mobile and edge devices. The models have been made available for immediate download and use via llama.com, Hugging Face, and partner platforms like AMD, AWS, Google Cloud, and Dell.
Technical Advancements and Ecosystem Support
One of the most notable improvements in Llama 3.2 is the introduction of adapter-based architecture for vision models, where image encoders are integrated with pre-trained text models. This architecture allows for deep image and text data reasoning, significantly expanding the use cases for these models. The pre-trained models underwent extensive fine-tuning, including training on large-scale noisy image-text pair data and post-training on high-quality, in-domain datasets.
Llama 3.2’s robust ecosystem support is another critical factor in its revolutionary potential. With partnerships across leading tech companies, AWS, Databricks, Dell, Microsoft Azure, NVIDIA, and others, Llama 3.2 has been optimized for both on-premise and cloud environments. Also, Llama Stack distributions simplify deployment for developers, offering turnkey solutions for edge, cloud, and on-device environments. The distributions, such as PyTorch ExecuTorch for on-device deployments and Ollama for single-node setups, further solidify the versatility of these models.
Performance Metrics
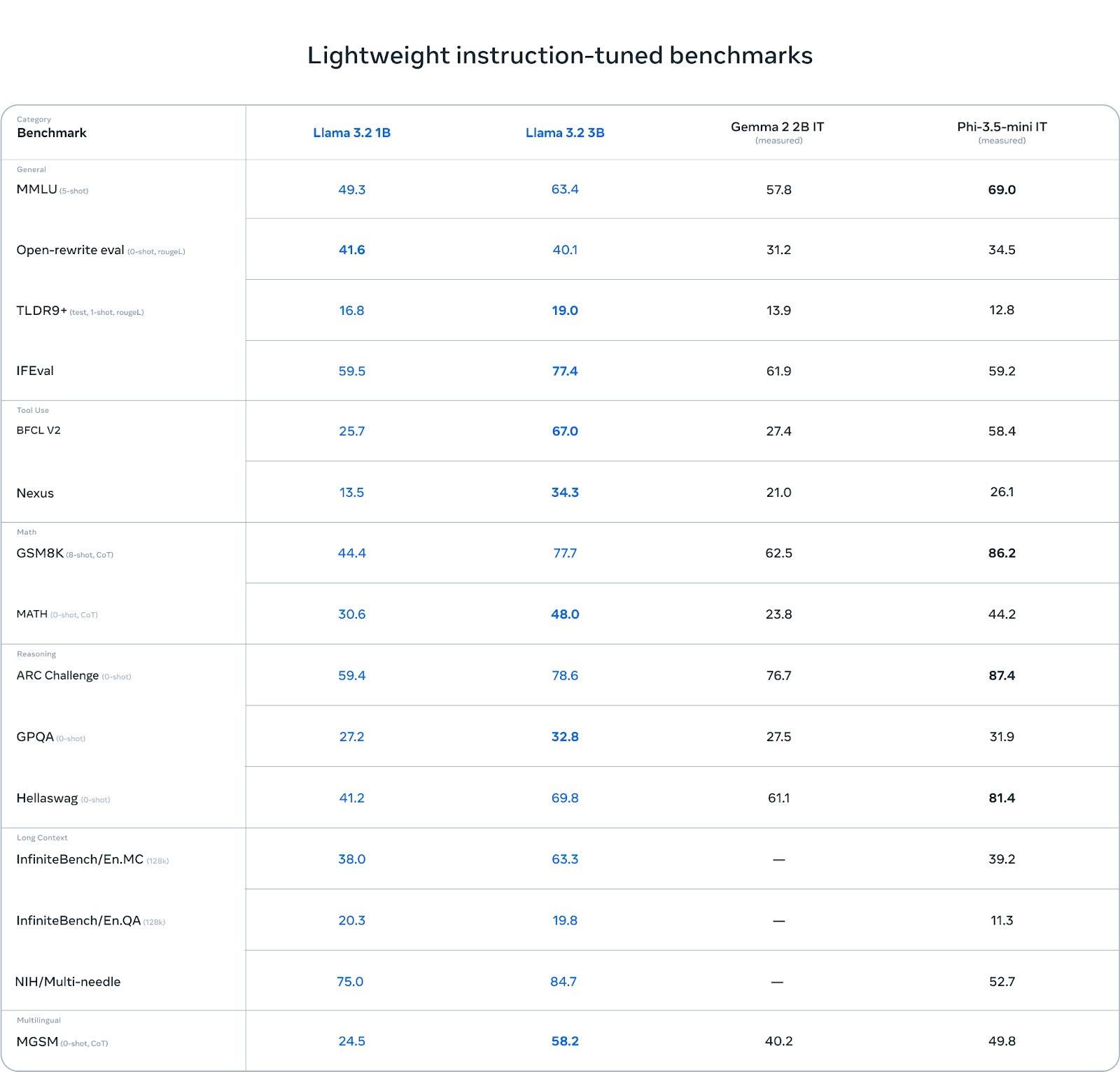
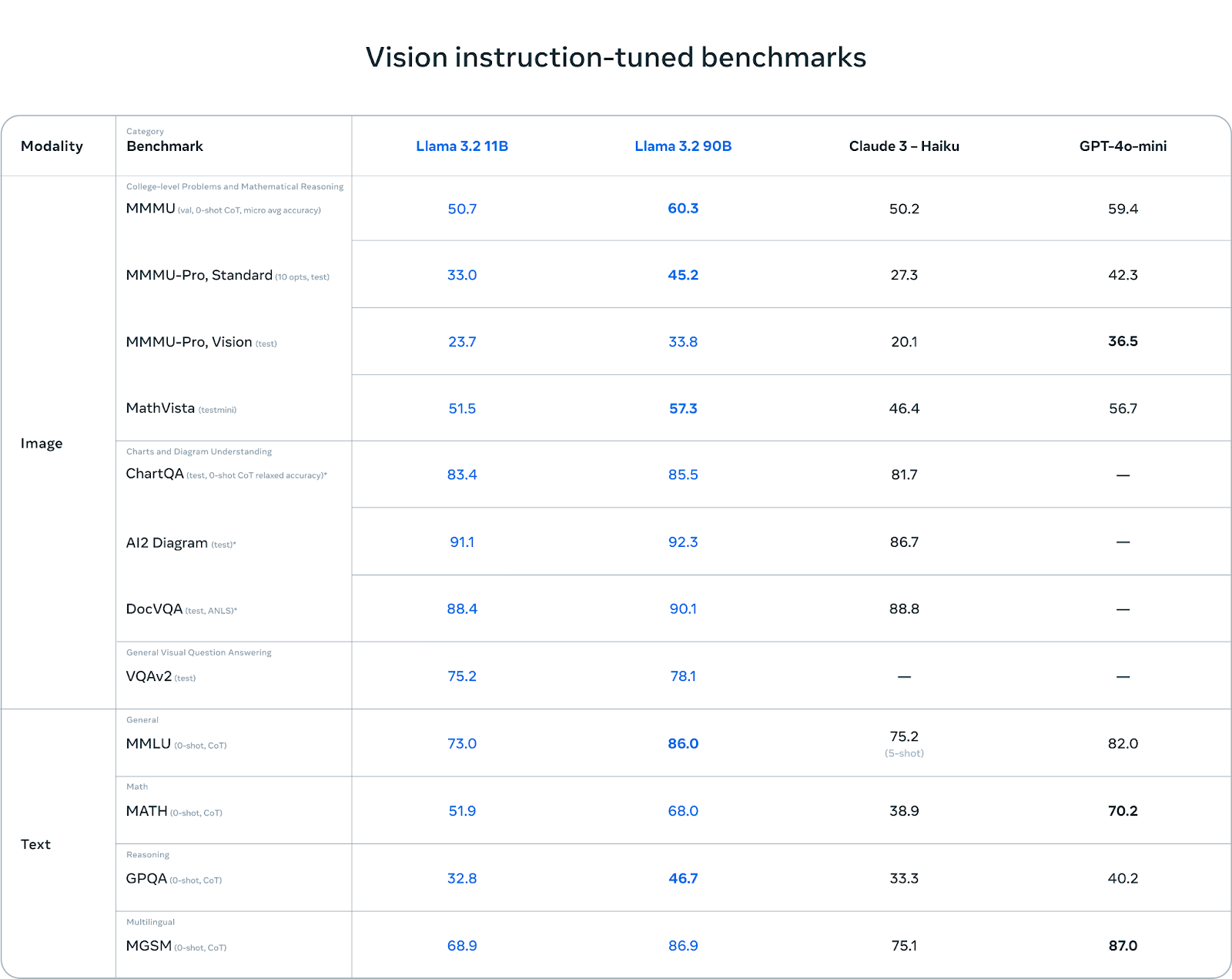
