
Published on September 25, 2024 9:31 AM GMT
This research was completed for London AI Safety Research (LASR) Labs 2024. The team was supervised by Joseph Bloom (Decode Research). Find out more about the programme and express interest in upcoming iterations here.
This high level summary will be most accessible to those with relevant context including an understanding of SAEs. The importance of this work rests in part on the surrounding hype, and potential philosophical issues. We encourage readers seeking technical details to read the paper on arxiv.
TLDR: This is a short post summarising the key ideas and implications of our recent work studying how character information represented in language models is extracted by SAEs. Our most important result shows that SAE latents can appear to classify some feature of the input, but actually turn out to be quite unreliable classifiers (much worse than linear probes). We think this unreliability is in part due to difference between what we want actually want (an "interpretable decomposition") and what we train against (sparsity + reconstruction). We think there are many possibly productive follow-up investigations.
We pose two questions:
- To what extent do Sparse Autoencoders (SAEs) extract interpretable latents from LLMs? The success of SAE applications (such as detecting safety-relevant features or efficiently describing circuits) will rely on whether SAE latents are reliable classifiers and provide an interpretable decomposition. How does varying the hyperparameters of the SAE affect its interpretability? Much time and effort is being invested in iterating on SAE training methods, can we provide a guiding signal for these endeavours?
To answer these questions, we tested SAE performance on a simple first letter identification task using over 200 Gemma Scope SAEs. By focussing on a task with ground truth labels we precisely measured the precision and recall of SAE latents tracking first letter information.
Our results revealed a novel obstacle to using SAEs for interpretability which we term 'Feature Absorption'. This phenomenon is a pernicious, asymmetric form of feature splitting where:
- An SAE latent appears to track a human-interpretable concept (such as “starts with E”). That SAE latent fails to activate on seemingly arbitrary examples (eg “Elephant”).
We find “absorbing” latents which weakly project onto the feature direction and causally mediate in-place of the main latent (eg: an "elephants" latent absorbs the "starts with E" feature direction, and then the SAE no longer fires the "starts with E" latent on the token "Elephant", as the "elephants" latent now encodes that information, along with other semantic elephant-related features).
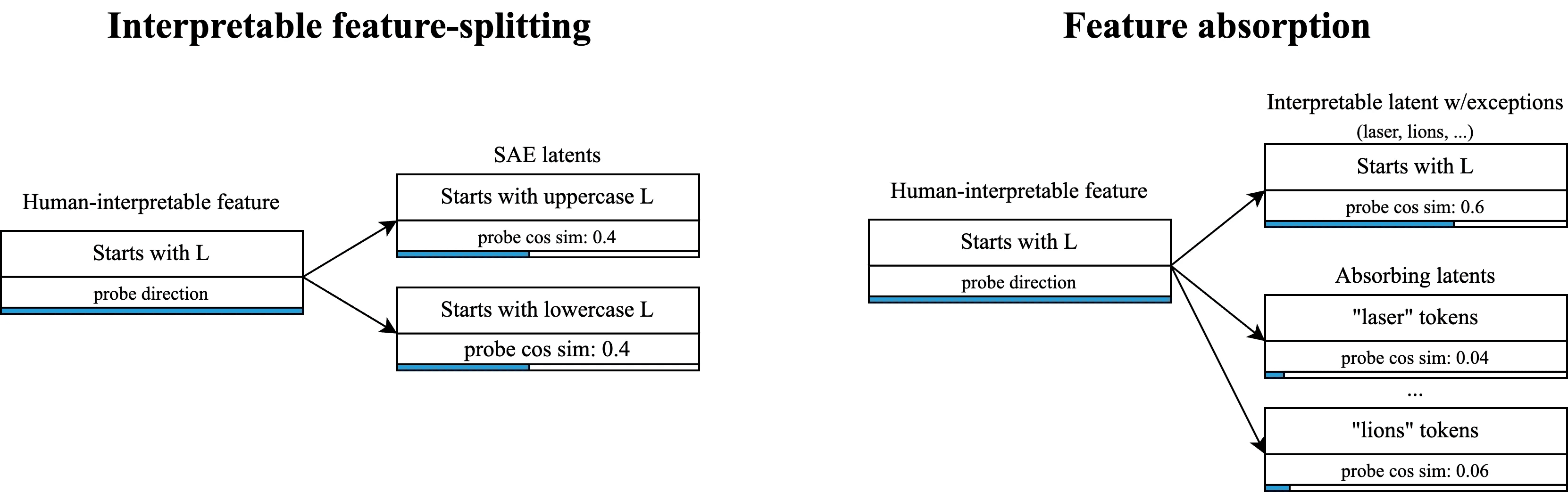
Feature splitting vs feature absorption:
In the traditional (interpretable) view of feature splitting, a single general latent in a narrow SAE splits into multiple more specific latents in a wider SAE[1]. For instance, we may find that a "starts with L" latent splits into "starts with uppercase L" and "starts with lowercase L". This is not a problem for interpretability as all these latents are just different valid decompositions of the same concept, and may even be a desirable way to tune latent specificity.
In feature absorption, an interpretable feature becomes a latent which appears to track that feature, but fails to fire on arbitrary tokens that it seemingly should fire on. Instead, roughly token-aligned latents "absorb" the feature direction and fire in-place of the mainline latent. Feature absorption strictly reduces interpretability and makes it difficult to trust that SAE latents do what they appear to do.
Feature Absorption is problematic:
- Feature absorption explains why feature circuits can’t be sparse (yet). We want to describe circuits with as few features as possible, however feature absorption suggests SAEs may not give us a decomposition with a sparse set of causal mediators. Hyperparameter tuning is unlikely to remove absorption entirely. While the rate of absorption varies with the size and sparsity of an SAEs, our experiments suggest absorption is likely robust to tuning. (One issue is that tuning may need to be done for each feature individually). Feature absorption may be a pathological strategy for satisfying the sparsity objective. Where dense and sparse features co-occur, feature absorption is a clear strategy for reducing the number of features firing. Thus in the case of feature co-occurrence, sparsity may lead to less interpretability.
While our study has clear limitations, we think there’s compelling evidence for the existence of feature absorption. It’s important to note that our results use a leverage model (Gemma-2-2b), one SAE architecture (JumpReLU) and one task (the first letter identification task). However, the qualitative results are striking (which readers can explore for themselves using our streamlit app) and causal interventions are built directly into our metric for feature absorption.
We’re excited about future work in a number of areas (in order of concrete / import to most exciting!):
- Validating feature absorption.
- Is it reduced in different SAE architectures? (We think likely no). Does it appear for other kinds of features? (We think likely yes).
- We think Meta-SAEs may be a part of the answer.We’re also excited about fine tuning against attribution sparsity with task relevant metrics/datasets.
We believe our work provides a significant contribution by identifying and characterising the feature absorption phenomenon, highlighting a critical challenge in the pursuit of interpretable AI systems.
Discuss
