


Large language models (LLMs) have made significant leaps in natural language processing, demonstrating remarkable generalization capabilities across diverse tasks. However, due to inconsistent adherence to instructions, these models face a critical challenge in generating accurately formatted outputs, such as JSON. This limitation poses a significant hurdle for AI-driven applications requiring structured LLM outputs integrated into their data streams. As the demand for controlled and structured outputs from LLMs grows, researchers are confronted with the urgent need to develop methods that can ensure precise formatting while maintaining the models’ powerful language generation abilities.
Researchers have explored various approaches to mitigate the challenge of format-constrained generation in LLMs. These methods can be categorized into three main groups: pre-generation tuning, in-generation control, and post-generation parsing. Pre-generation tuning involves modifying training data or prompts to align with specific format constraints. In-generation control methods intervene during the decoding process, using techniques like JSON Schema, regular expressions, or context-free grammars to ensure format compliance. However, these methods often compromise response quality. Post-generation parsing techniques refine the raw output into structured formats using post-processing algorithms. While each approach offers unique advantages, they all face limitations in balancing format accuracy with response quality and generalization capabilities.
Researchers from the Beijing Academy of Artificial Intelligence, AstralForge AI Lab, Institute of Computing Technology, Chinese Academy of Sciences, University of Electronic Science and Technology of China, Harbin Institute of Technology, College of Computing and Data Science, Nanyang Technological University have proposed Sketch, an innovative toolkit designed to enhance the operation of LLMs and ensure formatted output generation. This framework introduces a collection of task description schemas for various NLP tasks, allowing users to define their specific requirements, including task objectives, labeling systems, and output format specifications. Sketch enables out-of-the-box deployment of LLMs for unfamiliar tasks while maintaining output format correctness and conformity.
The framework’s key contributions include:
- simplifying LLM operation through predefined schemasoptimizing performance via dataset creation and model fine-tuning based on LLaMA3-8B-Instructintegrating constrained decoding frameworks for precise output format control.