Llama 3.2’s variants deliver impressive performance across both text and vision tasks. The lightweight 1B and 3B text-only models, optimized for edge and mobile devices, excel in summarization, instruction following, and prompt rewriting while maintaining a token context length of 128K. These models outperform competitors like Gemma 2.6B and Phi 3.5-mini in several benchmarks. On the vision side, the 11B and 90B models demonstrate superior capabilities in image understanding, reasoning, and visual grounding tasks, outperforming closed models like Claude 3 Haiku and GPT4o-mini on key benchmarks. These models efficiently bridge text and image reasoning, making them ideal for multimodal applications.
The Power of Lightweight Models
The introduction of lightweight models in Llama 3.2, especially the 1B and 3B variants, is crucial for edge computing and privacy-sensitive applications. Running locally on mobile devices ensures that the data remains on the device, enhancing user privacy by avoiding cloud-based processing. This is particularly beneficial in scenarios such as summarizing personal messages or generating action items from meetings without sending sensitive information to external servers. Meta employed pruning and knowledge distillation techniques to achieve small model sizes while retaining high performance. The 1B and 3B models were pruned from larger Llama 3.1 models, using structured pruning to remove less important parameters without sacrificing the overall model quality. Knowledge distillation was used to impart knowledge from larger models, further improving the performance of these lightweight models.
