


In artificial intelligence and natural language processing, long-context reasoning has emerged as a crucial area of research. As the volume of information that needs to be processed grows, machines must be able to synthesize and extract relevant data from massive datasets efficiently. This goes beyond simple retrieval tasks, requiring models to locate specific pieces of information and understand complex relationships within vast contexts. The ability to reason over these long contexts is essential for functions like document summarization, code generation, and large-scale data analysis, all of which are central to advancements in AI.
A key challenge researchers face is the need for more effective tools to evaluate long-context understanding in large language models. Most existing methods focus on retrieval, where the task is limited to finding a single piece of information in a vast context, akin to finding a needle in a haystack. However, retrieval alone does not fully test a model’s ability to comprehend and synthesize information from large datasets. As the data complexity grows, measuring how well models can process and connect scattered pieces of information is critical rather than relying on simple retrieval.
Current approaches are inadequate because they often measure isolated retrieval capabilities rather than the more complex skill of synthesizing relevant information from a large, continuous data stream. A popular method, called the needle-in-a-haystack task, evaluates how well models can find a specific piece of data. However, this approach does not test the model’s ability to understand and process multiple related data points, leading to limitations in evaluating their true long-context reasoning potential. While providing some insight into these models’ abilities, recent benchmarks have been criticized for their limited scope and inability to measure deep reasoning over large contexts.
Researchers at Google DeepMind and Google Research have introduced a new evaluation method called Michelangelo. This innovative framework tests long-context reasoning in models using synthetic, un-leaked data, ensuring that evaluations are both challenging and relevant. The Michelangelo framework focuses on long-context understanding through a system called Latent Structure Queries (LSQ), which allows the model to reveal hidden structures within a large context by discarding irrelevant information. The researchers aim to evaluate how well models can synthesize information from scattered data points across a lengthy dataset rather than merely retrieve isolated details. Michelangelo introduces a new test set that significantly improves the traditional needle-in-a-haystack retrieval approach.
The Michelangelo framework comprises three primary tasks: Latent List, Multi-Round Coreference Resolution (MRCR), and the IDK task. The Latent List task involves presenting a sequence of Python operations to the model, requiring it to track changes to a list and determine specific outcomes such as sums, minimums, or lengths after multiple list modifications. This task is designed with increasing complexity, from simple one-step operations to sequences involving up to 20 relevant modifications. MRCR, on the other hand, challenges models to handle complex conversations by reproducing key pieces of information embedded within a long dialogue. The IDK task tests the model’s ability to identify when it does not have enough information to answer a question. Ensuring models do not produce inaccurate results based on incomplete data is crucial.
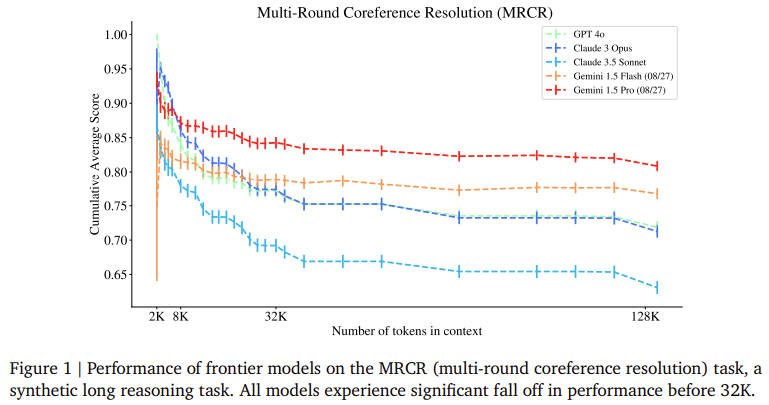
In terms of performance, the Michelangelo framework provides detailed insights into how well current frontier models handle long-context reasoning. Evaluations across models such as GPT-4, Claude 3, and Gemini reveal notable differences. For example, all models experienced a significant accuracy drop when dealing with tasks involving more than 32,000 tokens. At this threshold, models like GPT-4 and Claude 3 showed steep declines, with cumulative average scores dropping from 0.95 to 0.80 for GPT-4 on the MRCR task as the number of tokens increased from 8K to 128K. Claude 3.5 Sonnet showed similar performance, decreasing scores from 0.85 to 0.70 across the same token range. Interestingly, Gemini models performed better in longer contexts, with the Gemini 1.5 Pro model achieving non-decreasing performance up to 1 million tokens in both MRCR and Latent List tasks, outperforming other models by maintaining a cumulative score above 0.80.

In conclusion, the Michelangelo framework provides a much-needed improvement in evaluating long-context reasoning in large language models. By shifting focus from simple retrieval to more complex reasoning tasks, this framework challenges models to perform at a higher level, synthesizing information across vast datasets. This evaluation shows that while current models, such as GPT-4 and Claude 3, struggle with long-context tasks, models like Gemini demonstrate potential for maintaining performance even with extensive data. The research team’s introduction of the Latent Structure Queries framework and the detailed tasks within Michelangelo push the boundaries of measuring long-context understanding and highlight the challenges and opportunities in advancing AI reasoning capabilities.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit

The post Michelangelo: An Artificial Intelligence Framework for Evaluating Long-Context Reasoning in Large Language Models Beyond Simple Retrieval Tasks appeared first on MarkTechPost.