These advancements enhance the reliability and precision of LLM outputs, making Sketch a versatile solution for diverse NLP applications in both research and industrial settings.
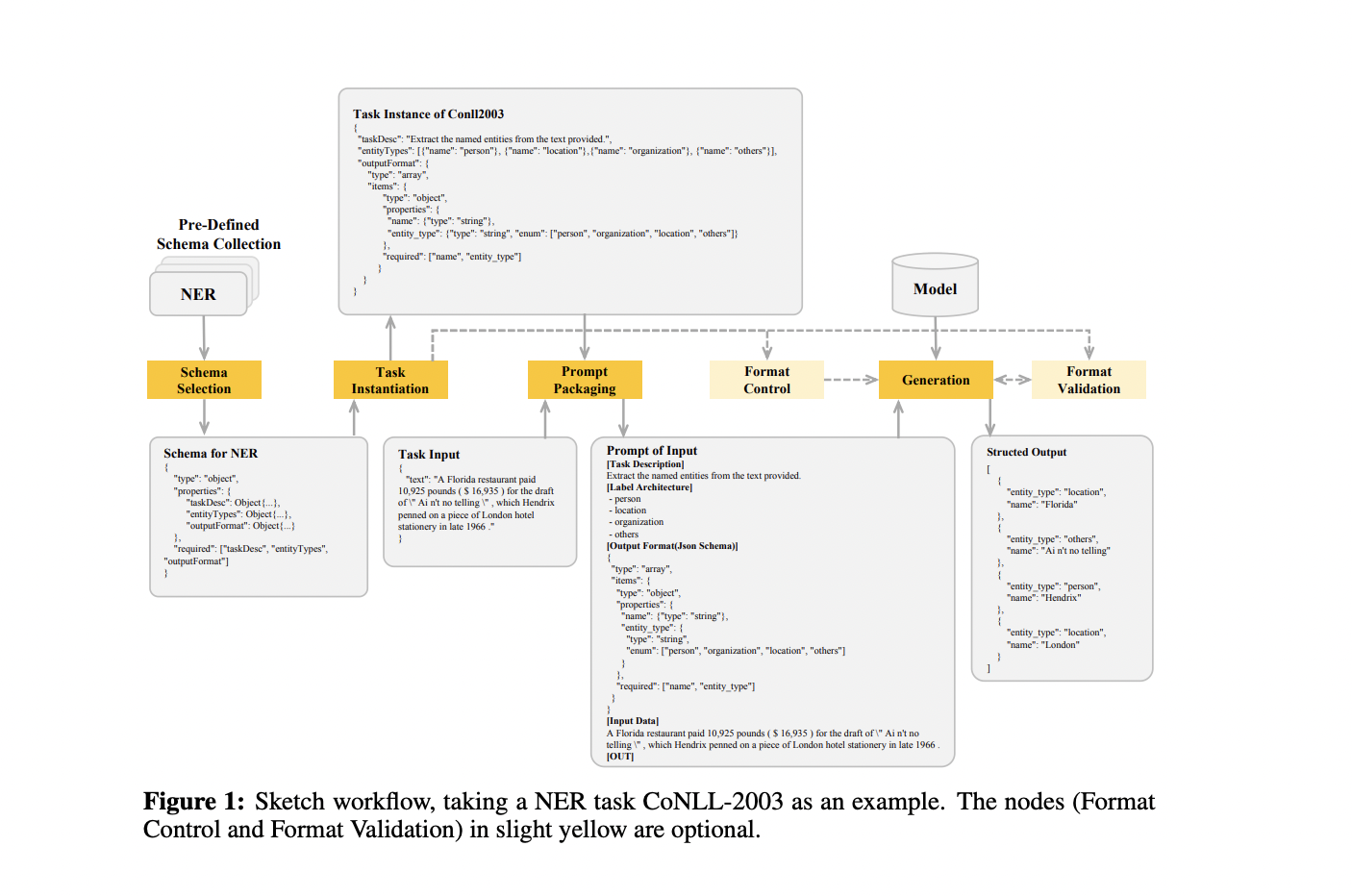
Sketch’s architecture comprises four key steps: schema selection, task instantiation, prompt packaging, and generation. Users first choose an appropriate schema from a predefined set aligned with their NLP task requirements. During task instantiation, users populate the chosen schema with task-specific details, creating a JSON-format task instance. The prompt packaging step automatically converts the task input into a structured prompt for LLM interaction, integrating task description, label architecture, output format, and input data.

In the generation phase, Sketch can directly produce responses or employ more precise control methods. It optionally integrates the lm-format-enforcer, using context-free grammar to ensure output format compliance. In addition to that, Sketch uses the JSON-schema tool for output validation, resampling or throwing exceptions for non-compliant outputs. This architecture enables controlled formatting and easy interaction with LLMs across various NLP tasks, streamlining the process for users while maintaining output accuracy and format consistency.

Sketch-8B enhances LLaMA3-8B-Instruct’s ability to generate structured data adhering to JSON schema constraints across various tasks. The fine-tuning process focuses on two key aspects: ensuring strict adherence to JSON schema constraints and fostering robust task generalization. To achieve this, two targeted datasets are constructed: NLP task data and schema following data.
The NLP task data comprises over 20 datasets covering text classification, text generation, and information extraction, with 53 task instances. The schema following data includes 20,000 pieces of fine-tuning data generated from 10,000 diverse JSON schemas. The fine-tuning method optimizes both format adherence and NLP task performance using a mixed dataset approach. The training objective is formulated as a log-probability maximization of the correct output sequence given the input prompt. This approach balances improving the model’s adherence to various output formats and enhancing its NLP task capabilities.
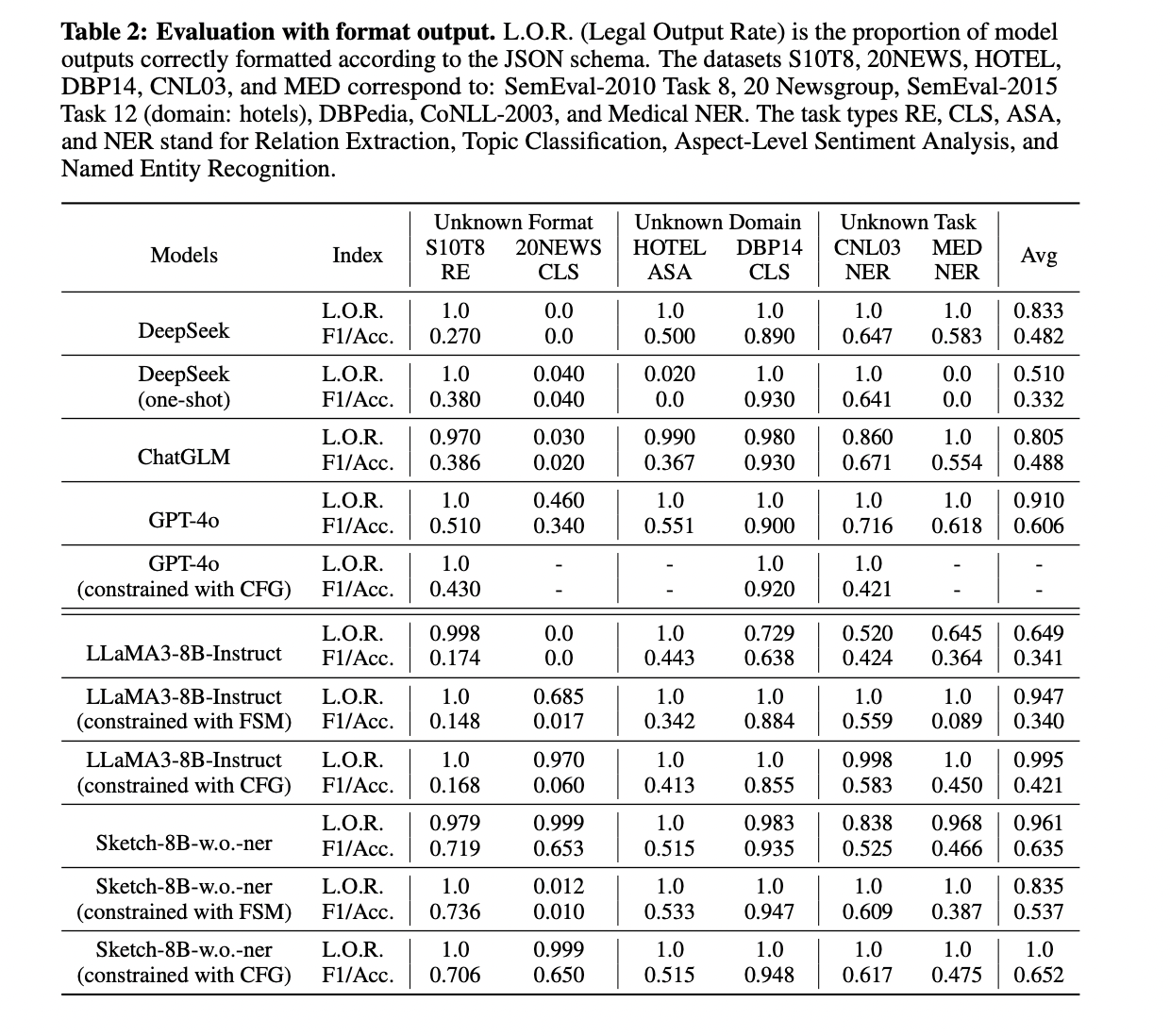