Llama 3.2 Vision: Powering Image Reasoning with 11B and 90B Models
The 11B and 90B vision LLMs in Llama 3.2 are built for advanced image reasoning and understanding tasks, introducing an entirely new model architecture seamlessly integrating image and text capabilities. These models can handle document-level comprehension, image captioning, and visual grounding tasks. For instance, the 11B and 90B models can analyze business charts to determine the best sales month or navigate complex visual data such as maps to provide insights into terrain or distances. The cross-attention mechanism, developed by integrating a pre-trained image encoder with the language model, allows these models to excel at extracting details from images and creating meaningful, coherent captions that bridge the gap between text and visual data. This architecture makes the 11B and 90B models competitive with closed models such as Claude 3 Haiku and GPT4o-mini in visual reasoning benchmarks, surpassing them in tasks requiring deep multimodal understanding. They have been optimized for fine-tuning and custom application deployments using open-source tools like torchtune and torchchat.
Key Takeaways from the Llama 3.2 release:
- New Model Introductions: Llama 3.2 introduces two new categories of models: the 1B and 3B lightweight, text-only models and the 11B and 90B vision multimodal models. The 1B and 3B models, designed for edge and mobile device use, leverage 9 trillion tokens for training, providing state-of-the-art performance for summarization, instruction following, and rewriting tasks. These smaller models are ideal for on-device applications due to their lower computational demands. Meanwhile, the larger 11B and 90B vision models bring multimodal capabilities to the Llama suite, excelling at complex image and text understanding tasks and setting them apart from previous versions.Enhanced Context Length: One of the significant advancements in Llama 3.2 is the support for a 128K context length, particularly in the 1B and 3B models. This extended context length allows for more extensive input to be processed simultaneously, improving tasks requiring long document analysis, such as summarization and document-level reasoning. It also enables these models to handle large amounts of data efficiently.Knowledge Distillation for Lightweight Models: The 1B and 3B models in Llama 3.2 benefit from a distillation process from larger models, specifically the 8B and 70B variants from Llama 3.1. This distillation process transfers knowledge from larger models to the smaller ones, enabling the lightweight models to achieve competitive performance with significantly reduced computational overhead, making them highly suitable for resource-constrained environments.Vision Models Trained on Massive Data: The vision language models (VLMs), the 11B and 90B, were trained on a massive dataset of 6 billion image-text pairs, equipping them with robust multimodal capabilities. These models integrate a CLIP-type MLP with GeLU activation for the vision encoder, differing from Llama 3’s MLP architecture, which uses SwiGLU. This design choice enhances their ability to handle complex visual understanding tasks, making them highly effective for image reasoning and multimodal interaction.Advanced Vision Architecture: The vision models in Llama 3.2 incorporate advanced architectural features such as normal layer norm for the vision encoder rather than the RMS Layernorm seen in other models and include a gating multiplier applied to hidden states. This gating mechanism uses a tanh activation function to scale the vector from -1 to 1, helping fine-tune the vision models’ outputs. These architectural innovations contribute to improved accuracy and efficiency in visual reasoning tasks.Performance Metrics: The evaluations for Llama 3.2’s models show promising results. The 1B model achieved a 49.3 score on the MMLU, while the 3B model scored 63.4. The 11B vision multimodal model scored 50.7 on the MMMU, while the 90B model scored 60.3 on the vision side. These metrics highlight the competitive edge of Llama 3.2’s models in text-based and vision tasks, especially compared to other leading models.Integration with UnslothAI for Speed and Efficiency: The 1B and 3B models are fully integrated with UnslothAI, enabling 2x faster finetuning, 2x faster inference, and 70% less VRAM usage. This integration further enhances the usability of these models in real-time applications. Work is underway to integrate the 11B and 90B VLMs into the UnslothAI framework, extending these speed and efficiency benefits to the larger multimodal models.
These advancements make Llama 3.2 a versatile, powerful suite of models suited for a wide range of applications, from lightweight, on-device AI solutions to more complex multimodal tasks requiring large-scale image and text understanding.
Conclusion
The release of Llama 3.2 represents a significant milestone in the evolution of edge AI and vision models. Its open and customizable architecture, robust ecosystem support, and lightweight, privacy-centric models offer a compelling solution for developers and enterprises looking to integrate AI into their edge and on-device applications. The availability of small and large models ensures that users can select the variant best suited to their computational resources and use cases.
Check out the Models on Hugging Face and Details. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
The post Llama 3.2 Released: Unlocking AI Potential with 1B and 3B Lightweight Text Models and 11B and 90B Vision Models for Edge, Mobile, and Multimodal AI Applications appeared first on MarkTechPost.