The evaluation of Sketch-8B-w.o.-ner demonstrates its strong generalization capabilities across unknown formats, domains, and tasks. In schema adherence, Sketch-8B-w.o.-ner achieves an average legal output ratio of 96.2% under unconstrained conditions, significantly outperforming the baseline LLaMA3-8B-Instruct’s 64.9%. This improvement is particularly notable in complex formats like 20NEWS, where Sketch-8B-w.o.-ner maintains high performance while LLaMA3-8B-Instruct completely fails.
Performance comparisons reveal that Sketch-8B-w.o.-ner consistently outperforms LLaMA3-8B-Instruct across various decoding strategies and datasets. Compared to mainstream models like DeepSeek, ChatGLM, and GPT-4o, Sketch-8B-w.o.-ner shows superior performance on unknown format datasets and comparable results on unknown domain datasets. However, it faces some limitations on unknown task datasets due to its smaller model size.
The evaluation also highlights the inconsistent effects of constrained decoding methods (FSM and CFG) on task performance. While these methods can improve legal output ratios, they don’t consistently enhance task evaluation scores, especially for datasets with complex output formats. This suggests that current constrained decoding approaches may not be uniformly reliable for real-world NLP applications.
This study introduces Sketch, a significant advancement in simplifying and optimizing the applications of large language models. By introducing a schema-based approach, it effectively addresses the challenges of structured output generation and model generalization. The framework’s key innovations include a comprehensive schema architecture for task description, a robust data preparation and model fine-tuning strategy for enhanced performance, and the integration of a constrained decoding framework for precise output control.
Experimental results convincingly demonstrate the superiority of the fine-tuned Sketch-8B model in adhering to specified output formats across various tasks. The effectiveness of the custom-built fine-tuning dataset, particularly the schema following data, is evident in the model’s improved performance. Sketch not only enhances the practical applicability of LLMs but also paves the way for more reliable and format-compliant outputs in diverse NLP tasks, marking a substantial step forward in making LLMs more accessible and effective for real-world applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit

The post Sketch: An Innovative AI Toolkit Designed to Streamline LLM Operations Across Diverse Fields appeared first on MarkTechPost.
